 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZoom Better to See Clearer: Human and Object Parsing with Hierarchical Auto-Zoom Net
Paper and Code
Mar 28, 2016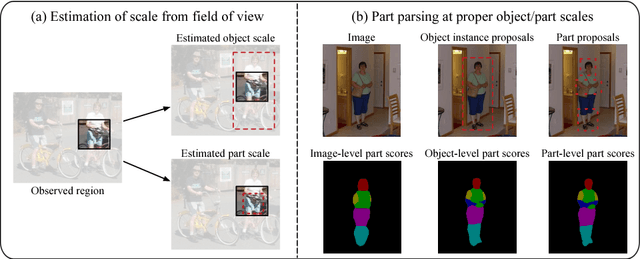
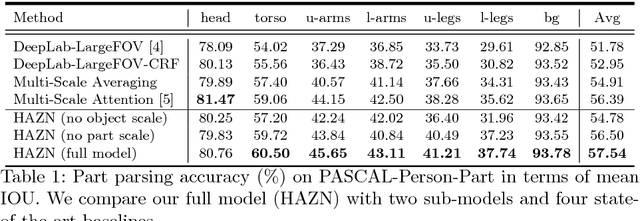
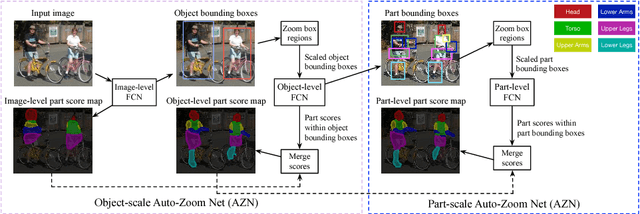
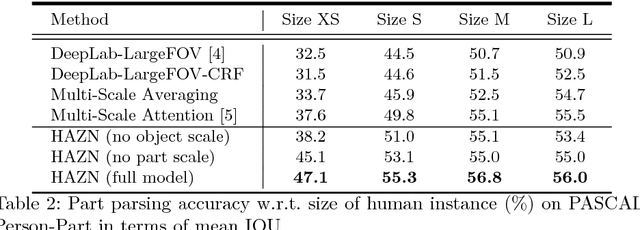
Parsing articulated objects, e.g. humans and animals, into semantic parts (e.g. body, head and arms, etc.) from natural images is a challenging and fundamental problem for computer vision. A big difficulty is the large variability of scale and location for objects and their corresponding parts. Even limited mistakes in estimating scale and location will degrade the parsing output and cause errors in boundary details. To tackle these difficulties, we propose a "Hierarchical Auto-Zoom Net" (HAZN) for object part parsing which adapts to the local scales of objects and parts. HAZN is a sequence of two "Auto-Zoom Net" (AZNs), each employing fully convolutional networks that perform two tasks: (1) predict the locations and scales of object instances (the first AZN) or their parts (the second AZN); (2) estimate the part scores for predicted object instance or part regions. Our model can adaptively "zoom" (resize) predicted image regions into their proper scales to refine the parsing. We conduct extensive experiments over the PASCAL part datasets on humans, horses, and cows. For humans, our approach significantly outperforms the state-of-the-arts by 5% mIOU and is especially better at segmenting small instances and small parts. We obtain similar improvements for parsing cows and horses over alternative methods. In summary, our strategy of first zooming into objects and then zooming into parts is very effective. It also enables us to process different regions of the image at different scales adaptively so that, for example, we do not need to waste computational resources scaling the entire image.