 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime-based Sequence Model for Personalization and Recommendation Systems
Aug 27, 2020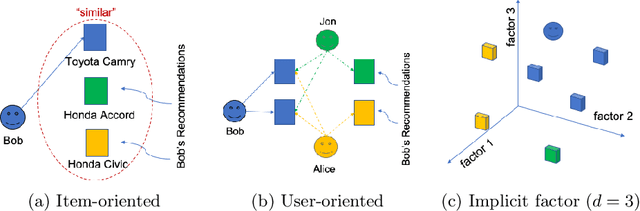

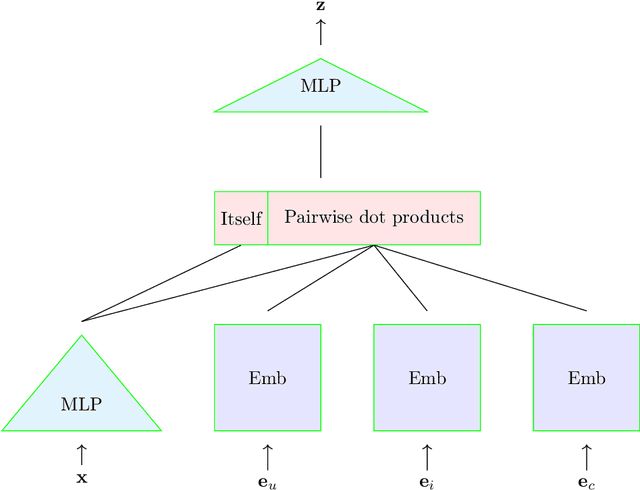
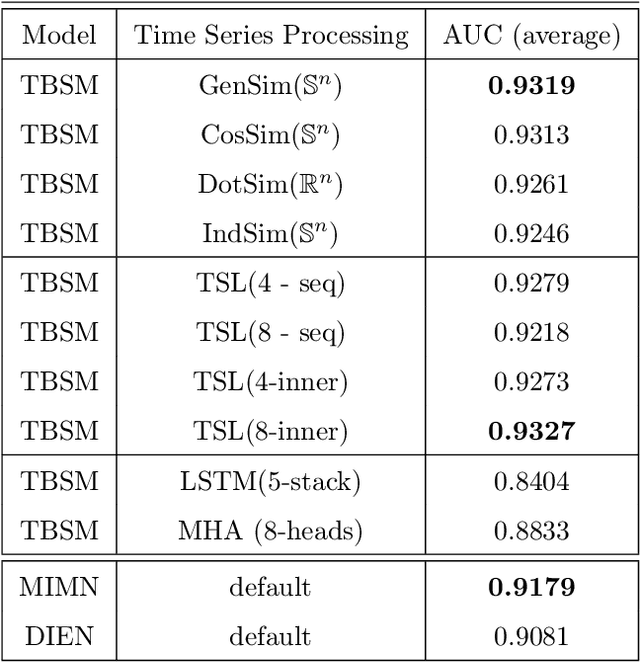
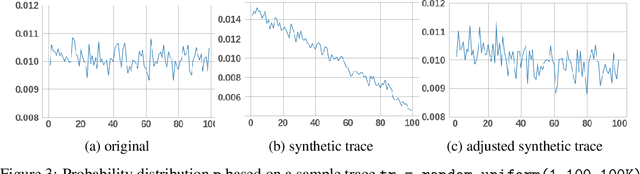
In this paper we develop a novel recommendation model that explicitly incorporates time information. The model relies on an embedding layer and TSL attention-like mechanism with inner products in different vector spaces, that can be thought of as a modification of multi-headed attention. This mechanism allows the model to efficiently treat sequences of user behavior of different length. We study the properties of our state-of-the-art model on statistically designed data set. Also, we show that it outperforms more complex models with longer sequence length on the Taobao User Behavior dataset.
Deep Learning Recommendation Model for Personalization and Recommendation Systems
May 31, 2019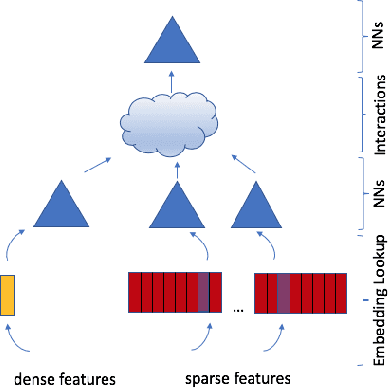

