 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIPSv2: Advancing Vision-Language Pretraining with Enhanced Patch-Text Alignment
Apr 13, 2026Recent progress in vision-language pretraining has enabled significant improvements to many downstream computer vision applications, such as classification, retrieval, segmentation and depth prediction. However, a fundamental capability that these models still struggle with is aligning dense patch representations with text embeddings of corresponding concepts. In this work, we investigate this critical issue and propose novel techniques to enhance this capability in foundational vision-language models. First, we reveal that a patch-level distillation procedure significantly boosts dense patch-text alignment -- surprisingly, the patch-text alignment of the distilled student model strongly surpasses that of the teacher model. This observation inspires us to consider modifications to pretraining recipes, leading us to propose iBOT++, an upgrade to the commonly-used iBOT masked image objective, where unmasked tokens also contribute directly to the loss. This dramatically enhances patch-text alignment of pretrained models. Additionally, to improve vision-language pretraining efficiency and effectiveness, we modify the exponential moving average setup in the learning recipe, and introduce a caption sampling strategy to benefit from synthetic captions at different granularities. Combining these components, we develop TIPSv2, a new family of image-text encoder models suitable for a wide range of downstream applications. Through comprehensive experiments on 9 tasks and 20 datasets, we demonstrate strong performance, generally on par with or better than recent vision encoder models. Code and models are released via our project page at https://gdm-tipsv2.github.io/ .
UDON: Universal Dynamic Online distillatioN for generic image representations
Jun 12, 2024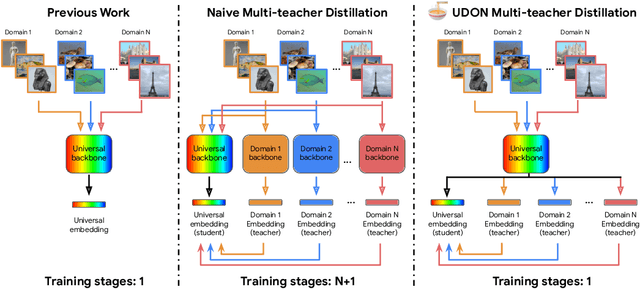

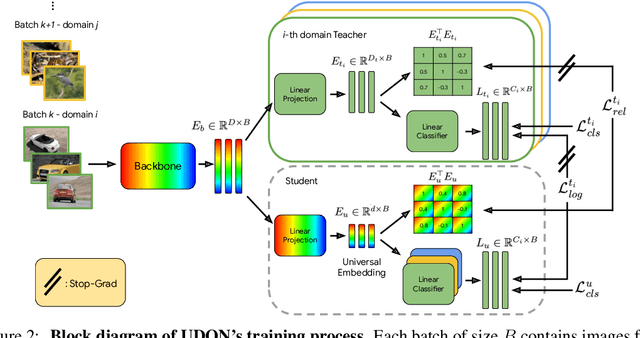
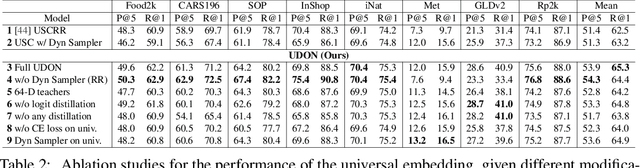
Universal image representations are critical in enabling real-world fine-grained and instance-level recognition applications, where objects and entities from any domain must be identified at large scale. Despite recent advances, existing methods fail to capture important domain-specific knowledge, while also ignoring differences in data distribution across different domains. This leads to a large performance gap between efficient universal solutions and expensive approaches utilising a collection of specialist models, one for each domain. In this work, we make significant strides towards closing this gap, by introducing a new learning technique, dubbed UDON (Universal Dynamic Online DistillatioN). UDON employs multi-teacher distillation, where each teacher is specialized in one domain, to transfer detailed domain-specific knowledge into the student universal embedding. UDON's distillation approach is not only effective, but also very efficient, by sharing most model parameters between the student and all teachers, where all models are jointly trained in an online manner. UDON also comprises a sampling technique which adapts the training process to dynamically allocate batches to domains which are learned slower and require more frequent processing. This boosts significantly the learning of complex domains which are characterised by a large number of classes and long-tail distributions. With comprehensive experiments, we validate each component of UDON, and showcase significant improvements over the state of the art in the recent UnED benchmark. Code: https://github.com/nikosips/UDON .
