 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNutrition5k: Towards Automatic Nutritional Understanding of Generic Food
Mar 04, 2021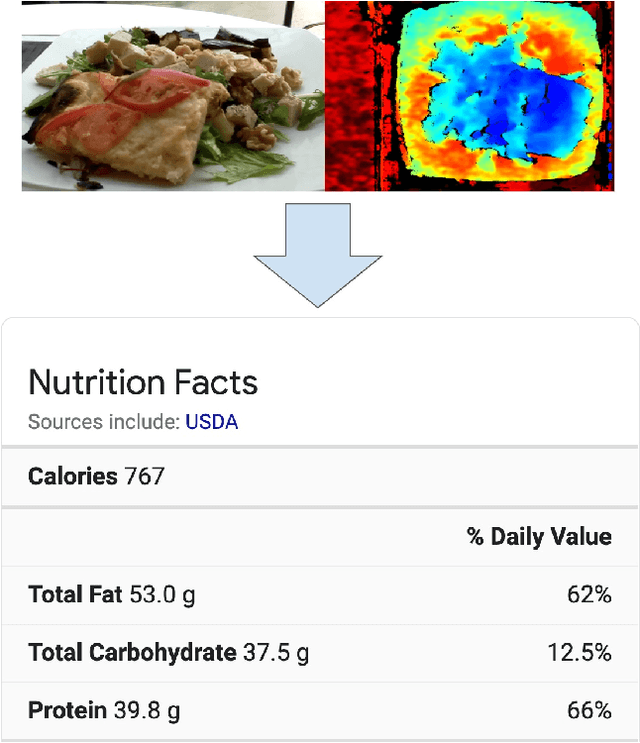
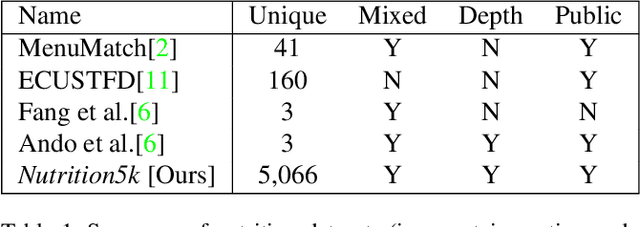

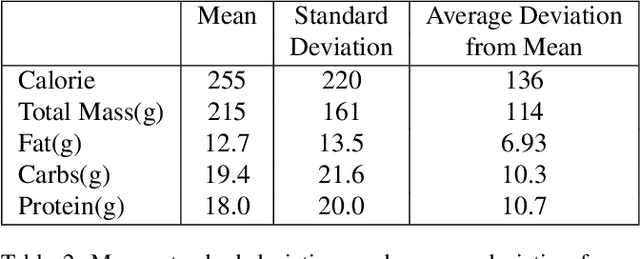
Understanding the nutritional content of food from visual data is a challenging computer vision problem, with the potential to have a positive and widespread impact on public health. Studies in this area are limited to existing datasets in the field that lack sufficient diversity or labels required for training models with nutritional understanding capability. We introduce Nutrition5k, a novel dataset of 5k diverse, real world food dishes with corresponding video streams, depth images, component weights, and high accuracy nutritional content annotation. We demonstrate the potential of this dataset by training a computer vision algorithm capable of predicting the caloric and macronutrient values of a complex, real world dish at an accuracy that outperforms professional nutritionists. Further we present a baseline for incorporating depth sensor data to improve nutrition predictions. We will publicly release Nutrition5k in the hope that it will accelerate innovation in the space of nutritional understanding.
