 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Fairness in Large-Scale Object Recognition by CrowdSourced Demographic Information
Jun 02, 2022

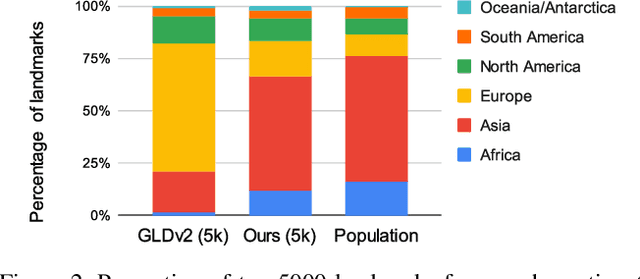
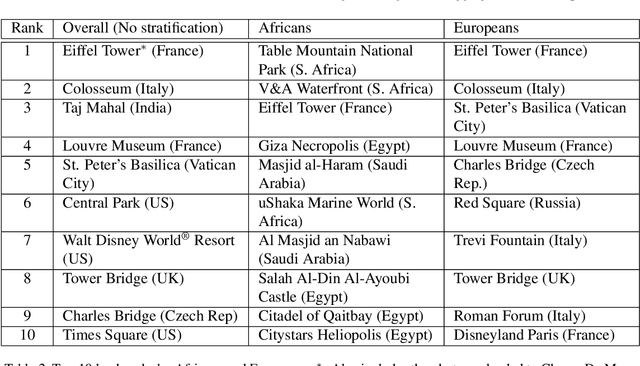
There has been increasing awareness of ethical issues in machine learning, and fairness has become an important research topic. Most fairness efforts in computer vision have been focused on human sensing applications and preventing discrimination by people's physical attributes such as race, skin color or age by increasing visual representation for particular demographic groups. We argue that ML fairness efforts should extend to object recognition as well. Buildings, artwork, food and clothing are examples of the objects that define human culture. Representing these objects fairly in machine learning datasets will lead to models that are less biased towards a particular culture and more inclusive of different traditions and values. There exist many research datasets for object recognition, but they have not carefully considered which classes should be included, or how much training data should be collected per class. To address this, we propose a simple and general approach, based on crowdsourcing the demographic composition of the contributors: we define fair relevance scores, estimate them, and assign them to each class. We showcase its application to the landmark recognition domain, presenting a detailed analysis and the final fairer landmark rankings. We present analysis which leads to a much fairer coverage of the world compared to existing datasets. The evaluation dataset was used for the 2021 Google Landmark Challenges, which was the first of a kind with an emphasis on fairness in generic object recognition.
Towards A Fairer Landmark Recognition Dataset
Aug 19, 2021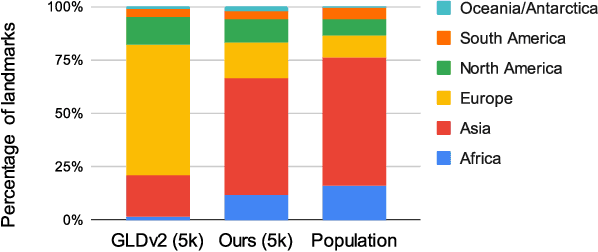
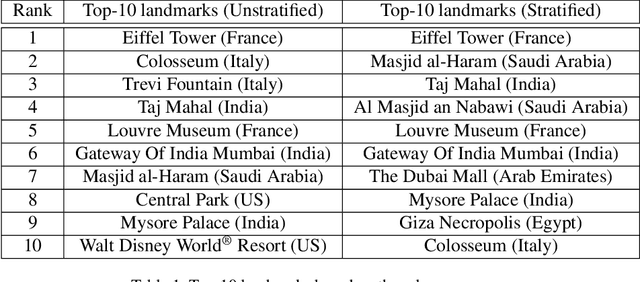
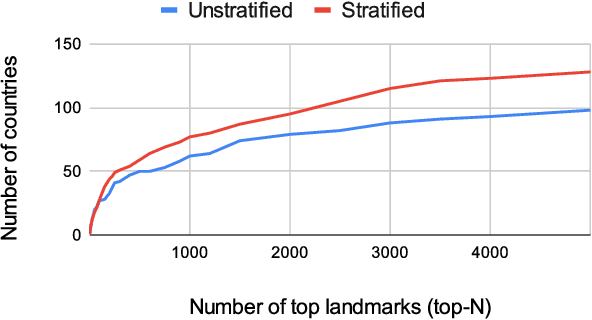

We introduce a new landmark recognition dataset, which is created with a focus on fair worldwide representation. While previous work proposes to collect as many images as possible from web repositories, we instead argue that such approaches can lead to biased data. To create a more comprehensive and equitable dataset, we start by defining the fair relevance of a landmark to the world population. These relevances are estimated by combining anonymized Google Maps user contribution statistics with the contributors' demographic information. We present a stratification approach and analysis which leads to a much fairer coverage of the world, compared to existing datasets. The resulting datasets are used to evaluate computer vision models as part of the the Google Landmark Recognition and RetrievalChallenges 2021.
