 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsymmetric self-play for automatic goal discovery in robotic manipulation
Jan 13, 2021
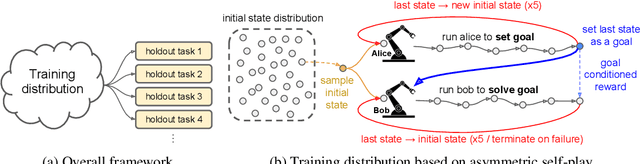
We train a single, goal-conditioned policy that can solve many robotic manipulation tasks, including tasks with previously unseen goals and objects. We rely on asymmetric self-play for goal discovery, where two agents, Alice and Bob, play a game. Alice is asked to propose challenging goals and Bob aims to solve them. We show that this method can discover highly diverse and complex goals without any human priors. Bob can be trained with only sparse rewards, because the interaction between Alice and Bob results in a natural curriculum and Bob can learn from Alice's trajectory when relabeled as a goal-conditioned demonstration. Finally, our method scales, resulting in a single policy that can generalize to many unseen tasks such as setting a table, stacking blocks, and solving simple puzzles. Videos of a learned policy is available at https://robotics-self-play.github.io.
Behavior Priors for Efficient Reinforcement Learning
Oct 27, 2020
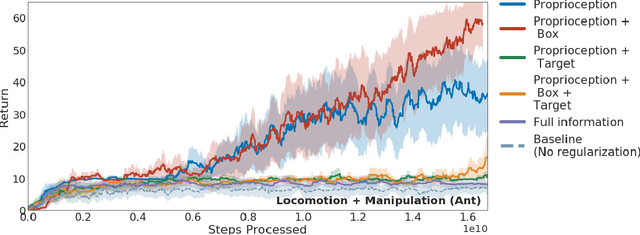

As we deploy reinforcement learning agents to solve increasingly challenging problems, methods that allow us to inject prior knowledge about the structure of the world and effective solution strategies becomes increasingly important. In this work we consider how information and architectural constraints can be combined with ideas from the probabilistic modeling literature to learn behavior priors that capture the common movement and interaction patterns that are shared across a set of related tasks or contexts. For example the day-to day behavior of humans comprises distinctive locomotion and manipulation patterns that recur across many different situations and goals. We discuss how such behavior patterns can be captured using probabilistic trajectory models and how these can be integrated effectively into reinforcement learning schemes, e.g.\ to facilitate multi-task and transfer learning. We then extend these ideas to latent variable models and consider a formulation to learn hierarchical priors that capture different aspects of the behavior in reusable modules. We discuss how such latent variable formulations connect to related work on hierarchical reinforcement learning (HRL) and mutual information and curiosity based objectives, thereby offering an alternative perspective on existing ideas. We demonstrate the effectiveness of our framework by applying it to a range of simulated continuous control domains.
Real-Time Object Tracking via Meta-Learning: Efficient Model Adaptation and One-Shot Channel Pruning
Dec 04, 2019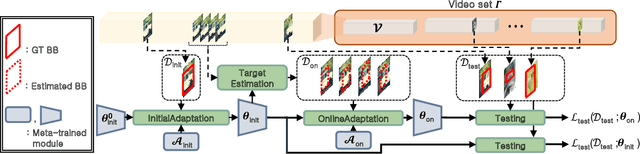

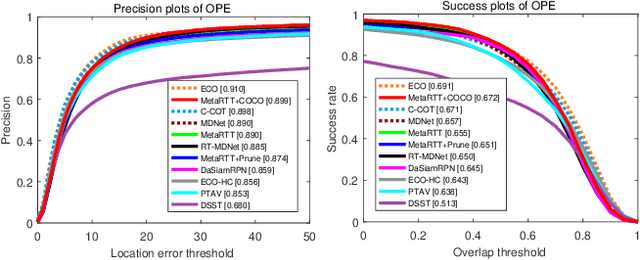
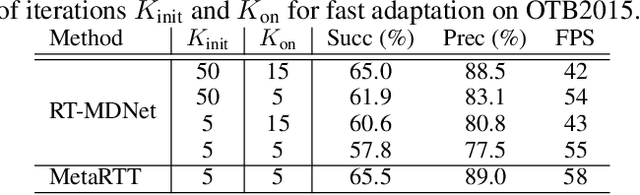
We propose a novel meta-learning framework for real-time object tracking with efficient model adaptation and channel pruning. Given an object tracker, our framework learns to fine-tune its model parameters in only a few iterations of gradient-descent during tracking while pruning its network channels using the target ground-truth at the first frame. Such a learning problem is formulated as a meta-learning task, where a meta-tracker is trained by updating its meta-parameters for initial weights, learning rates, and pruning masks through carefully designed tracking simulations. The integrated meta-tracker greatly improves tracking performance by accelerating the convergence of online learning and reducing the cost of feature computation. Experimental evaluation on the standard datasets demonstrates its outstanding accuracy and speed compared to the state-of-the-art methods.