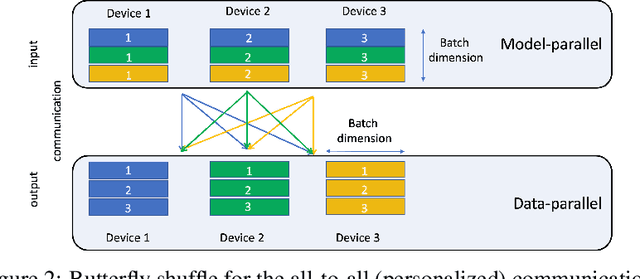
With the advent of deep learning, neural network-based recommendation models have emerged as an important tool for tackling personalization and recommendation tasks. These networks differ significantly from other deep learning networks due to their need to handle categorical features and are not well studied or understood. In this paper, we develop a state-of-the-art deep learning recommendation model (DLRM) and provide its implementation in both PyTorch and Caffe2 frameworks. In addition, we design a specialized parallelization scheme utilizing model parallelism on the embedding tables to mitigate memory constraints while exploiting data parallelism to scale-out compute from the fully-connected layers. We compare DLRM against existing recommendation models and characterize its performance on the Big Basin AI platform, demonstrating its usefulness as a benchmark for future algorithmic experimentation and system co-design.
Joint Multi-Person Pose Estimation and Semantic Part Segmentation
Aug 10, 2017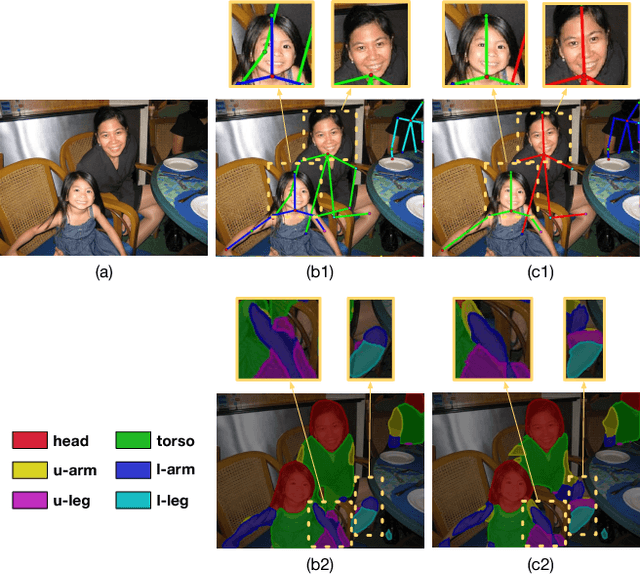
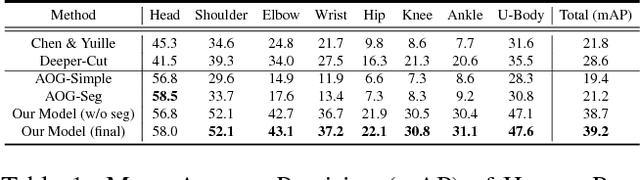