Nutrition5k: Towards Automatic Nutritional Understanding of Generic Food
Mar 04, 2021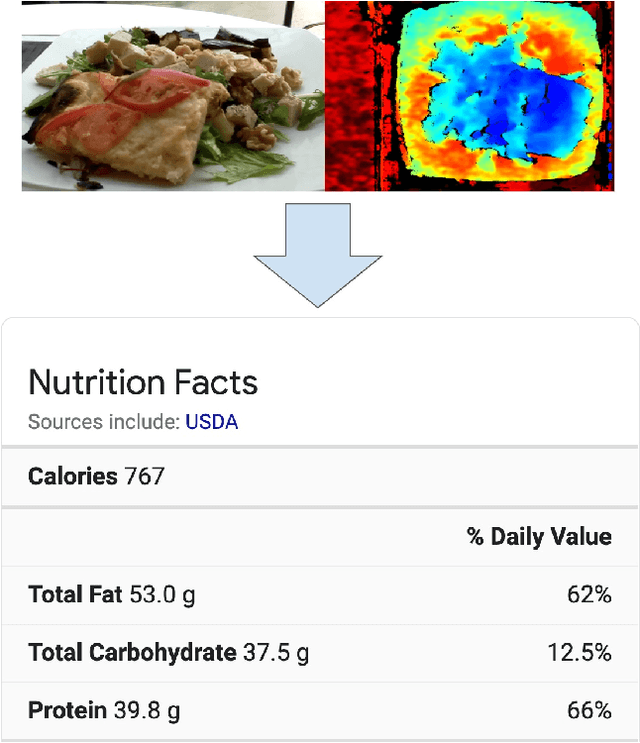
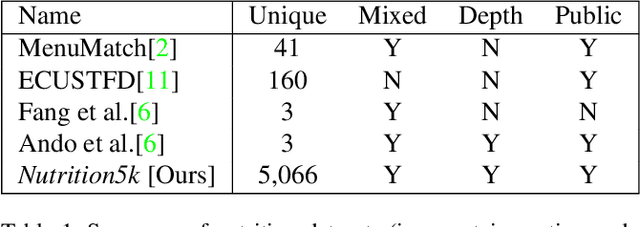

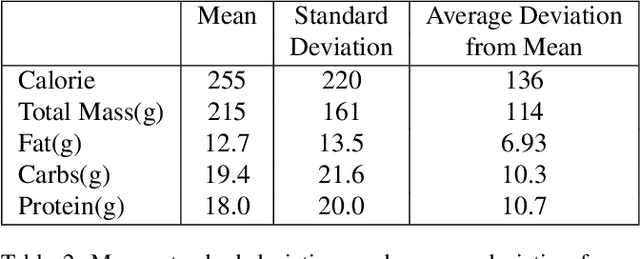
Understanding the nutritional content of food from visual data is a challenging computer vision problem, with the potential to have a positive and widespread impact on public health. Studies in this area are limited to existing datasets in the field that lack sufficient diversity or labels required for training models with nutritional understanding capability. We introduce Nutrition5k, a novel dataset of 5k diverse, real world food dishes with corresponding video streams, depth images, component weights, and high accuracy nutritional content annotation. We demonstrate the potential of this dataset by training a computer vision algorithm capable of predicting the caloric and macronutrient values of a complex, real world dish at an accuracy that outperforms professional nutritionists. Further we present a baseline for incorporating depth sensor data to improve nutrition predictions. We will publicly release Nutrition5k in the hope that it will accelerate innovation in the space of nutritional understanding.