Optimization of Rank Losses for Image Retrieval
Sep 15, 2023In image retrieval, standard evaluation metrics rely on score ranking, \eg average precision (AP), recall at k (R@k), normalized discounted cumulative gain (NDCG). In this work we introduce a general framework for robust and decomposable rank losses optimization. It addresses two major challenges for end-to-end training of deep neural networks with rank losses: non-differentiability and non-decomposability. Firstly we propose a general surrogate for ranking operator, SupRank, that is amenable to stochastic gradient descent. It provides an upperbound for rank losses and ensures robust training. Secondly, we use a simple yet effective loss function to reduce the decomposability gap between the averaged batch approximation of ranking losses and their values on the whole training set. We apply our framework to two standard metrics for image retrieval: AP and R@k. Additionally we apply our framework to hierarchical image retrieval. We introduce an extension of AP, the hierarchical average precision $\mathcal{H}$-AP, and optimize it as well as the NDCG. Finally we create the first hierarchical landmarks retrieval dataset. We use a semi-automatic pipeline to create hierarchical labels, extending the large scale Google Landmarks v2 dataset. The hierarchical dataset is publicly available at https://github.com/cvdfoundation/google-landmark. Code will be released at https://github.com/elias-ramzi/SupRank.
Towards Universal Image Embeddings: A Large-Scale Dataset and Challenge for Generic Image Representations
Sep 04, 2023Fine-grained and instance-level recognition methods are commonly trained and evaluated on specific domains, in a model per domain scenario. Such an approach, however, is impractical in real large-scale applications. In this work, we address the problem of universal image embedding, where a single universal model is trained and used in multiple domains. First, we leverage existing domain-specific datasets to carefully construct a new large-scale public benchmark for the evaluation of universal image embeddings, with 241k query images, 1.4M index images and 2.8M training images across 8 different domains and 349k classes. We define suitable metrics, training and evaluation protocols to foster future research in this area. Second, we provide a comprehensive experimental evaluation on the new dataset, demonstrating that existing approaches and simplistic extensions lead to worse performance than an assembly of models trained for each domain separately. Finally, we conducted a public research competition on this topic, leveraging industrial datasets, which attracted the participation of more than 1k teams worldwide. This exercise generated many interesting research ideas and findings which we present in detail. Project webpage: https://cmp.felk.cvut.cz/univ_emb/
NAVI: Category-Agnostic Image Collections with High-Quality 3D Shape and Pose Annotations
Jun 15, 2023



Recent advances in neural reconstruction enable high-quality 3D object reconstruction from casually captured image collections. Current techniques mostly analyze their progress on relatively simple image collections where Structure-from-Motion (SfM) techniques can provide ground-truth (GT) camera poses. We note that SfM techniques tend to fail on in-the-wild image collections such as image search results with varying backgrounds and illuminations. To enable systematic research progress on 3D reconstruction from casual image captures, we propose NAVI: a new dataset of category-agnostic image collections of objects with high-quality 3D scans along with per-image 2D-3D alignments providing near-perfect GT camera parameters. These 2D-3D alignments allow us to extract accurate derivative annotations such as dense pixel correspondences, depth and segmentation maps. We demonstrate the use of NAVI image collections on different problem settings and show that NAVI enables more thorough evaluations that were not possible with existing datasets. We believe NAVI is beneficial for systematic research progress on 3D reconstruction and correspondence estimation. Project page: https://navidataset.github.io
Encyclopedic VQA: Visual questions about detailed properties of fine-grained categories
Jun 15, 2023We propose Encyclopedic-VQA, a large scale visual question answering (VQA) dataset featuring visual questions about detailed properties of fine-grained categories and instances. It contains 221k unique question+answer pairs each matched with (up to) 5 images, resulting in a total of 1M VQA samples. Moreover, our dataset comes with a controlled knowledge base derived from Wikipedia, marking the evidence to support each answer. Empirically, we show that our dataset poses a hard challenge for large vision+language models as they perform poorly on our dataset: PaLI [14] is state-of-the-art on OK-VQA [37], yet it only achieves 13.0% accuracy on our dataset. Moreover, we experimentally show that progress on answering our encyclopedic questions can be achieved by augmenting large models with a mechanism that retrieves relevant information from the knowledge base. An oracle experiment with perfect retrieval achieves 87.0% accuracy on the single-hop portion of our dataset, and an automatic retrieval-augmented prototype yields 48.8%. We believe that our dataset enables future research on retrieval-augmented vision+language models.