Human pose estimation and semantic part segmentation are two complementary tasks in computer vision. In this paper, we propose to solve the two tasks jointly for natural multi-person images, in which the estimated pose provides object-level shape prior to regularize part segments while the part-level segments constrain the variation of pose locations. Specifically, we first train two fully convolutional neural networks (FCNs), namely Pose FCN and Part FCN, to provide initial estimation of pose joint potential and semantic part potential. Then, to refine pose joint location, the two types of potentials are fused with a fully-connected conditional random field (FCRF), where a novel segment-joint smoothness term is used to encourage semantic and spatial consistency between parts and joints. To refine part segments, the refined pose and the original part potential are integrated through a Part FCN, where the skeleton feature from pose serves as additional regularization cues for part segments. Finally, to reduce the complexity of the FCRF, we induce human detection boxes and infer the graph inside each box, making the inference forty times faster. Since there's no dataset that contains both part segments and pose labels, we extend the PASCAL VOC part dataset with human pose joints and perform extensive experiments to compare our method against several most recent strategies. We show that on this dataset our algorithm surpasses competing methods by a large margin in both tasks.
Ground-truth dataset and baseline evaluations for image base-detail separation algorithms
Feb 18, 2016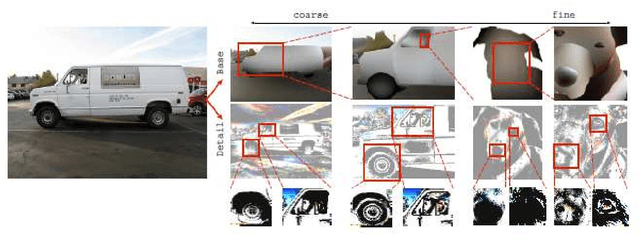


Base-detail separation is a fundamental computer vision problem consisting of modeling a smooth base layer with the coarse structures, and a detail layer containing the texture-like structures. One of the challenges of estimating the base is to preserve sharp boundaries between objects or parts to avoid halo artifacts. Many methods have been proposed to address this problem, but there is no ground-truth dataset of real images for quantitative evaluation. We proposed a procedure to construct such a dataset, and provide two datasets: Pascal Base-Detail and Fashionista Base-Detail, containing 1000 and 250 images, respectively. Our assumption is that the base is piecewise smooth and we label the appearance of each piece by a polynomial model. The pieces are objects and parts of objects, obtained from human annotations. Finally, we proposed a way to evaluate methods with our base-detail ground-truth and we compared the performances of seven state-of-the-art algorithms.
DeePM: A Deep Part-Based Model for Object Detection and Semantic Part Localization
Jan 26, 2016

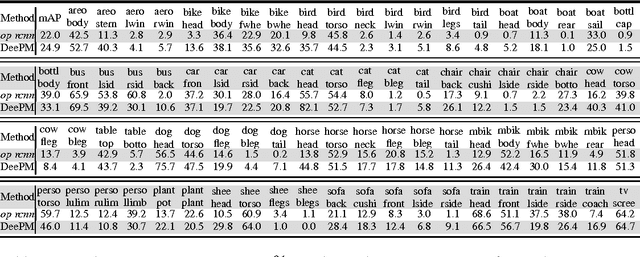

In this paper, we propose a deep part-based model (DeePM) for symbiotic object detection and semantic part localization. For this purpose, we annotate semantic parts for all 20 object categories on the PASCAL VOC 2012 dataset, which provides information on object pose, occlusion, viewpoint and functionality. DeePM is a latent graphical model based on the state-of-the-art R-CNN framework, which learns an explicit representation of the object-part configuration with flexible type sharing (e.g., a sideview horse head can be shared by a fully-visible sideview horse and a highly truncated sideview horse with head and neck only). For comparison, we also present an end-to-end Object-Part (OP) R-CNN which learns an implicit feature representation for jointly mapping an image ROI to the object and part bounding boxes. We evaluate the proposed methods for both the object and part detection performance on PASCAL VOC 2012, and show that DeePM consistently outperforms OP R-CNN in detecting objects and parts. In addition, it obtains superior performance to Fast and Faster R-CNNs in object detection.
Parsing Occluded People by Flexible Compositions
Nov 24, 2015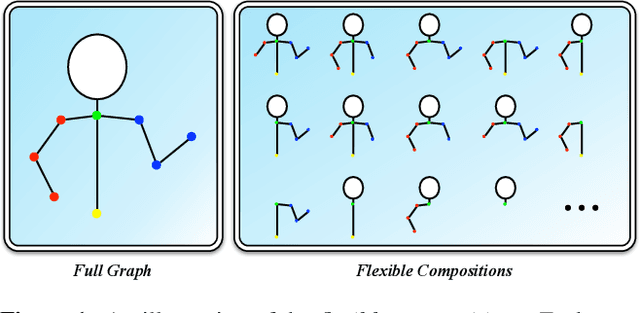