Google Landmarks Dataset v2 -- A Large-Scale Benchmark for Instance-Level Recognition and Retrieval
Apr 03, 2020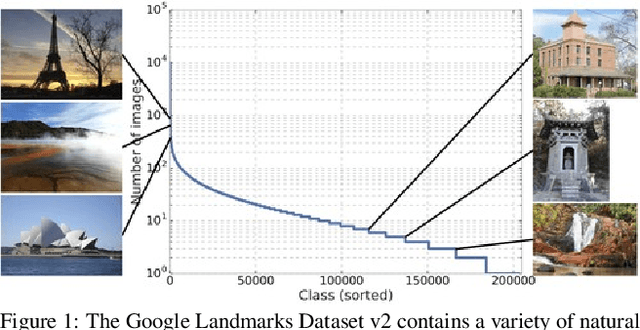
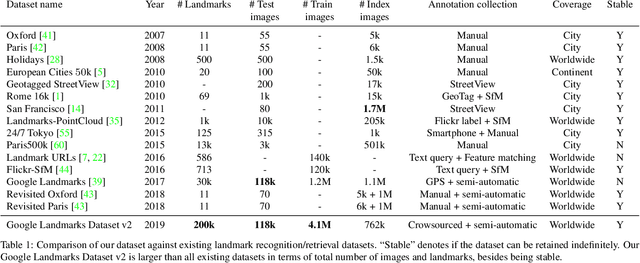
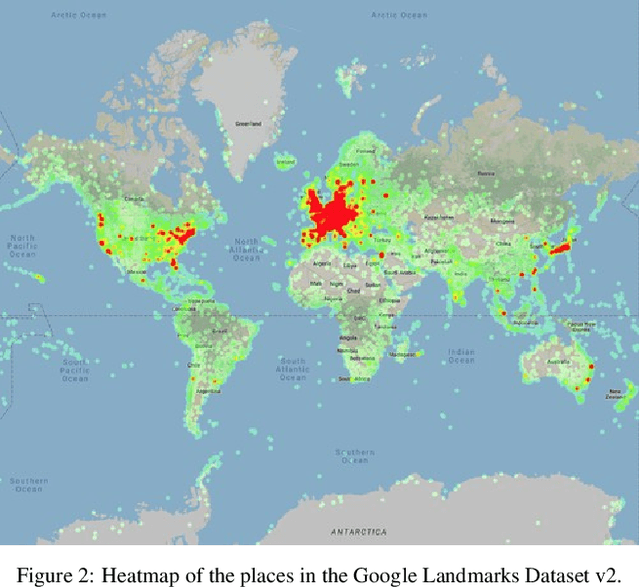

While image retrieval and instance recognition techniques are progressing rapidly, there is a need for challenging datasets to accurately measure their performance -- while posing novel challenges that are relevant for practical applications. We introduce the Google Landmarks Dataset v2 (GLDv2), a new benchmark for large-scale, fine-grained instance recognition and image retrieval in the domain of human-made and natural landmarks. GLDv2 is the largest such dataset to date by a large margin, including over 5M images and 200k distinct instance labels. Its test set consists of 118k images with ground truth annotations for both the retrieval and recognition tasks. The ground truth construction involved over 800 hours of human annotator work. Our new dataset has several challenging properties inspired by real world applications that previous datasets did not consider: An extremely long-tailed class distribution, a large fraction of out-of-domain test photos and large intra-class variability. The dataset is sourced from Wikimedia Commons, the world's largest crowdsourced collection of landmark photos. We provide baseline results for both recognition and retrieval tasks based on state-of-the-art methods as well as competitive results from a public challenge. We further demonstrate the suitability of the dataset for transfer learning by showing that image embeddings trained on it achieve competitive retrieval performance on independent datasets. The dataset images, ground-truth and metric scoring code are available at https://github.com/cvdfoundation/google-landmark.
