 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Universal Image Embeddings: A Large-Scale Dataset and Challenge for Generic Image Representations
Sep 04, 2023Fine-grained and instance-level recognition methods are commonly trained and evaluated on specific domains, in a model per domain scenario. Such an approach, however, is impractical in real large-scale applications. In this work, we address the problem of universal image embedding, where a single universal model is trained and used in multiple domains. First, we leverage existing domain-specific datasets to carefully construct a new large-scale public benchmark for the evaluation of universal image embeddings, with 241k query images, 1.4M index images and 2.8M training images across 8 different domains and 349k classes. We define suitable metrics, training and evaluation protocols to foster future research in this area. Second, we provide a comprehensive experimental evaluation on the new dataset, demonstrating that existing approaches and simplistic extensions lead to worse performance than an assembly of models trained for each domain separately. Finally, we conducted a public research competition on this topic, leveraging industrial datasets, which attracted the participation of more than 1k teams worldwide. This exercise generated many interesting research ideas and findings which we present in detail. Project webpage: https://cmp.felk.cvut.cz/univ_emb/
SwissDial: Parallel Multidialectal Corpus of Spoken Swiss German
Mar 21, 2021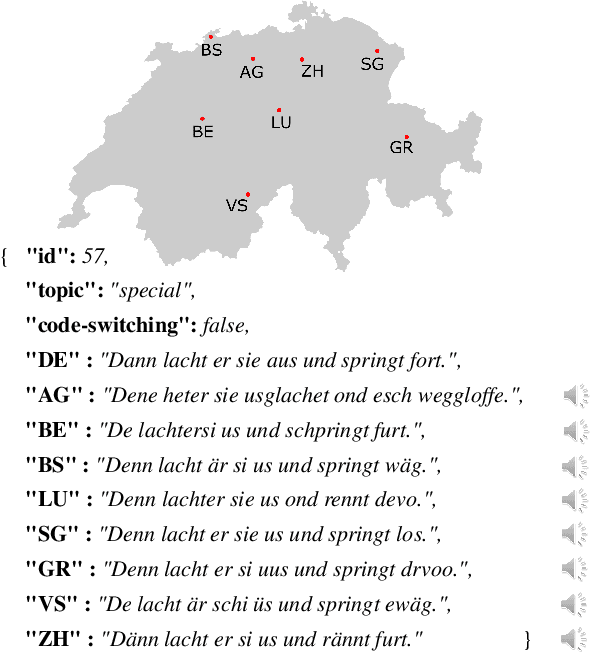
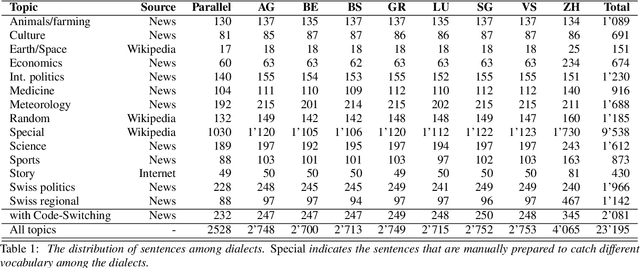
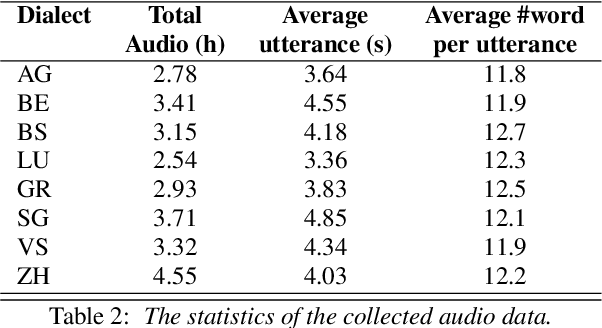

Swiss German is a dialect continuum whose natively acquired dialects significantly differ from the formal variety of the language. These dialects are mostly used for verbal communication and do not have standard orthography. This has led to a lack of annotated datasets, rendering the use of many NLP methods infeasible. In this paper, we introduce the first annotated parallel corpus of spoken Swiss German across 8 major dialects, plus a Standard German reference. Our goal has been to create and to make available a basic dataset for employing data-driven NLP applications in Swiss German. We present our data collection procedure in detail and validate the quality of our corpus by conducting experiments with the recent neural models for speech synthesis.