Yes, we CANN: Constrained Approximate Nearest Neighbors for local feature-based visual localization
Jun 15, 2023Large-scale visual localization systems continue to rely on 3D point clouds built from image collections using structure-from-motion. While the 3D points in these models are represented using local image features, directly matching a query image's local features against the point cloud is challenging due to the scale of the nearest-neighbor search problem. Many recent approaches to visual localization have thus proposed a hybrid method, where first a global (per image) embedding is used to retrieve a small subset of database images, and local features of the query are matched only against those. It seems to have become common belief that global embeddings are critical for said image-retrieval in visual localization, despite the significant downside of having to compute two feature types for each query image. In this paper, we take a step back from this assumption and propose Constrained Approximate Nearest Neighbors (CANN), a joint solution of k-nearest-neighbors across both the geometry and appearance space using only local features. We first derive the theoretical foundation for k-nearest-neighbor retrieval across multiple metrics and then showcase how CANN improves visual localization. Our experiments on public localization benchmarks demonstrate that our method significantly outperforms both state-of-the-art global feature-based retrieval and approaches using local feature aggregation schemes. Moreover, it is an order of magnitude faster in both index and query time than feature aggregation schemes for these datasets. Code will be released.
Improving Fairness in Large-Scale Object Recognition by CrowdSourced Demographic Information
Jun 02, 2022

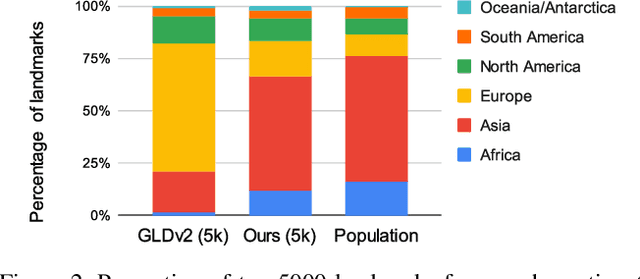
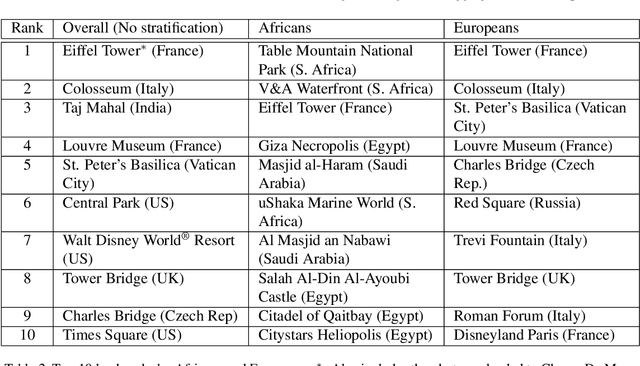
There has been increasing awareness of ethical issues in machine learning, and fairness has become an important research topic. Most fairness efforts in computer vision have been focused on human sensing applications and preventing discrimination by people's physical attributes such as race, skin color or age by increasing visual representation for particular demographic groups. We argue that ML fairness efforts should extend to object recognition as well. Buildings, artwork, food and clothing are examples of the objects that define human culture. Representing these objects fairly in machine learning datasets will lead to models that are less biased towards a particular culture and more inclusive of different traditions and values. There exist many research datasets for object recognition, but they have not carefully considered which classes should be included, or how much training data should be collected per class. To address this, we propose a simple and general approach, based on crowdsourcing the demographic composition of the contributors: we define fair relevance scores, estimate them, and assign them to each class. We showcase its application to the landmark recognition domain, presenting a detailed analysis and the final fairer landmark rankings. We present analysis which leads to a much fairer coverage of the world compared to existing datasets. The evaluation dataset was used for the 2021 Google Landmark Challenges, which was the first of a kind with an emphasis on fairness in generic object recognition.