Unifying Deep Local and Global Features for Efficient Image Search
Jan 14, 2020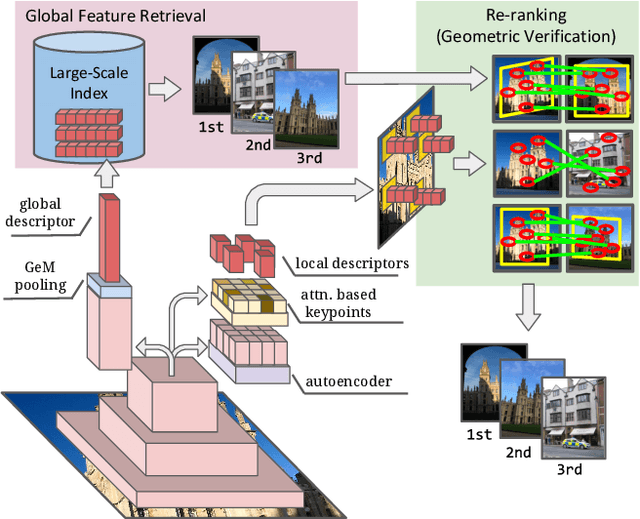

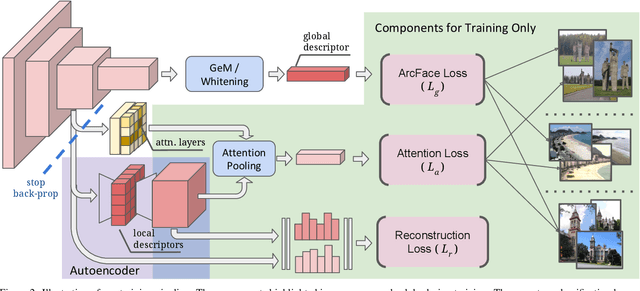
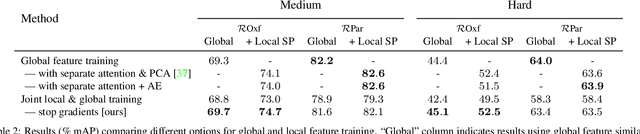
A key challenge in large-scale image retrieval problems is the trade-off between scalability and accuracy. Recent research has made great strides to improve scalability with compact global image features, and accuracy with local image features. In this work, our main contribution is to unify global and local image features into a single deep model, enabling scalable retrieval with high accuracy. We refer to the new model as DELG, standing for DEep Local and Global features. We leverage lessons from recent feature learning work and propose a model that combines generalized mean pooling for global features and attentive selection for local features. The entire network can be learned end-to-end by carefully balancing the gradient flow between two heads -- requiring only image-level labels. We also introduce an autoencoder-based dimensionality reduction technique for local features, which is integrated into the model, improving training efficiency and matching performance. Experiments on the Revisited Oxford and Paris datasets demonstrate that our jointly learned ResNet-50 based features outperform all previous results using deep global features (most with heavier backbones) and those that further re-rank with local features. Code and models will be released.
