 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGround-truth dataset and baseline evaluations for image base-detail separation algorithms
Feb 18, 2016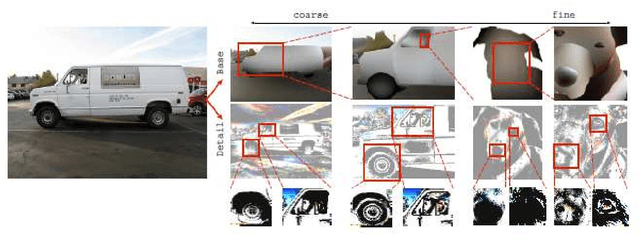
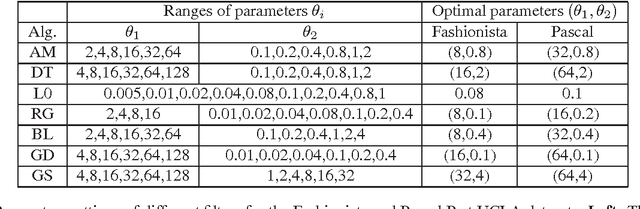


Base-detail separation is a fundamental computer vision problem consisting of modeling a smooth base layer with the coarse structures, and a detail layer containing the texture-like structures. One of the challenges of estimating the base is to preserve sharp boundaries between objects or parts to avoid halo artifacts. Many methods have been proposed to address this problem, but there is no ground-truth dataset of real images for quantitative evaluation. We proposed a procedure to construct such a dataset, and provide two datasets: Pascal Base-Detail and Fashionista Base-Detail, containing 1000 and 250 images, respectively. Our assumption is that the base is piecewise smooth and we label the appearance of each piece by a polynomial model. The pieces are objects and parts of objects, obtained from human annotations. Finally, we proposed a way to evaluate methods with our base-detail ground-truth and we compared the performances of seven state-of-the-art algorithms.
PASCAL Boundaries: A Class-Agnostic Semantic Boundary Dataset
Nov 25, 2015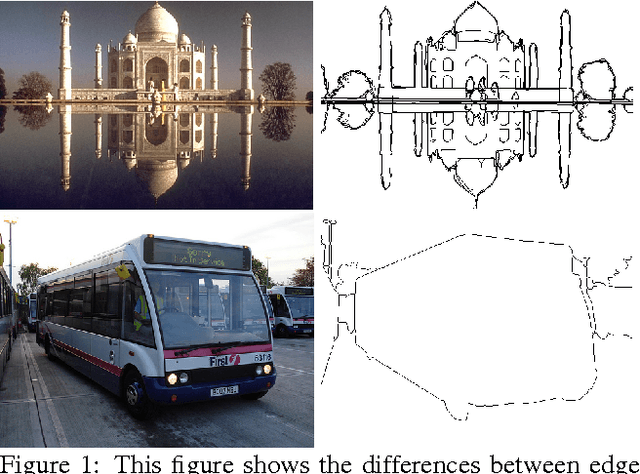
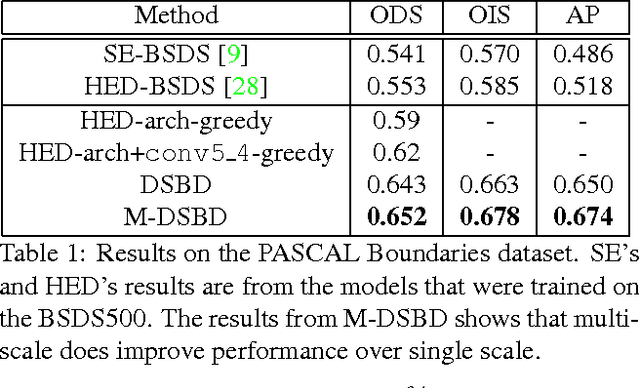
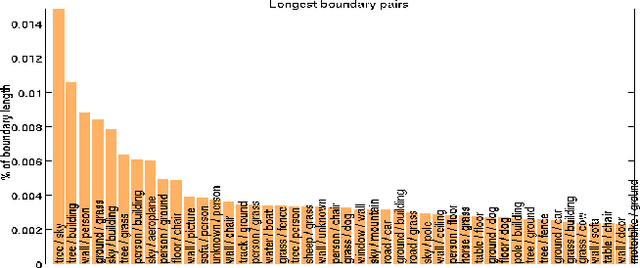