Exploiting Hierarchy for Learning and Transfer in KL-regularized RL
Mar 18, 2019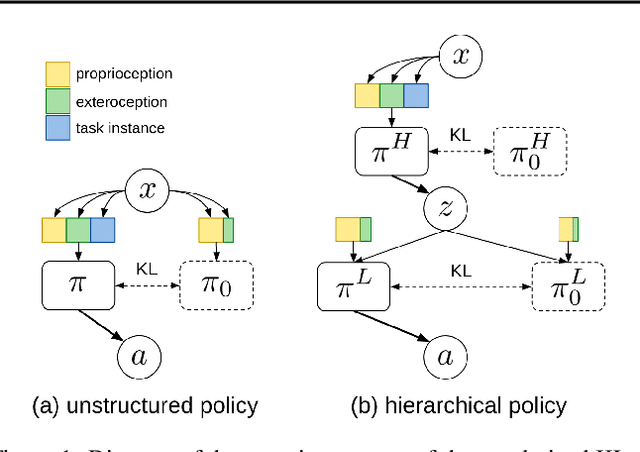
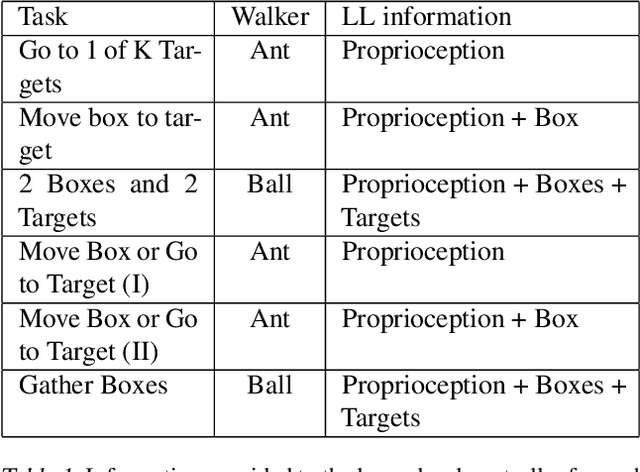

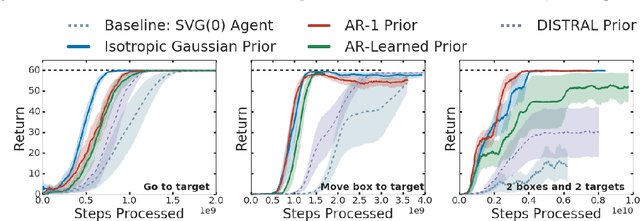
As reinforcement learning agents are tasked with solving more challenging and diverse tasks, the ability to incorporate prior knowledge into the learning system and to exploit reusable structure in solution space is likely to become increasingly important. The KL-regularized expected reward objective constitutes one possible tool to this end. It introduces an additional component, a default or prior behavior, which can be learned alongside the policy and as such partially transforms the reinforcement learning problem into one of behavior modelling. In this work we consider the implications of this framework in cases where both the policy and default behavior are augmented with latent variables. We discuss how the resulting hierarchical structures can be used to implement different inductive biases and how their modularity can benefit transfer. Empirically we find that they can lead to faster learning and transfer on a range of continuous control tasks.