Detect-to-Retrieve: Efficient Regional Aggregation for Image Search
Dec 04, 2018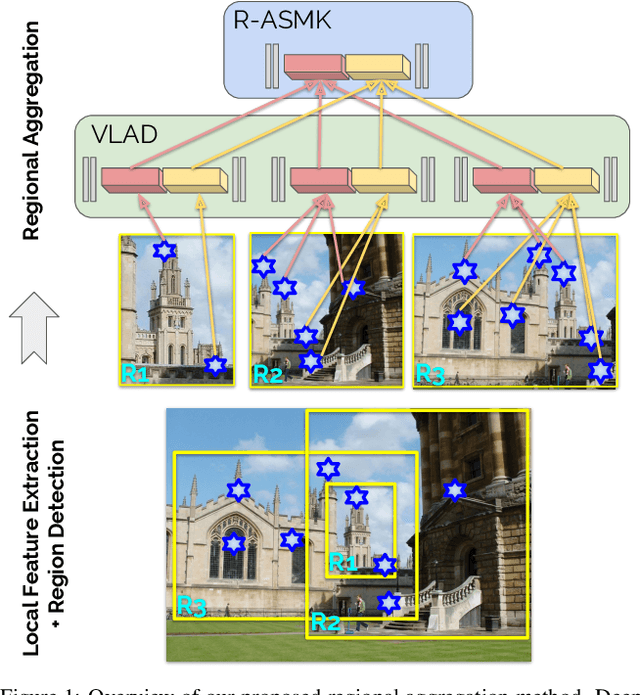
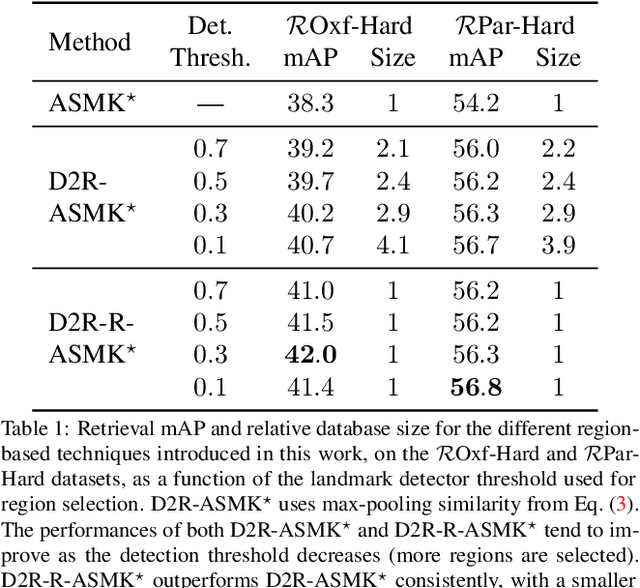

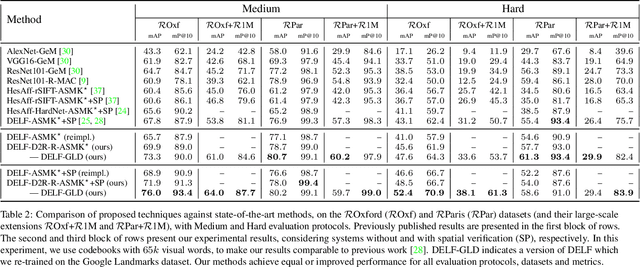
Retrieving object instances among cluttered scenes efficiently requires compact yet comprehensive regional image representations. Intuitively, object semantics can help build the index that focuses on the most relevant regions. However, due to the lack of bounding-box datasets for objects of interest among retrieval benchmarks, most recent work on regional representations has focused on either uniform or class-agnostic region selection. In this paper, we first fill the void by providing a new dataset of landmark bounding boxes, based on the Google Landmarks dataset, that includes $94k$ images with manually curated boxes from $15k$ unique landmarks. Then, we demonstrate how a trained landmark detector, using our new dataset, can be leveraged to index image regions and improve retrieval accuracy while being much more efficient than existing regional methods. In addition, we further introduce a novel regional aggregated selective match kernel (R-ASMK) to effectively combine information from detected regions into an improved holistic image representation. R-ASMK boosts image retrieval accuracy substantially at no additional memory cost, while even outperforming systems that index image regions independently. Our complete image retrieval system improves upon the previous state-of-the-art by significant margins on the Revisited Oxford and Paris datasets. Code and data will be released.
