 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Concepts and Compositional Voting
Nov 13, 2017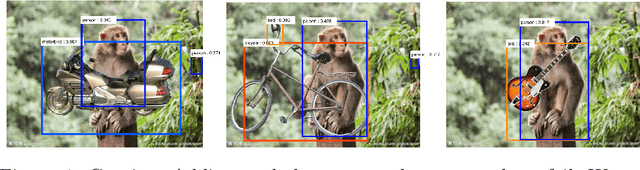
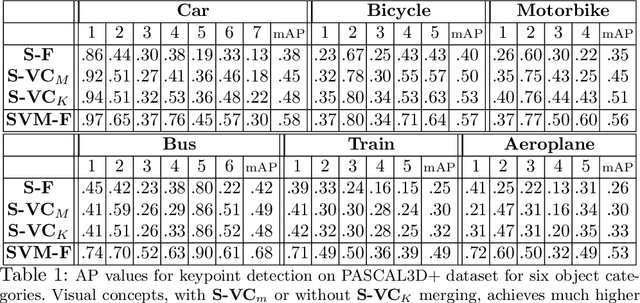

It is very attractive to formulate vision in terms of pattern theory \cite{Mumford2010pattern}, where patterns are defined hierarchically by compositions of elementary building blocks. But applying pattern theory to real world images is currently less successful than discriminative methods such as deep networks. Deep networks, however, are black-boxes which are hard to interpret and can easily be fooled by adding occluding objects. It is natural to wonder whether by better understanding deep networks we can extract building blocks which can be used to develop pattern theoretic models. This motivates us to study the internal representations of a deep network using vehicle images from the PASCAL3D+ dataset. We use clustering algorithms to study the population activities of the features and extract a set of visual concepts which we show are visually tight and correspond to semantic parts of vehicles. To analyze this we annotate these vehicles by their semantic parts to create a new dataset, VehicleSemanticParts, and evaluate visual concepts as unsupervised part detectors. We show that visual concepts perform fairly well but are outperformed by supervised discriminative methods such as Support Vector Machines (SVM). We next give a more detailed analysis of visual concepts and how they relate to semantic parts. Following this, we use the visual concepts as building blocks for a simple pattern theoretical model, which we call compositional voting. In this model several visual concepts combine to detect semantic parts. We show that this approach is significantly better than discriminative methods like SVM and deep networks trained specifically for semantic part detection. Finally, we return to studying occlusion by creating an annotated dataset with occlusion, called VehicleOcclusion, and show that compositional voting outperforms even deep networks when the amount of occlusion becomes large.
Deep Residual Learning for Instrument Segmentation in Robotic Surgery
Mar 24, 2017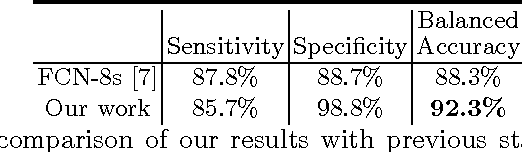

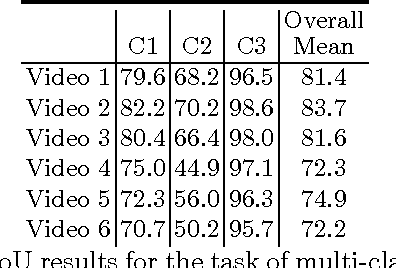
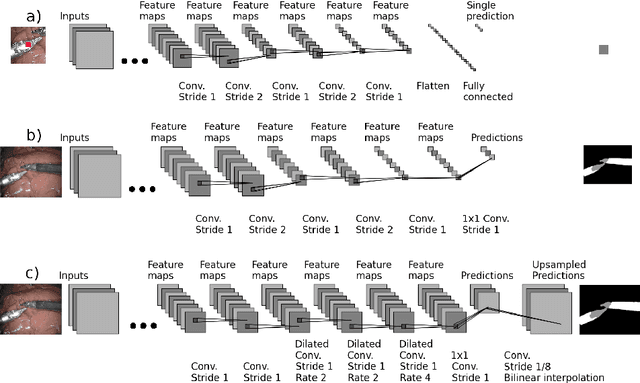
Detection, tracking, and pose estimation of surgical instruments are crucial tasks for computer assistance during minimally invasive robotic surgery. In the majority of cases, the first step is the automatic segmentation of surgical tools. Prior work has focused on binary segmentation, where the objective is to label every pixel in an image as tool or background. We improve upon previous work in two major ways. First, we leverage recent techniques such as deep residual learning and dilated convolutions to advance binary-segmentation performance. Second, we extend the approach to multi-class segmentation, which lets us segment different parts of the tool, in addition to background. We demonstrate the performance of this method on the MICCAI Endoscopic Vision Challenge Robotic Instruments dataset.
Unsupervised learning of object semantic parts from internal states of CNNs by population encoding
Nov 12, 2016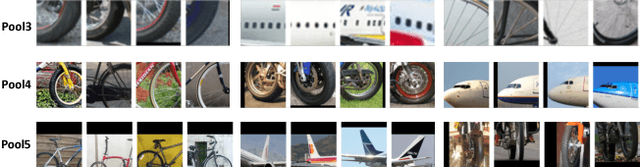
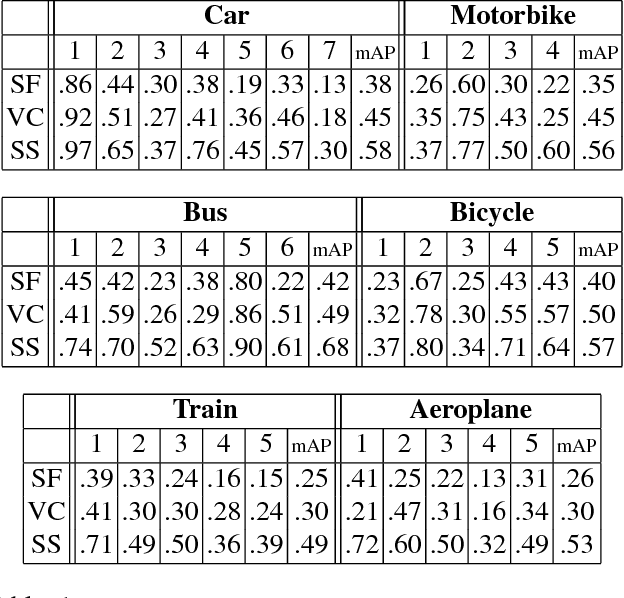

