 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Concepts and Compositional Voting
Paper and Code
Nov 13, 2017
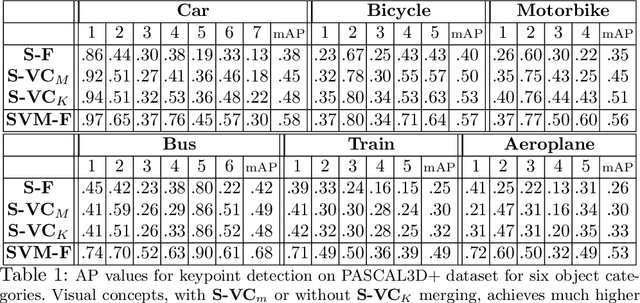

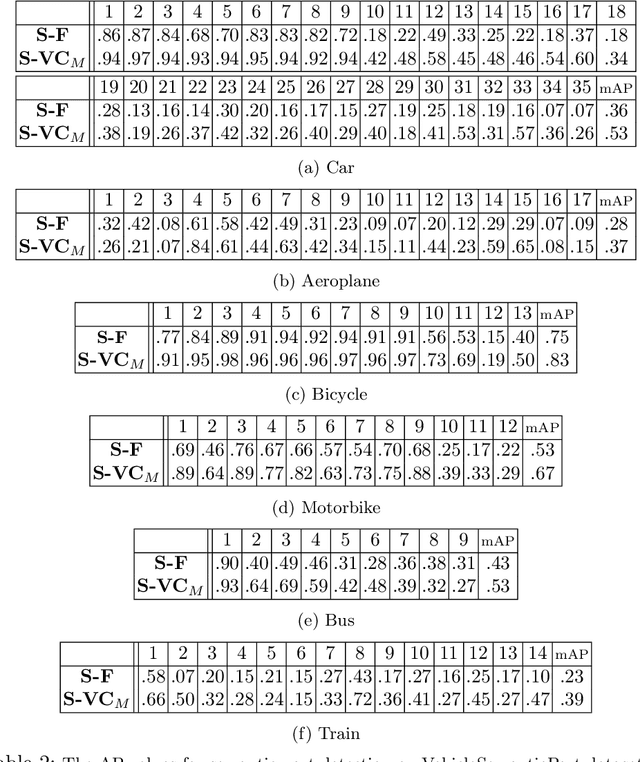
It is very attractive to formulate vision in terms of pattern theory \cite{Mumford2010pattern}, where patterns are defined hierarchically by compositions of elementary building blocks. But applying pattern theory to real world images is currently less successful than discriminative methods such as deep networks. Deep networks, however, are black-boxes which are hard to interpret and can easily be fooled by adding occluding objects. It is natural to wonder whether by better understanding deep networks we can extract building blocks which can be used to develop pattern theoretic models. This motivates us to study the internal representations of a deep network using vehicle images from the PASCAL3D+ dataset. We use clustering algorithms to study the population activities of the features and extract a set of visual concepts which we show are visually tight and correspond to semantic parts of vehicles. To analyze this we annotate these vehicles by their semantic parts to create a new dataset, VehicleSemanticParts, and evaluate visual concepts as unsupervised part detectors. We show that visual concepts perform fairly well but are outperformed by supervised discriminative methods such as Support Vector Machines (SVM). We next give a more detailed analysis of visual concepts and how they relate to semantic parts. Following this, we use the visual concepts as building blocks for a simple pattern theoretical model, which we call compositional voting. In this model several visual concepts combine to detect semantic parts. We show that this approach is significantly better than discriminative methods like SVM and deep networks trained specifically for semantic part detection. Finally, we return to studying occlusion by creating an annotated dataset with occlusion, called VehicleOcclusion, and show that compositional voting outperforms even deep networks when the amount of occlusion becomes large.