 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised learning of object semantic parts from internal states of CNNs by population encoding
Paper and Code
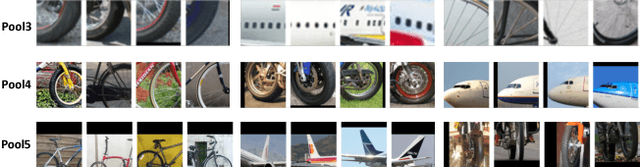
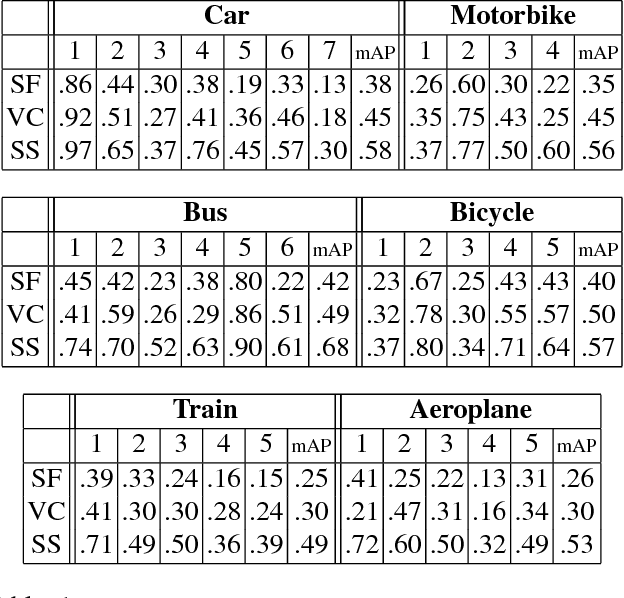

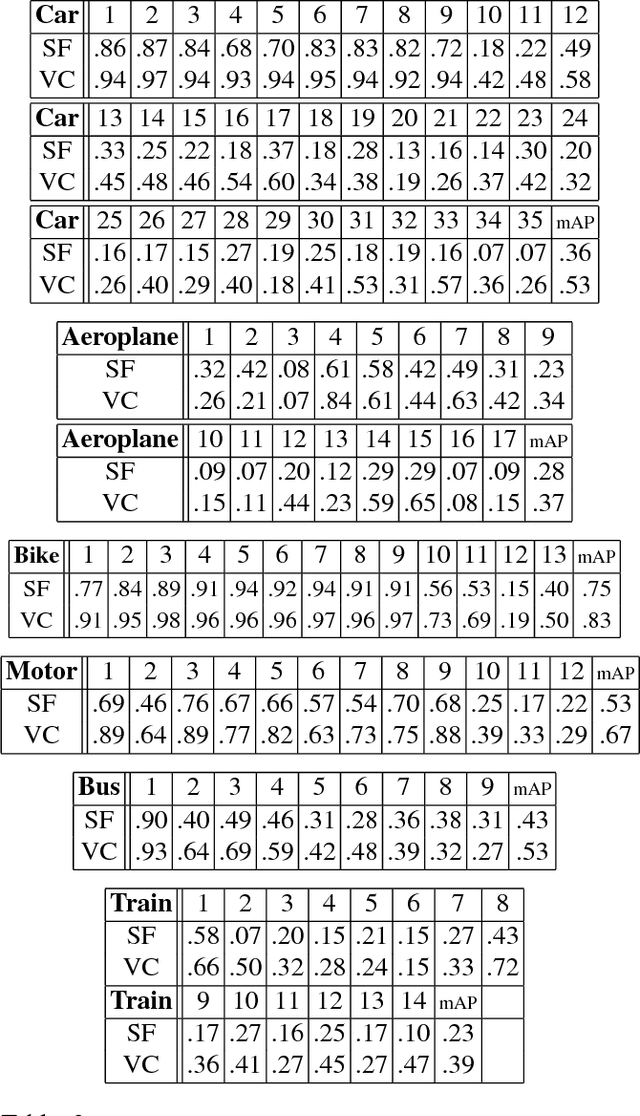
We address the key question of how object part representations can be found from the internal states of CNNs that are trained for high-level tasks, such as object classification. This work provides a new unsupervised method to learn semantic parts and gives new understanding of the internal representations of CNNs. Our technique is based on the hypothesis that semantic parts are represented by populations of neurons rather than by single filters. We propose a clustering technique to extract part representations, which we call Visual Concepts. We show that visual concepts are semantically coherent in that they represent semantic parts, and visually coherent in that corresponding image patches appear very similar. Also, visual concepts provide full spatial coverage of the parts of an object, rather than a few sparse parts as is typically found in keypoint annotations. Furthermore, We treat single visual concept as part detector and evaluate it for keypoint detection using the PASCAL3D+ dataset and for part detection using our newly annotated ImageNetPart dataset. The experiments demonstrate that visual concepts can be used to detect parts. We also show that some visual concepts respond to several semantic parts, provided these parts are visually similar. Thus visual concepts have the essential properties: semantic meaning and detection capability. Note that our ImageNetPart dataset gives rich part annotations which cover the whole object, making it useful for other part-related applications.