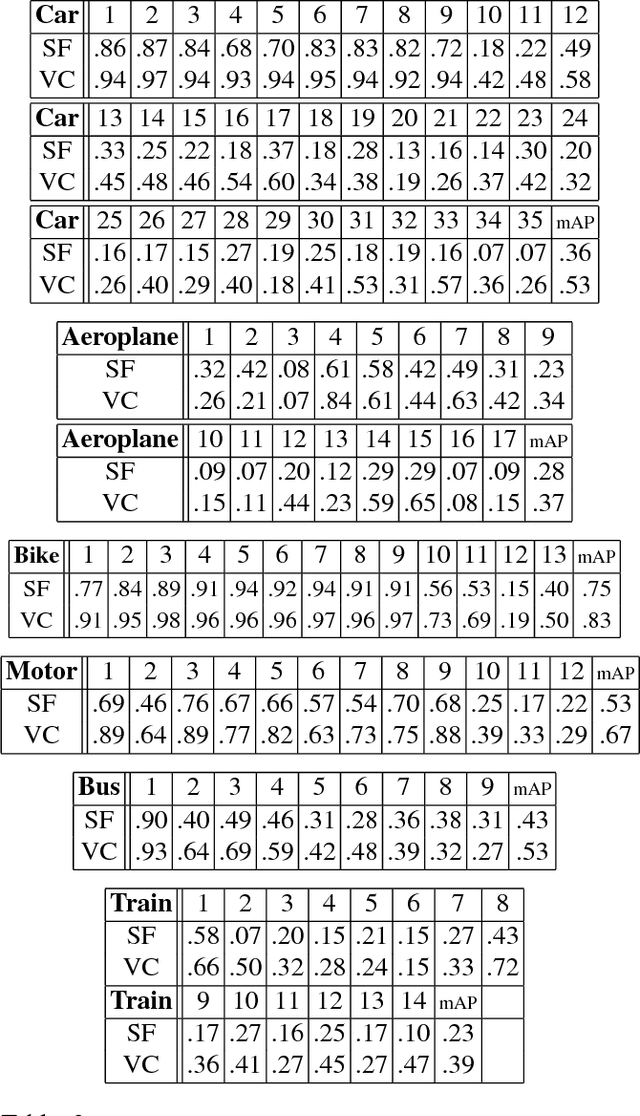
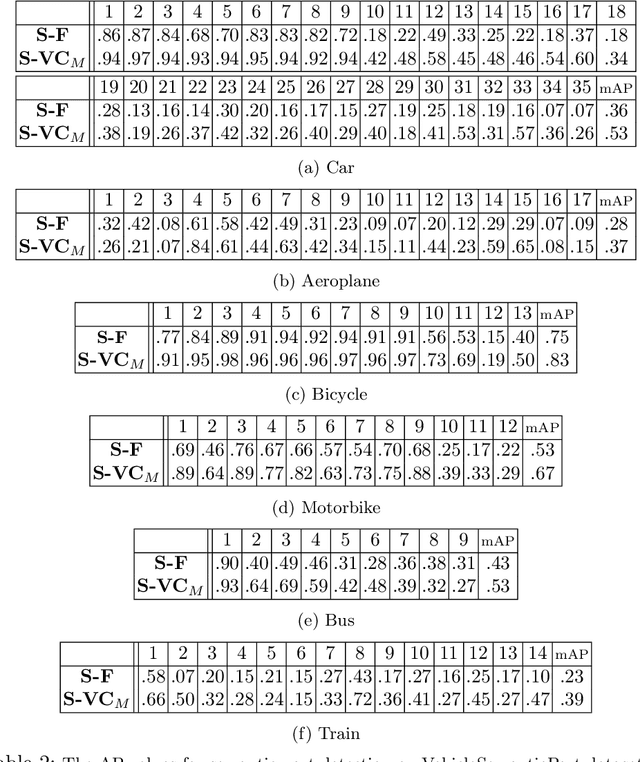
We address the key question of how object part representations can be found from the internal states of CNNs that are trained for high-level tasks, such as object classification. This work provides a new unsupervised method to learn semantic parts and gives new understanding of the internal representations of CNNs. Our technique is based on the hypothesis that semantic parts are represented by populations of neurons rather than by single filters. We propose a clustering technique to extract part representations, which we call Visual Concepts. We show that visual concepts are semantically coherent in that they represent semantic parts, and visually coherent in that corresponding image patches appear very similar. Also, visual concepts provide full spatial coverage of the parts of an object, rather than a few sparse parts as is typically found in keypoint annotations. Furthermore, We treat single visual concept as part detector and evaluate it for keypoint detection using the PASCAL3D+ dataset and for part detection using our newly annotated ImageNetPart dataset. The experiments demonstrate that visual concepts can be used to detect parts. We also show that some visual concepts respond to several semantic parts, provided these parts are visually similar. Thus visual concepts have the essential properties: semantic meaning and detection capability. Note that our ImageNetPart dataset gives rich part annotations which cover the whole object, making it useful for other part-related applications.
PASCAL Boundaries: A Class-Agnostic Semantic Boundary Dataset
Nov 25, 2015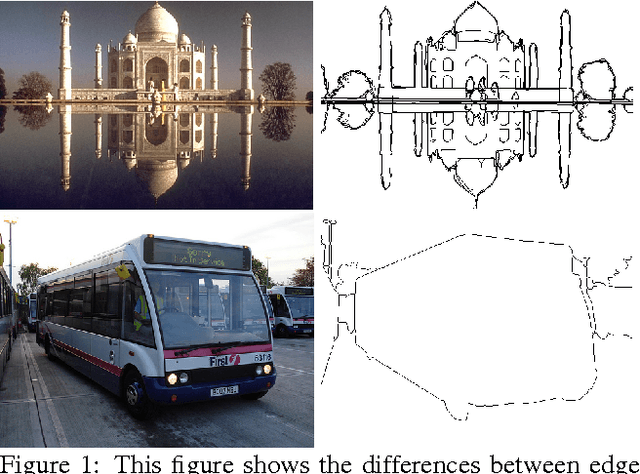
