 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCURVE: A Benchmark for Cultural and Multilingual Long Video Reasoning
Jan 15, 2026Recent advancements in video models have shown tremendous progress, particularly in long video understanding. However, current benchmarks predominantly feature western-centric data and English as the dominant language, introducing significant biases in evaluation. To address this, we introduce CURVE (Cultural Understanding and Reasoning in Video Evaluation), a challenging benchmark for multicultural and multilingual video reasoning. CURVE comprises high-quality, entirely human-generated annotations from diverse, region-specific cultural videos across 18 global locales. Unlike prior work that relies on automatic translations, CURVE provides complex questions, answers, and multi-step reasoning steps, all crafted in native languages. Making progress on CURVE requires a deeply situated understanding of visual cultural context. Furthermore, we leverage CURVE's reasoning traces to construct evidence-based graphs and propose a novel iterative strategy using these graphs to identify fine-grained errors in reasoning. Our evaluations reveal that SoTA Video-LLMs struggle significantly, performing substantially below human-level accuracy, with errors primarily stemming from the visual perception of cultural elements. CURVE will be publicly available under https://github.com/google-deepmind/neptune?tab=readme-ov-file\#minerva-cultural
CAViAR: Critic-Augmented Video Agentic Reasoning
Sep 09, 2025Video understanding has seen significant progress in recent years, with models' performance on perception from short clips continuing to rise. Yet, multiple recent benchmarks, such as LVBench, Neptune, and ActivityNet-RTL, show performance wanes for tasks requiring complex reasoning on videos as queries grow more complex and videos grow longer. In this work, we ask: can existing perception capabilities be leveraged to successfully perform more complex video reasoning? In particular, we develop a large language model agent given access to video modules as subagents or tools. Rather than following a fixed procedure to solve queries as in previous work such as Visual Programming, ViperGPT, and MoReVQA, the agent uses the results of each call to a module to determine subsequent steps. Inspired by work in the textual reasoning domain, we introduce a critic to distinguish between instances of successful and unsuccessful sequences from the agent. We show that the combination of our agent and critic achieve strong performance on the previously-mentioned datasets.
MINERVA: Evaluating Complex Video Reasoning
May 01, 2025Multimodal LLMs are turning their focus to video benchmarks, however most video benchmarks only provide outcome supervision, with no intermediate or interpretable reasoning steps. This makes it challenging to assess if models are truly able to combine perceptual and temporal information to reason about videos, or simply get the correct answer by chance or by exploiting linguistic biases. To remedy this, we provide a new video reasoning dataset called MINERVA for modern multimodal models. Each question in the dataset comes with 5 answer choices, as well as detailed, hand-crafted reasoning traces. Our dataset is multimodal, diverse in terms of video domain and length, and consists of complex multi-step questions. Extensive benchmarking shows that our dataset provides a challenge for frontier open-source and proprietary models. We perform fine-grained error analysis to identify common failure modes across various models, and create a taxonomy of reasoning errors. We use this to explore both human and LLM-as-a-judge methods for scoring video reasoning traces, and find that failure modes are primarily related to temporal localization, followed by visual perception errors, as opposed to logical or completeness errors. The dataset, along with questions, answer candidates and reasoning traces will be publicly available under https://github.com/google-deepmind/neptune?tab=readme-ov-file\#minerva.
Neptune: The Long Orbit to Benchmarking Long Video Understanding
Dec 12, 2024



This paper describes a semi-automatic pipeline to generate challenging question-answer-decoy sets for understanding long videos. Many existing video datasets and models are focused on short clips (10s-30s). While some long video datasets do exist, they can often be solved by powerful image models applied per frame (and often to very few frames) in a video, and are usually manually annotated at high cost. In order to mitigate both these problems, we propose a scalable dataset creation pipeline which leverages large models (VLMs and LLMs), to automatically generate dense, time-aligned video captions, as well as tough question answer decoy sets for video segments (up to 15 minutes in length). Our dataset Neptune covers a broad range of long video reasoning abilities and consists of a subset that emphasizes multimodal reasoning. Since existing metrics for open-ended question answering are either rule-based or may rely on proprietary models, we provide a new open source model-based metric GEM to score open-ended responses on Neptune. Benchmark evaluations reveal that most current open-source long video models perform poorly on Neptune, particularly on questions testing temporal ordering, counting and state changes. Through Neptune, we aim to spur the development of more advanced models capable of understanding long videos. The dataset is available at https://github.com/google-deepmind/neptune
Extending Video Masked Autoencoders to 128 frames
Nov 20, 2024



Video understanding has witnessed significant progress with recent video foundation models demonstrating strong performance owing to self-supervised pre-training objectives; Masked Autoencoders (MAE) being the design of choice. Nevertheless, the majority of prior works that leverage MAE pre-training have focused on relatively short video representations (16 / 32 frames in length) largely due to hardware memory and compute limitations that scale poorly with video length due to the dense memory-intensive self-attention decoding. One natural strategy to address these challenges is to subsample tokens to reconstruct during decoding (or decoder masking). In this work, we propose an effective strategy for prioritizing tokens which allows training on longer video sequences (128 frames) and gets better performance than, more typical, random and uniform masking strategies. The core of our approach is an adaptive decoder masking strategy that prioritizes the most important tokens and uses quantized tokens as reconstruction objectives. Our adaptive strategy leverages a powerful MAGVIT-based tokenizer that jointly learns the tokens and their priority. We validate our design choices through exhaustive ablations and observe improved performance of the resulting long-video (128 frames) encoders over short-video (32 frames) counterparts. With our long-video masked autoencoder (LVMAE) strategy, we surpass state-of-the-art on Diving48 by 3.9 points and EPIC-Kitchens-100 verb classification by 2.5 points while relying on a simple core architecture and video-only pre-training (unlike some of the prior works that require millions of labeled video-text pairs or specialized encoders).
