 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwissDial: Parallel Multidialectal Corpus of Spoken Swiss German
Paper and Code
Mar 21, 2021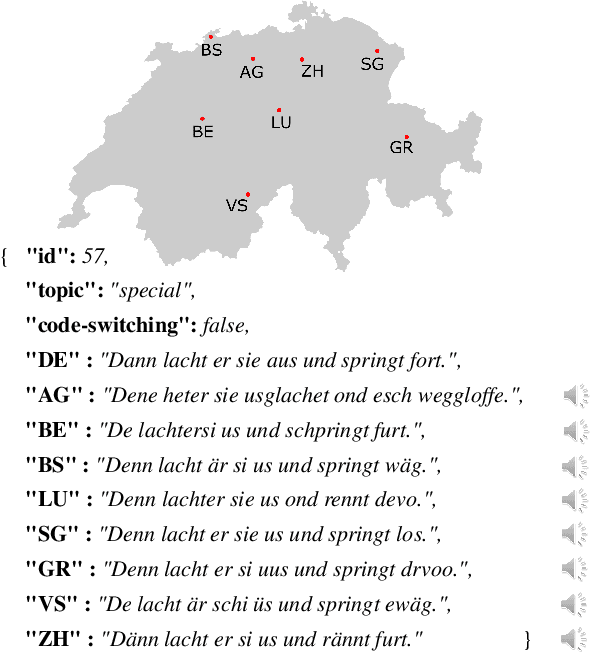
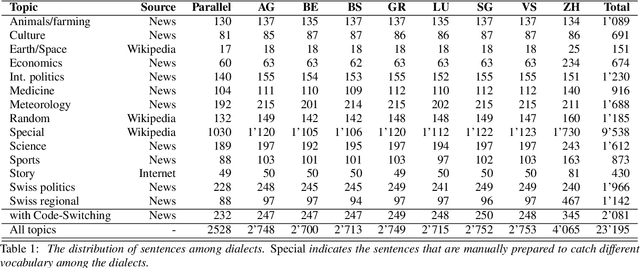
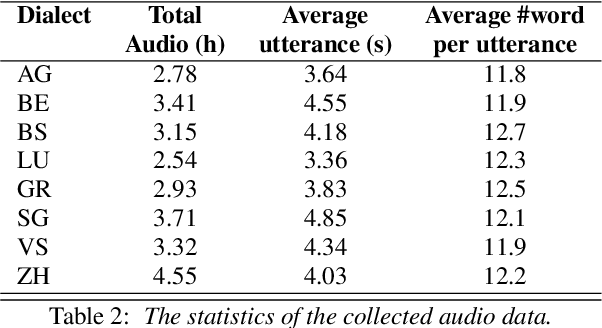

Swiss German is a dialect continuum whose natively acquired dialects significantly differ from the formal variety of the language. These dialects are mostly used for verbal communication and do not have standard orthography. This has led to a lack of annotated datasets, rendering the use of many NLP methods infeasible. In this paper, we introduce the first annotated parallel corpus of spoken Swiss German across 8 major dialects, plus a Standard German reference. Our goal has been to create and to make available a basic dataset for employing data-driven NLP applications in Swiss German. We present our data collection procedure in detail and validate the quality of our corpus by conducting experiments with the recent neural models for speech synthesis.