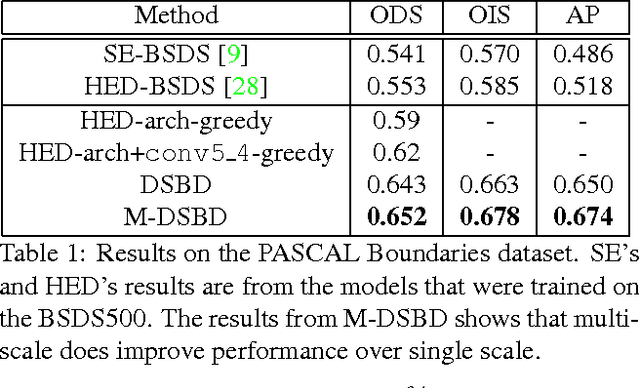
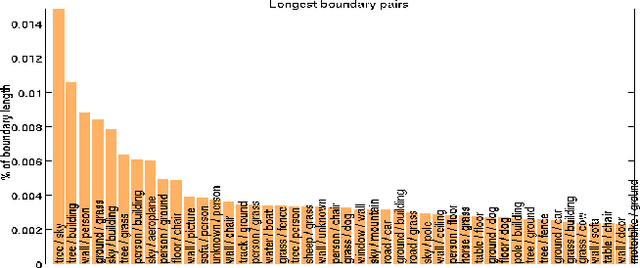

In this paper, we address the boundary detection task motivated by the ambiguities in current definition of edge detection. To this end, we generate a large database consisting of more than 10k images (which is 20x bigger than existing edge detection databases) along with ground truth boundaries between 459 semantic classes including both foreground objects and different types of background, and call it the PASCAL Boundaries dataset, which will be released to the community. In addition, we propose a novel deep network-based multi-scale semantic boundary detector and name it Multi-scale Deep Semantic Boundary Detector (M-DSBD). We provide baselines using models that were trained on edge detection and show that they transfer reasonably to the task of boundary detection. Finally, we point to various important research problems that this dataset can be used for.
Perceptually Motivated Shape Context Which Uses Shape Interiors
Dec 19, 2012


In this paper, we identify some of the limitations of current-day shape matching techniques. We provide examples of how contour-based shape matching techniques cannot provide a good match for certain visually similar shapes. To overcome this limitation, we propose a perceptually motivated variant of the well-known shape context descriptor. We identify that the interior properties of the shape play an important role in object recognition and develop a descriptor that captures these interior properties. We show that our method can easily be augmented with any other shape matching algorithm. We also show from our experiments that the use of our descriptor can significantly improve the retrieval rates.