 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning via Unsupervised Task Discovery for Visual Question Answering
Paper and Code
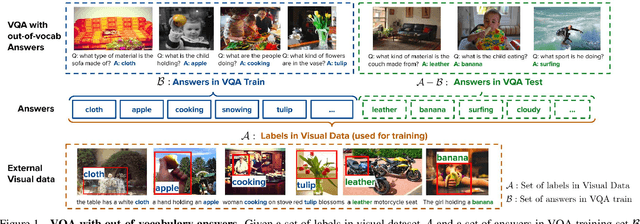
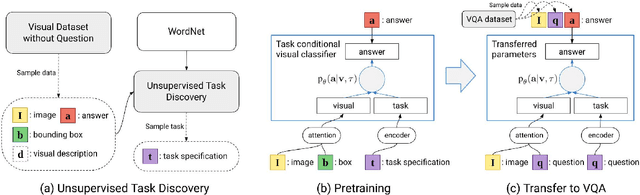


We study how to leverage off-the-shelf visual and linguistic data to cope with out-of-vocabulary answers in visual question answering. Existing large-scale visual data with annotations such as image class labels, bounding boxes and region descriptions are good sources for learning rich and diverse visual concepts. However, it is not straightforward how the visual concepts should be captured and transferred to visual question answering models due to missing link between question dependent answering models and visual data without question or task specification. We tackle this problem in two steps: 1) learning a task conditional visual classifier based on unsupervised task discovery and 2) transferring and adapting the task conditional visual classifier to visual question answering models. Specifically, we employ linguistic knowledge sources such as structured lexical database (e.g. Wordnet) and visual descriptions for unsupervised task discovery, and adapt a learned task conditional visual classifier to answering unit in a visual question answering model. We empirically show that the proposed algorithm generalizes to unseen answers successfully using the knowledge transferred from the visual data.