Joint Multi-Person Pose Estimation and Semantic Part Segmentation
Aug 10, 2017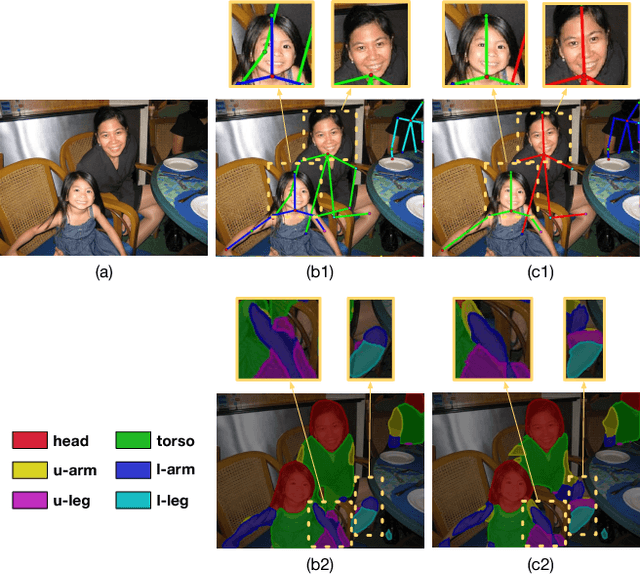
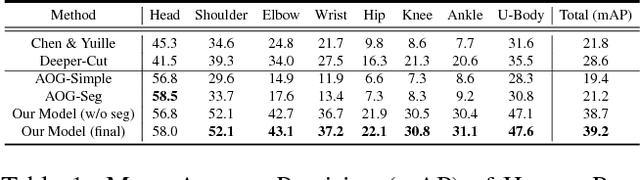


Human pose estimation and semantic part segmentation are two complementary tasks in computer vision. In this paper, we propose to solve the two tasks jointly for natural multi-person images, in which the estimated pose provides object-level shape prior to regularize part segments while the part-level segments constrain the variation of pose locations. Specifically, we first train two fully convolutional neural networks (FCNs), namely Pose FCN and Part FCN, to provide initial estimation of pose joint potential and semantic part potential. Then, to refine pose joint location, the two types of potentials are fused with a fully-connected conditional random field (FCRF), where a novel segment-joint smoothness term is used to encourage semantic and spatial consistency between parts and joints. To refine part segments, the refined pose and the original part potential are integrated through a Part FCN, where the skeleton feature from pose serves as additional regularization cues for part segments. Finally, to reduce the complexity of the FCRF, we induce human detection boxes and infer the graph inside each box, making the inference forty times faster. Since there's no dataset that contains both part segments and pose labels, we extend the PASCAL VOC part dataset with human pose joints and perform extensive experiments to compare our method against several most recent strategies. We show that on this dataset our algorithm surpasses competing methods by a large margin in both tasks.
Zoom Better to See Clearer: Human and Object Parsing with Hierarchical Auto-Zoom Net
Mar 28, 2016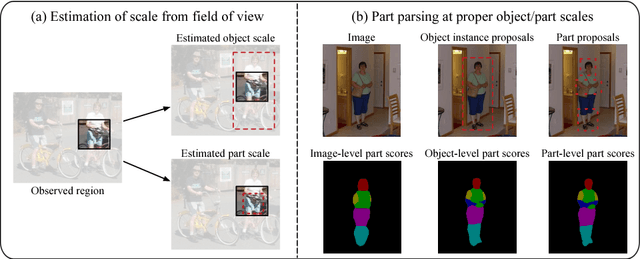
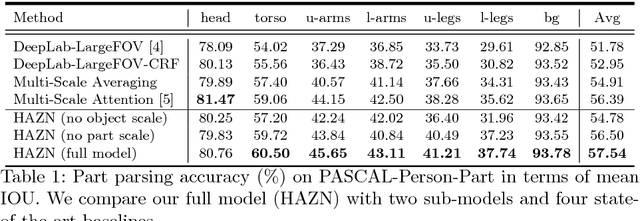
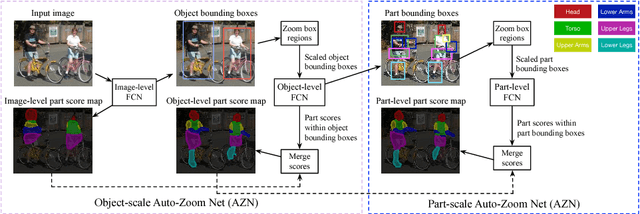
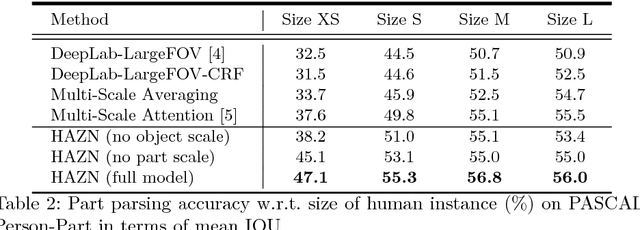
Parsing articulated objects, e.g. humans and animals, into semantic parts (e.g. body, head and arms, etc.) from natural images is a challenging and fundamental problem for computer vision. A big difficulty is the large variability of scale and location for objects and their corresponding parts. Even limited mistakes in estimating scale and location will degrade the parsing output and cause errors in boundary