VideoPrism: A Foundational Visual Encoder for Video Understanding
Feb 20, 2024
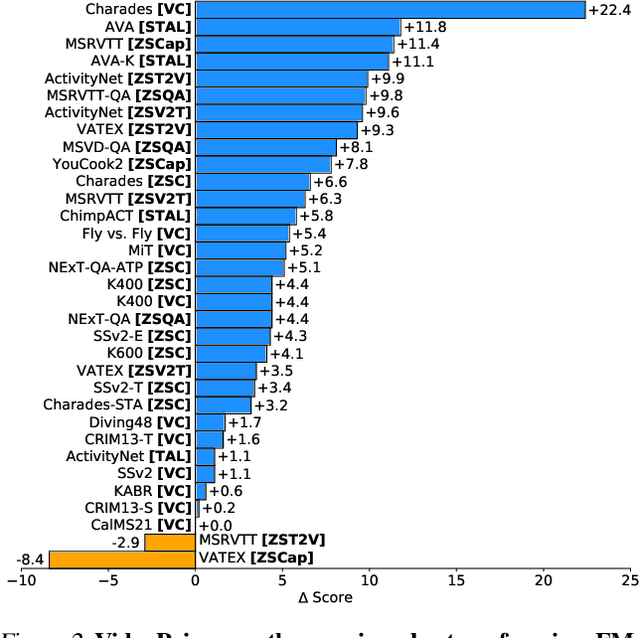
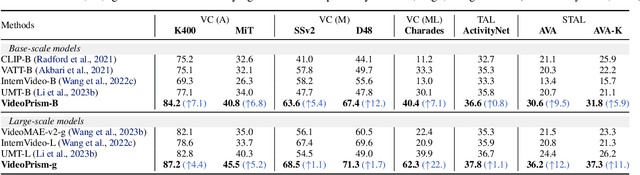
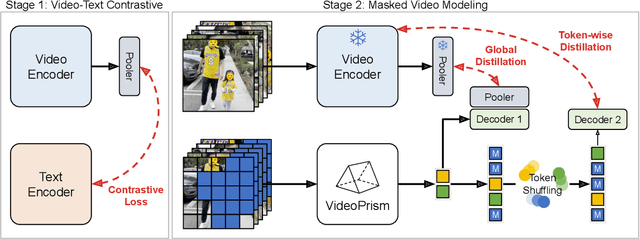
We introduce VideoPrism, a general-purpose video encoder that tackles diverse video understanding tasks with a single frozen model. We pretrain VideoPrism on a heterogeneous corpus containing 36M high-quality video-caption pairs and 582M video clips with noisy parallel text (e.g., ASR transcripts). The pretraining approach improves upon masked autoencoding by global-local distillation of semantic video embeddings and a token shuffling scheme, enabling VideoPrism to focus primarily on the video modality while leveraging the invaluable text associated with videos. We extensively test VideoPrism on four broad groups of video understanding tasks, from web video question answering to CV for science, achieving state-of-the-art performance on 30 out of 33 video understanding benchmarks.