Transfer Learning via Unsupervised Task Discovery for Visual Question Answering
Oct 03, 2018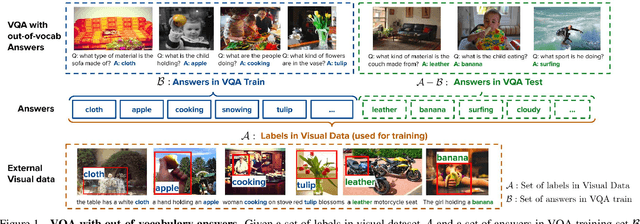
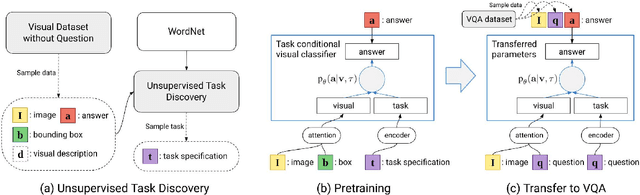


We study how to leverage off-the-shelf visual and linguistic data to cope with out-of-vocabulary answers in visual question answering. Existing large-scale visual data with annotations such as image class labels, bounding boxes and region descriptions are good sources for learning rich and diverse visual concepts. However, it is not straightforward how the visual concepts should be captured and transferred to visual question answering models due to missing link between question dependent answering models and visual data without question or task specification. We tackle this problem in two steps: 1) learning a task conditional visual classifier based on unsupervised task discovery and 2) transferring and adapting the task conditional visual classifier to visual question answering models. Specifically, we employ linguistic knowledge sources such as structured lexical database (e.g. Wordnet) and visual descriptions for unsupervised task discovery, and adapt a learned task conditional visual classifier to answering unit in a visual question answering model. We empirically show that the proposed algorithm generalizes to unseen answers successfully using the knowledge transferred from the visual data.
Large-Scale Image Retrieval with Attentive Deep Local Features
Feb 03, 2018
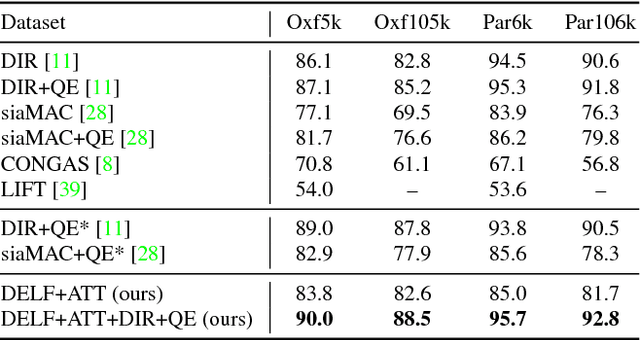

We propose an attentive local feature descriptor suitable for large-scale image retrieval, referred to as DELF (DEep Local Feature). The new feature is based on convolutional neural networks, which are trained only with image-level annotations on a landmark image dataset. To identify semantically useful local features for image retrieval, we also propose an attention mechanism for keypoint selection, which shares most network layers with the descriptor. This framework can be used for image retrieval as a drop-in replacement for other keypoint detectors and descriptors, enabling more accurate feature matching and geometric verification. Our system produces reliable confidence scores to reject false positives---in particular, it is robust against queries that have no correct match in the database. To evaluate the proposed descriptor, we introduce a new large-scale dataset, referred to as Google-Landmarks dataset, which involves challenges in both database and query such as background clutter, partial occlusion, multiple landmarks, objects in variable scales, etc. We show that DELF outperforms the state-of-the-art global and local descriptors in the large-scale setting by significant margins. Code and dataset can be found at the project webpage: https://github.com/tensorflow/models/tree/master/research/delf .