Towards A Fairer Landmark Recognition Dataset
Aug 19, 2021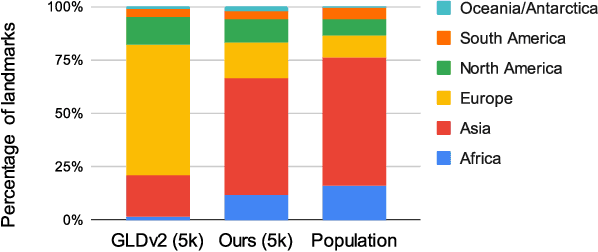
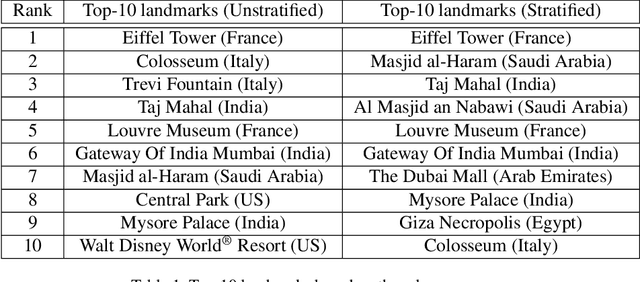
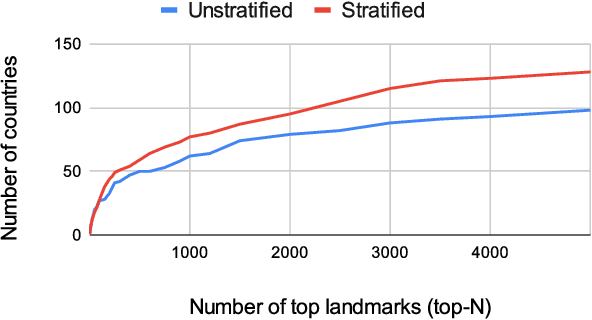

We introduce a new landmark recognition dataset, which is created with a focus on fair worldwide representation. While previous work proposes to collect as many images as possible from web repositories, we instead argue that such approaches can lead to biased data. To create a more comprehensive and equitable dataset, we start by defining the fair relevance of a landmark to the world population. These relevances are estimated by combining anonymized Google Maps user contribution statistics with the contributors' demographic information. We present a stratification approach and analysis which leads to a much fairer coverage of the world, compared to existing datasets. The resulting datasets are used to evaluate computer vision models as part of the the Google Landmark Recognition and RetrievalChallenges 2021.
Class-Balanced Distillation for Long-Tailed Visual Recognition
Apr 12, 2021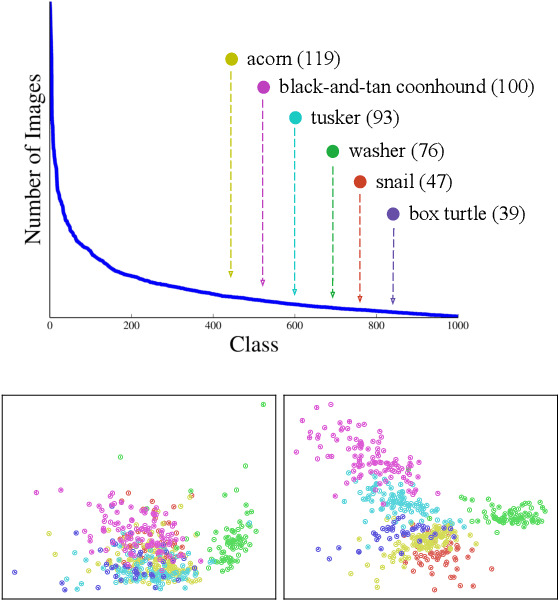

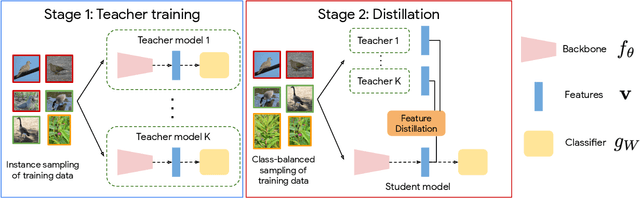
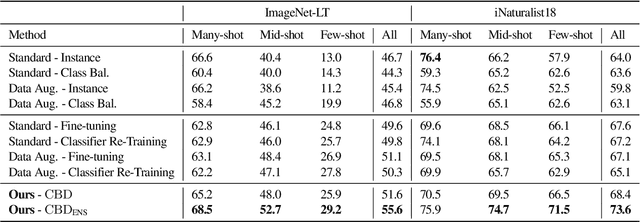
Real-world imagery is often characterized by a significant imbalance of the number of images per class, leading to long-tailed distributions. An effective and simple approach to long-tailed visual recognition is to learn feature representations and a classifier separately, with instance and class-balanced sampling, respectively. In this work, we introduce a new framework, by making the key observation that a feature representation learned with instance sampling is far from optimal in a long-tailed setting. Our main contribution is a new training method, referred to as Class-Balanced Distillation (CBD), that leverages knowledge distillation to enhance feature representations. CBD allows the feature representation to evolve in the second training stage, guided by the teacher learned in the first stage. The second stage uses class-balanced sampling, in order to focus on under-represented classes. This framework can naturally accommodate the usage of multiple teachers, unlocking the information from an ensemble of models to enhance recognition capabilities. Our experiments show that the proposed technique consistently outperforms the state of the art on long-tailed recognition benchmarks such as ImageNet-LT, iNaturalist17 and iNaturalist18. The experiments also show that our method does not sacrifice the accuracy of head classes to improve the performance of tail classes, unlike most existing work.