CPlaNet: Enhancing Image Geolocalization by Combinatorial Partitioning of Maps
Aug 06, 2018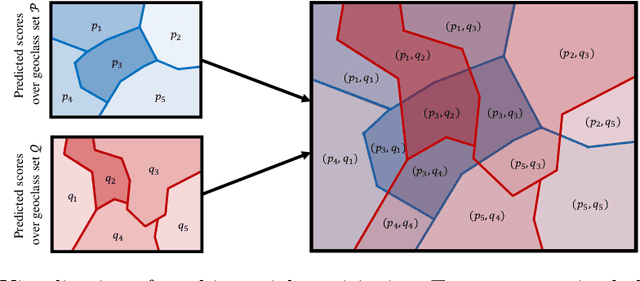
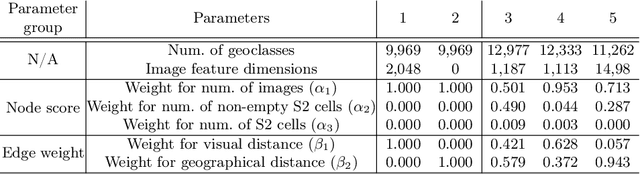

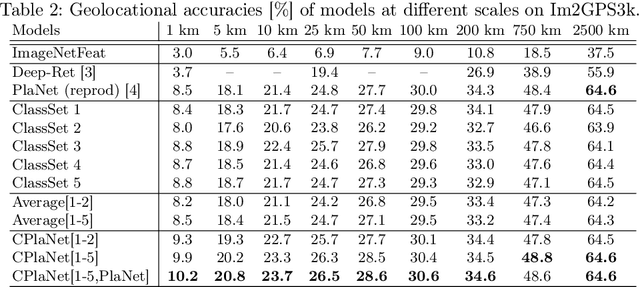
Image geolocalization is the task of identifying the location depicted in a photo based only on its visual information. This task is inherently challenging since many photos have only few, possibly ambiguous cues to their geolocation. Recent work has cast this task as a classification problem by partitioning the earth into a set of discrete cells that correspond to geographic regions. The granularity of this partitioning presents a critical trade-off; using fewer but larger cells results in lower location accuracy while using more but smaller cells reduces the number of training examples per class and increases model size, making the model prone to overfitting. To tackle this issue, we propose a simple but effective algorithm, combinatorial partitioning, which generates a large number of fine-grained output classes by intersecting multiple coarse-grained partitionings of the earth. Each classifier votes for the fine-grained classes that overlap with their respective coarse-grained ones. This technique allows us to predict locations at a fine scale while maintaining sufficient training examples per class. Our algorithm achieves the state-of-the-art performance in location recognition on multiple benchmark datasets.
Large-Scale Image Retrieval with Attentive Deep Local Features
Feb 03, 2018
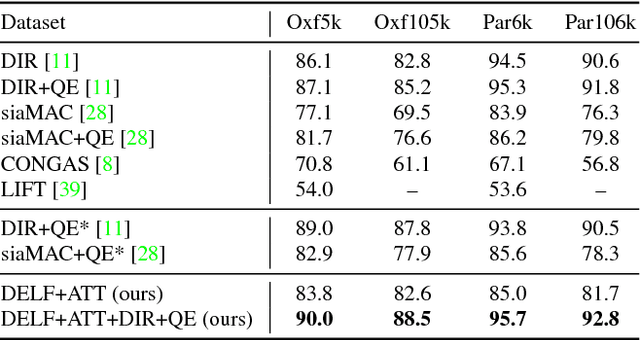

We propose an attentive local feature descriptor suitable for large-scale image retrieval, referred to as DELF (DEep Local Feature). The new feature is based on convolutional neural networks, which are trained only with image-level annotations on a landmark image dataset. To identify semantically useful local features for image retrieval, we also propose an attention mechanism for keypoint selection, which shares most network layers with the descriptor. This framework can be used for image retrieval as a drop-in replacement for other keypoint detectors and descriptors, enabling more accurate feature matching and geometric verification. Our system produces reliable confidence scores to reject false positives---in particular, it is robust against queries that have no correct match in the database. To evaluate the proposed descriptor, we introduce a new large-scale dataset, referred to as Google-Landmarks dataset, which involves challenges in both database and query such as background clutter, partial occlusion, multiple landmarks, objects in variable scales, etc. We show that DELF outperforms the state-of-the-art global and local descriptors in the large-scale setting by significant margins. Code and dataset can be found at the project webpage: https://github.com/tensorflow/models/tree/master/research/delf .