Regularizing Deep Neural Networks by Noise: Its Interpretation and Optimization
Nov 09, 2017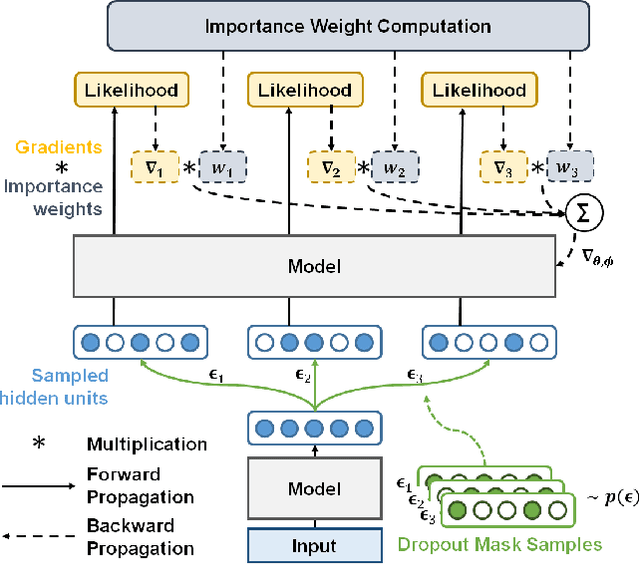

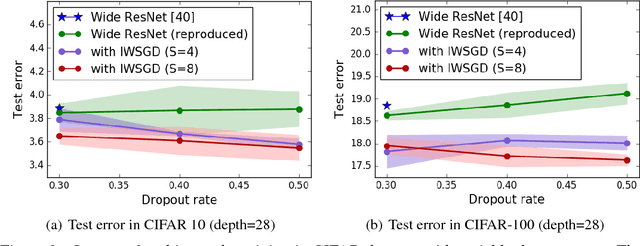

Overfitting is one of the most critical challenges in deep neural networks, and there are various types of regularization methods to improve generalization performance. Injecting noises to hidden units during training, e.g., dropout, is known as a successful regularizer, but it is still not clear enough why such training techniques work well in practice and how we can maximize their benefit in the presence of two conflicting objectives---optimizing to true data distribution and preventing overfitting by regularization. This paper addresses the above issues by 1) interpreting that the conventional training methods with regularization by noise injection optimize the lower bound of the true objective and 2) proposing a technique to achieve a tighter lower bound using multiple noise samples per training example in a stochastic gradient descent iteration. We demonstrate the effectiveness of our idea in several computer vision applications.
Training Recurrent Answering Units with Joint Loss Minimization for VQA
Sep 30, 2016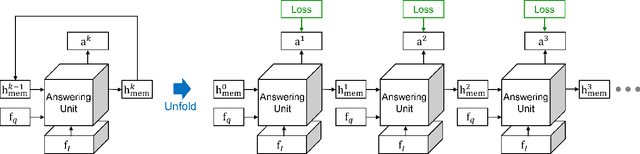
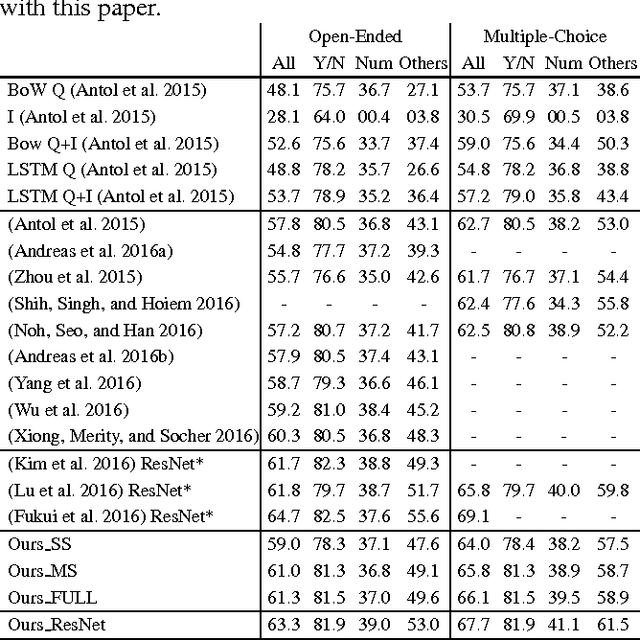
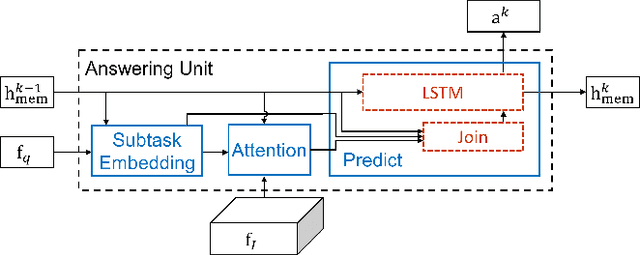
We propose a novel algorithm for visual question answering based on a recurrent deep neural network, where every module in the network corresponds to a complete answering unit with attention mechanism by itself. The network is optimized by minimizing loss aggregated from all the units, which share model parameters while receiving different information to compute attention probability. For training, our model attends to a region within image feature map, updates its memory based on the question and attended image feature, and answers the question based on its memory