This paper presents an approach to parsing humans when there is significant occlusion. We model humans using a graphical model which has a tree structure building on recent work [32, 6] and exploit the connectivity prior that, even in presence of occlusion, the visible nodes form a connected subtree of the graphical model. We call each connected subtree a flexible composition of object parts. This involves a novel method for learning occlusion cues. During inference we need to search over a mixture of different flexible models. By exploiting part sharing, we show that this inference can be done extremely efficiently requiring only twice as many computations as searching for the entire object (i.e., not modeling occlusion). We evaluate our model on the standard benchmarked "We Are Family" Stickmen dataset and obtain significant performance improvements over the best alternative algorithms.
Articulated Pose Estimation by a Graphical Model with Image Dependent Pairwise Relations
Nov 04, 2014



We present a method for estimating articulated human pose from a single static image based on a graphical model with novel pairwise relations that make adaptive use of local image measurements. More precisely, we specify a graphical model for human pose which exploits the fact the local image measurements can be used both to detect parts (or joints) and also to predict the spatial relationships between them (Image Dependent Pairwise Relations). These spatial relationships are represented by a mixture model. We use Deep Convolutional Neural Networks (DCNNs) to learn conditional probabilities for the presence of parts and their spatial relationships within image patches. Hence our model combines the representational flexibility of graphical models with the efficiency and statistical power of DCNNs. Our method significantly outperforms the state of the art methods on the LSP and FLIC datasets and also performs very well on the Buffy dataset without any training.
Detect What You Can: Detecting and Representing Objects using Holistic Models and Body Parts
Jun 08, 2014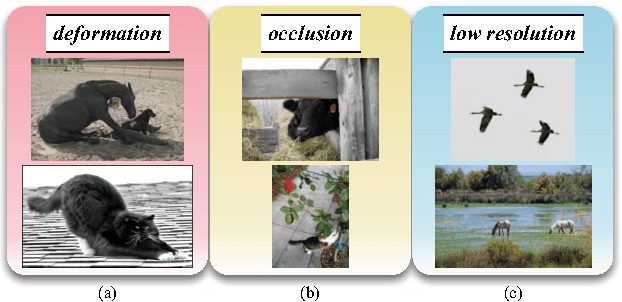



Detecting objects becomes difficult when we need to deal with large shape deformation, occlusion and low resolution. We propose a novel approach to i) handle large deformations and partial occlusions in animals (as examples of highly deformable objects), ii) describe them in terms of body parts, and iii) detect them when their body parts are hard to detect (e.g., animals depicted at low resolution). We represent the holistic object and body parts separately and use a fully connected model to arrange templates for the holistic object and body parts. Our model automatically decouples the holistic object or body parts from the model when they are hard to detect. This enables us to represent a large number of holistic object and body part combinations to better deal with different "detectability" patterns caused by deformations, occlusion and/or low resolution. We apply our method to the six animal categories in the PASCAL VOC dataset and show that our method significantly improves state-of-the-art (by 4.1% AP) and provides a richer representation for objects. During training we use annotations for body parts (e.g., head, torso, etc), making use of a new dataset of fully annotated object parts for PASCAL VOC 2010, which provides a mask for each part.