 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosing the Gap: Achieving Better Accuracy-Robustness Tradeoffs Against Query-Based Attacks
Dec 15, 2023Although promising, existing defenses against query-based attacks share a common limitation: they offer increased robustness against attacks at the price of a considerable accuracy drop on clean samples. In this work, we show how to efficiently establish, at test-time, a solid tradeoff between robustness and accuracy when mitigating query-based attacks. Given that these attacks necessarily explore low-confidence regions, our insight is that activating dedicated defenses, such as RND (Qin et al., NeuRIPS 2021) and Random Image Transformations (Xie et al., ICLR 2018), only for low-confidence inputs is sufficient to prevent them. Our approach is independent of training and supported by theory. We verify the effectiveness of our approach for various existing defenses by conducting extensive experiments on CIFAR-10, CIFAR-100, and ImageNet. Our results confirm that our proposal can indeed enhance these defenses by providing better tradeoffs between robustness and accuracy when compared to state-of-the-art approaches while being completely training-free.
BaFFLe: Backdoor detection via Feedback-based Federated Learning
Nov 04, 2020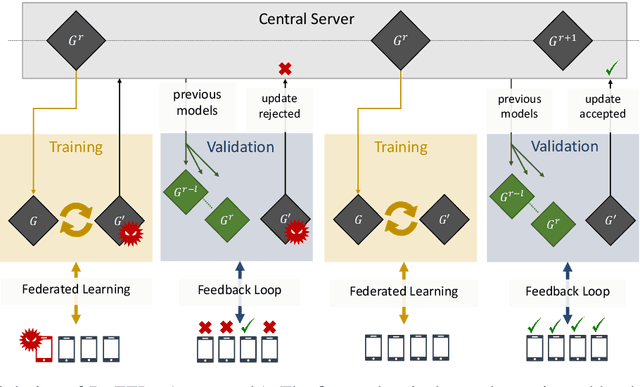
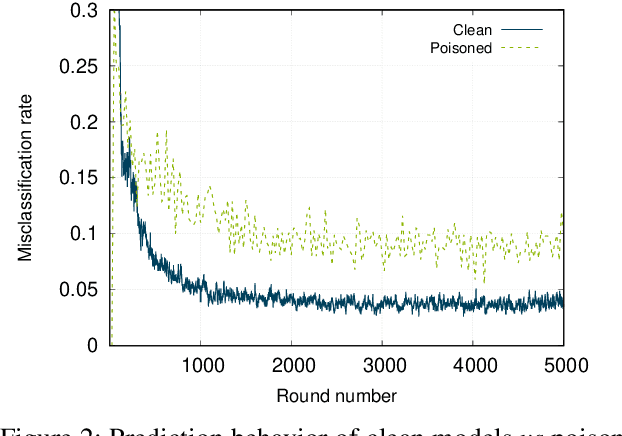
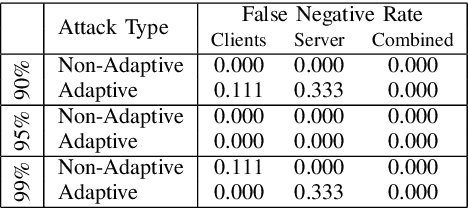
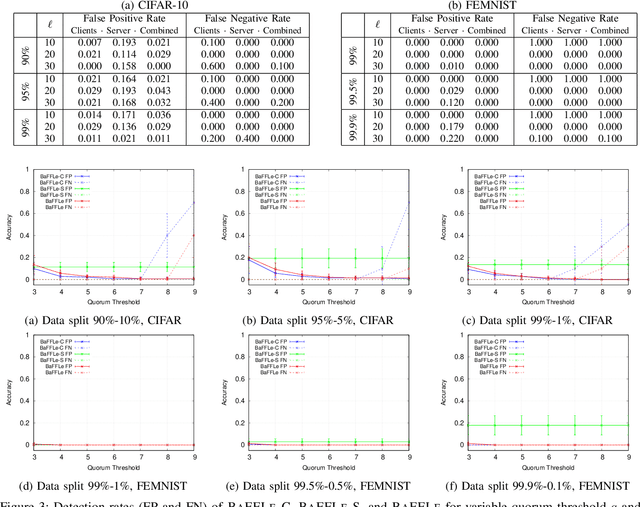
Recent studies have shown that federated learning (FL) is vulnerable to poisoning attacks which aim at injecting a backdoor into the global model. These attacks are effective, even when performed by a single client, and undetectable by most existing defensive techniques. In this paper, we propose a novel defense, dubbed BaFFLe---Backdoor detection via Feedback-based Federated Learning---to secure FL against backdoor attacks. The core idea behind BaFFLe is to leverage data of multiple clients not only for training but also for uncovering model poisoning. Namely, we exploit the availability of multiple, rich datasets at the various clients by incorporating a feedback loop into the FL process to integrate the views of those clients when deciding whether a given model update is genuine or not. We show that this powerful construct can achieve very high detection rates against state-of-the-art backdoor attacks, even when relying on straightforward methods to validate the model. Namely, we show by means of evaluation using the CIFAR-10 and FEMNIST datasets that, by combining the feedback loop with a method that suspects poisoning attempts by assessing the per-class classification performance of the updated model, BaFFLe reliably detects state-of-the-art semantic-backdoor attacks with a detection accuracy of 100% and a false-positive rate below 5%. Moreover, we show that our solution can detect an adaptive attack which is tuned to bypass the defense.