state. This procedure is performed to compute loss in each step. The motivation of this approach is our observation that multi-step inferences are often required to answer questions while each problem may have a unique desirable number of steps, which is difficult to identify in practice. Hence, we always make the first unit in the network solve problems, but allow it to learn the knowledge from the rest of units by backpropagation unless it degrades the model. To implement this idea, we early-stop training each unit as soon as it starts to overfit. Note that, since more complex models tend to overfit on easier questions quickly, the last answering unit in the unfolded recurrent neural network is typically killed first while the first one remains last. We make a single-step prediction for a new question using the shared model. This strategy works better than the other options within our framework since the selected model is trained effectively from all units without overfitting. The proposed algorithm outperforms other multi-step attention based approaches using a single step prediction in VQA dataset.
Image Question Answering using Convolutional Neural Network with Dynamic Parameter Prediction
Nov 18, 2015
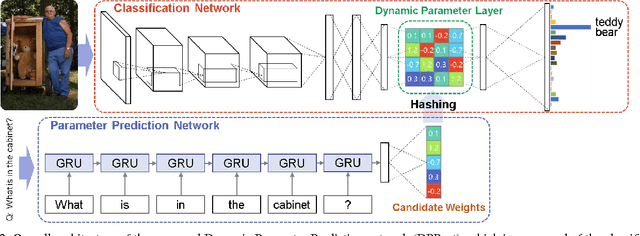
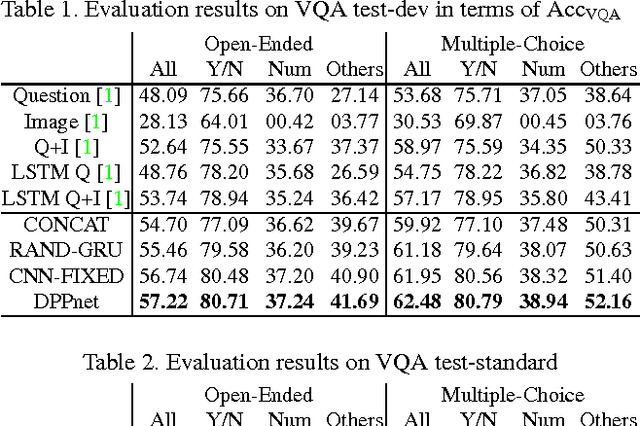
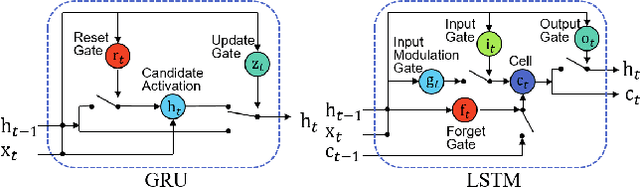
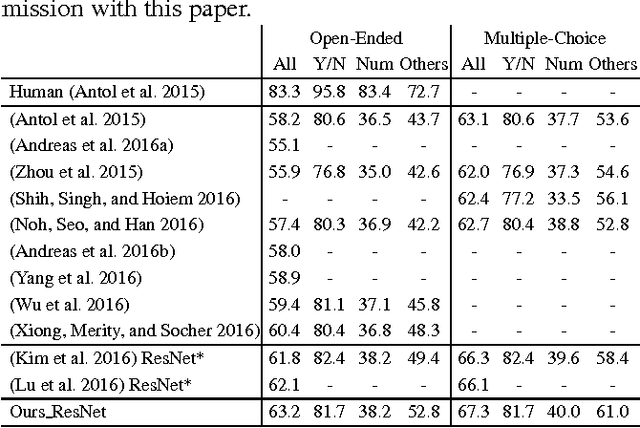
We tackle image question answering (ImageQA) problem by learning a convolutional neural network (CNN) with a dynamic parameter layer whose weights are determined adaptively based on questions. For the adaptive parameter prediction, we employ a separate parameter prediction network, which consists of gated recurrent unit (GRU) taking a question as its input and a fully-connected layer generating a set of candidate weights as its output. However, it is challenging to construct a parameter prediction network for a large