In this paper, we address the boundary detection task motivated by the ambiguities in current definition of edge detection. To this end, we generate a large database consisting of more than 10k images (which is 20x bigger than existing edge detection databases) along with ground truth boundaries between 459 semantic classes including both foreground objects and different types of background, and call it the PASCAL Boundaries dataset, which will be released to the community. In addition, we propose a novel deep network-based multi-scale semantic boundary detector and name it Multi-scale Deep Semantic Boundary Detector (M-DSBD). We provide baselines using models that were trained on edge detection and show that they transfer reasonably to the task of boundary detection. Finally, we point to various important research problems that this dataset can be used for.
Statistical sentiment analysis performance in Opinum
Mar 03, 2013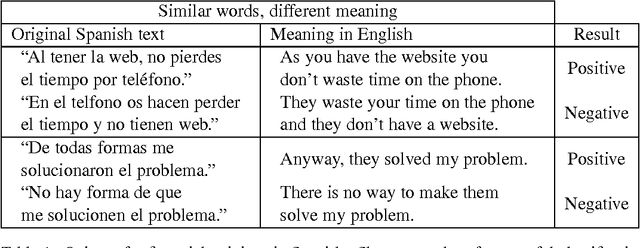
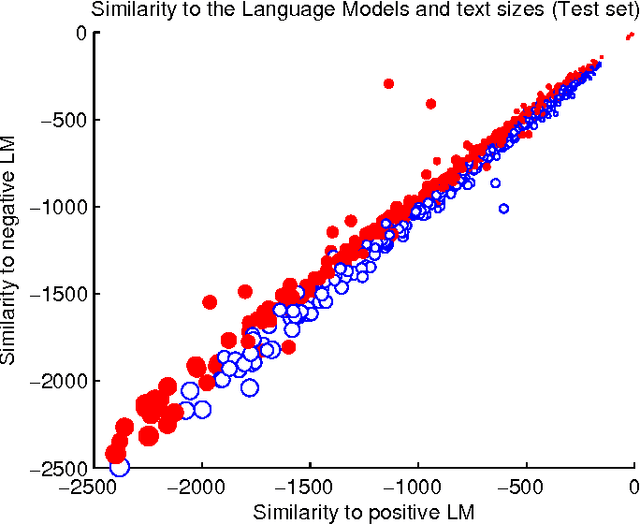

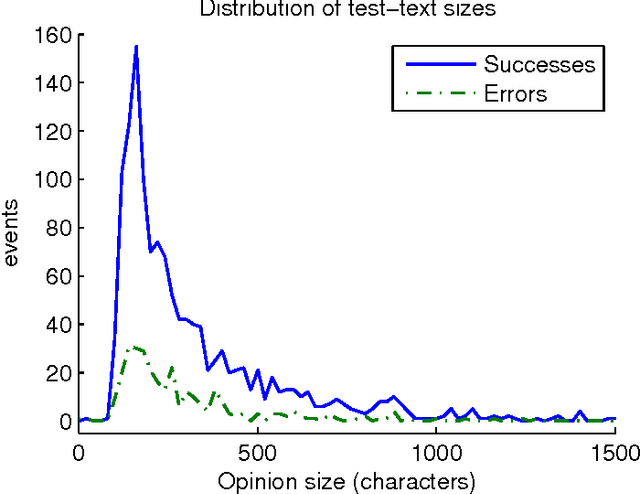
The classification of opinion texts in positive and negative is becoming a subject of great interest in sentiment analysis. The existence of many labeled opinions motivates the use of statistical and machine-learning methods. First-order statistics have proven to be very limited in this field. The Opinum approach is based on the order of the words without using any syntactic and semantic information. It consists of building one probabilistic model for the positive and another one for the negative opinions. Then the test opinions are compared to both models and a decision and confidence measure are calculated. In order to reduce the complexity of the training corpus we first lemmatize the texts and we replace most named-entities with wildcards. Opinum presents an accuracy above 81% for Spanish opinions in the financial products domain. In this work we discuss which are the most important factors that have impact on the classification performance.