details. To tackle these difficulties, we propose a "Hierarchical Auto-Zoom Net" (HAZN) for object part parsing which adapts to the local scales of objects and parts. HAZN is a sequence of two "Auto-Zoom Net" (AZNs), each employing fully convolutional networks that perform two tasks: (1) predict the locations and scales of object instances (the first AZN) or their parts (the second AZN); (2) estimate the part scores for predicted object instance or part regions. Our model can adaptively "zoom" (resize) predicted image regions into their proper scales to refine the parsing. We conduct extensive experiments over the PASCAL part datasets on humans, horses, and cows. For humans, our approach significantly outperforms the state-of-the-arts by 5% mIOU and is especially better at segmenting small instances and small parts. We obtain similar improvements for parsing cows and horses over alternative methods. In summary, our strategy of first zooming into objects and then zooming into parts is very effective. It also enables us to process different regions of the image at different scales adaptively so that, for example, we do not need to waste computational resources scaling the entire image.
Pose-Guided Human Parsing with Deep Learned Features
Nov 25, 2015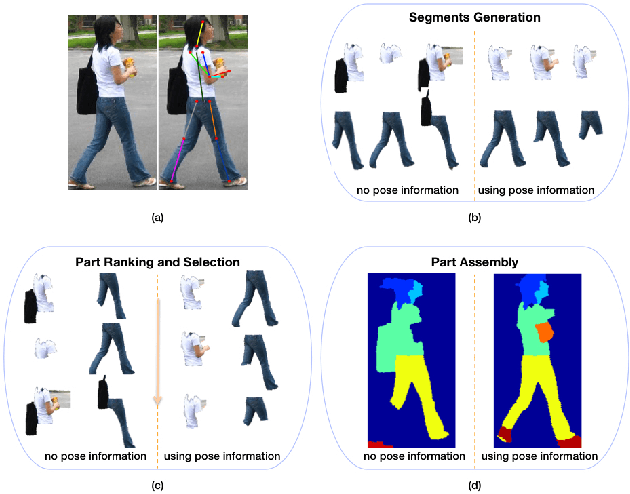

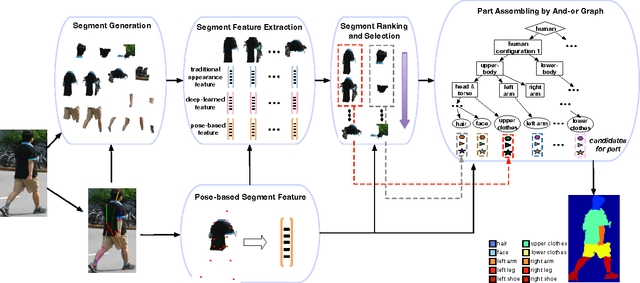

Parsing human body into semantic regions is crucial to human-centric analysis. In this paper, we propose a segment-based parsing pipeline that explores human pose information, i.e. the joint location of a human model, which improves the part proposal, accelerates the inference and regularizes the parsing process at the same time. Specifically, we first generate part segment proposals with respect to human joints predicted by a deep model, then part- specific ranking models are trained for segment selection using both pose-based features and deep-learned part potential features. Finally, the best ensemble of the proposed part segments are inferred though an And-Or Graph. We evaluate our approach on the popular Penn-Fudan pedestrian parsing dataset, and demonstrate the effectiveness of using the pose information for each stage of the parsing pipeline. Finally, we show that our approach yields superior part segmentation accuracy comparing to the state-of-the-art methods.