number of parameters in the fully-connected dynamic parameter layer of the CNN. We reduce the complexity of this problem by incorporating a hashing technique, where the candidate weights given by the parameter prediction network are selected using a predefined hash function to determine individual weights in the dynamic parameter layer. The proposed network---joint network with the CNN for ImageQA and the parameter prediction network---is trained end-to-end through back-propagation, where its weights are initialized using a pre-trained CNN and GRU. The proposed algorithm illustrates the state-of-the-art performance on all available public ImageQA benchmarks.
Decoupled Deep Neural Network for Semi-supervised Semantic Segmentation
Jun 17, 2015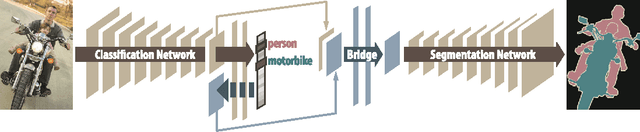
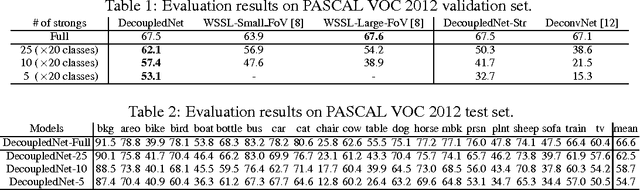

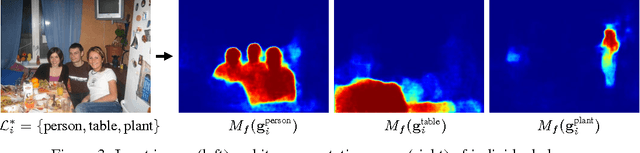
We propose a novel deep neural network architecture for semi-supervised semantic segmentation using heterogeneous annotations. Contrary to existing approaches posing semantic segmentation as a single task of region-based classification, our algorithm decouples classification and segmentation, and learns a separate network for each task. In this architecture, labels associated with an image are identified by classification network, and binary segmentation is subsequently performed for each identified label in segmentation network. The decoupled architecture enables us to learn classification and segmentation networks separately based on the training data with image-level and pixel-wise class labels, respectively. It facilitates to reduce search space for segmentation effectively by exploiting class-specific activation maps obtained from bridging layers. Our algorithm shows outstanding performance compared to other semi-supervised approaches even with much less training images with strong annotations in PASCAL VOC dataset.