VideoGLUE: Video General Understanding Evaluation of Foundation Models
Jul 06, 2023



We evaluate existing foundation models video understanding capabilities using a carefully designed experiment protocol consisting of three hallmark tasks (action recognition, temporal localization, and spatiotemporal localization), eight datasets well received by the community, and four adaptation methods tailoring a foundation model (FM) for a downstream task. Moreover, we propose a scalar VideoGLUE score (VGS) to measure an FMs efficacy and efficiency when adapting to general video understanding tasks. Our main findings are as follows. First, task-specialized models significantly outperform the six FMs studied in this work, in sharp contrast to what FMs have achieved in natural language and image understanding. Second,video-native FMs, whose pretraining data contains the video modality, are generally better than image-native FMs in classifying motion-rich videos, localizing actions in time, and understanding a video of more than one action. Third, the video-native FMs can perform well on video tasks under light adaptations to downstream tasks(e.g., freezing the FM backbones), while image-native FMs win in full end-to-end finetuning. The first two observations reveal the need and tremendous opportunities to conduct research on video-focused FMs, and the last confirms that both tasks and adaptation methods matter when it comes to the evaluation of FMs.
Improving Fairness in Large-Scale Object Recognition by CrowdSourced Demographic Information
Jun 02, 2022

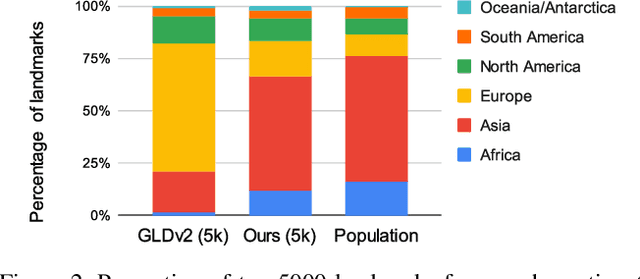
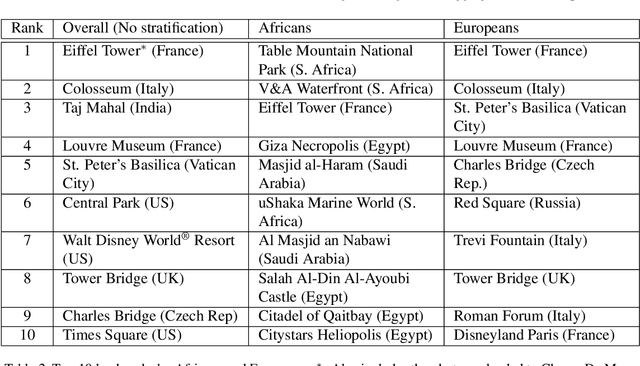
There has been increasing awareness of ethical issues in machine learning, and fairness has become an important research topic. Most fairness efforts in computer vision have been focused on human sensing applications and preventing discrimination by people's physical attributes such as race, skin color or age by increasing visual representation for particular demographic groups. We argue that ML fairness efforts should extend to object recognition as well. Buildings, artwork, food and clothing are examples of the objects that define human culture. Representing these objects fairly in machine learning datasets will lead to models that are less biased towards a particular culture and more inclusive of different traditions and values. There exist many research datasets for object recognition, but they have not carefully considered which classes should be included, or how much training data should be collected per class. To address this, we propose a simple and general approach, based on crowdsourcing the demographic composition of the contributors: we define fair relevance scores, estimate them, and assign them to each class. We showcase its application to the landmark recognition domain, presenting a detailed analysis and the final fairer landmark rankings. We present analysis which leads to a much fairer coverage of the world compared to existing datasets. The evaluation dataset was used for the 2021 Google Landmark Challenges, which was the first of a kind with an emphasis on fairness in generic object recognition.
Towards A Fairer Landmark Recognition Dataset
Aug 19, 2021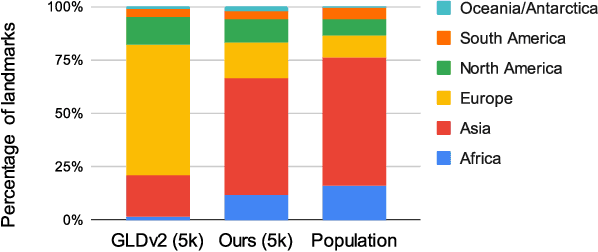
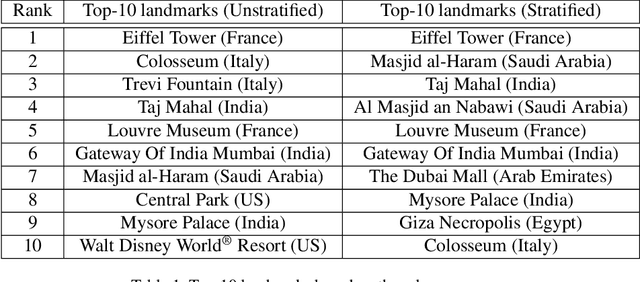
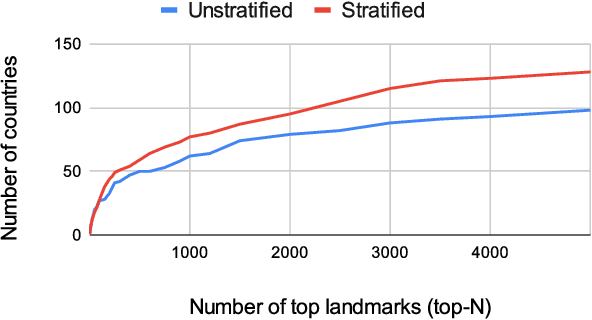

We introduce a new landmark recognition dataset, which is created with a focus on fair worldwide representation. While previous work proposes to collect as many images as possible from web repositories, we instead argue that such approaches can lead to biased data. To create a more comprehensive and equitable dataset, we start by defining the fair relevance of a landmark to the world population. These relevances are estimated by combining anonymized Google Maps user contribution statistics with the contributors' demographic information. We present a stratification approach and analysis which leads to a much fairer coverage of the world, compared to existing datasets. The resulting datasets are used to evaluate computer vision models as part of the the Google Landmark Recognition and RetrievalChallenges 2021.
Nutrition5k: Towards Automatic Nutritional Understanding of Generic Food
Mar 04, 2021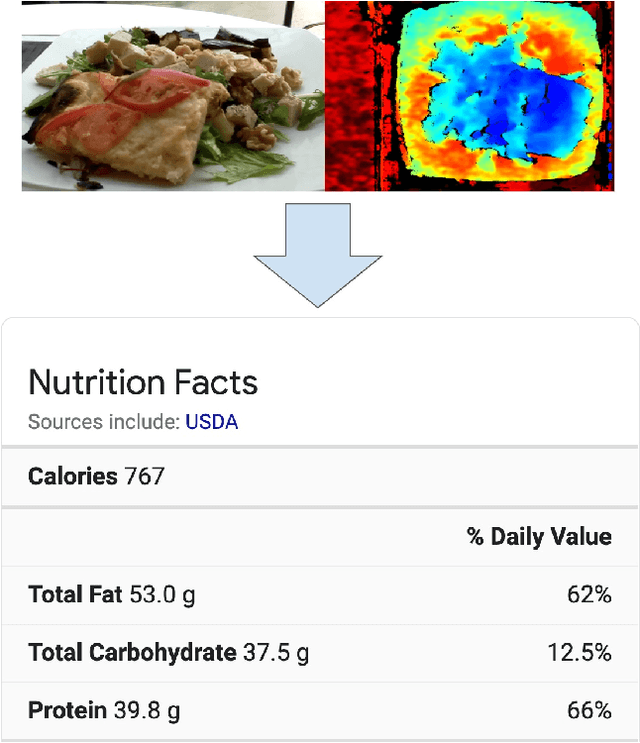
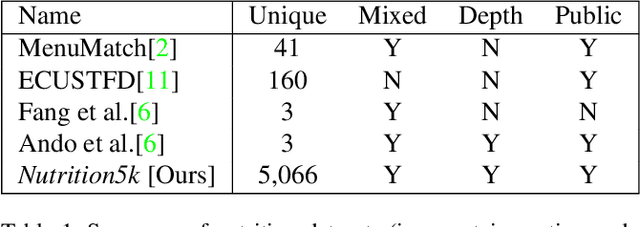

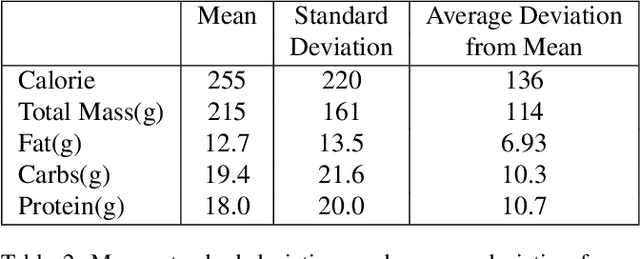
Understanding the nutritional content of food from visual data is a challenging computer vision problem, with the potential to have a positive and widespread impact on public health. Studies in this area are limited to existing datasets in the field that lack sufficient diversity or labels required for training models with nutritional understanding capability. We introduce Nutrition5k, a novel dataset of 5k diverse, real world food dishes with corresponding video streams, depth images, component weights, and high accuracy nutritional content annotation. We demonstrate the potential of this dataset by training a computer vision algorithm capable of predicting the caloric and macronutrient values of a complex, real world dish at an accuracy that outperforms professional nutritionists. Further we present a baseline for incorporating depth sensor data to improve nutrition predictions. We will publicly release Nutrition5k in the hope that it will accelerate innovation in the space of nutritional understanding.