 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-H-Embodiment: A Large-Scale Dataset for Enabling Foundation Models in Medical Robotics
Apr 22, 2026Autonomous medical robots hold promise to improve patient outcomes, reduce provider workload, democratize access to care, and enable superhuman precision. However, autonomous medical robotics has been limited by a fundamental data problem: existing medical robotic datasets are small, single-embodiment, and rarely shared openly, restricting the development of foundation models that the field needs to advance. We introduce Open-H-Embodiment, the largest open dataset of medical robotic video with synchronized kinematics to date, spanning more than 49 institutions and multiple robotic platforms including the CMR Versius, Intuitive Surgical's da Vinci, da Vinci Research Kit (dVRK), Rob Surgical BiTrack, Virtual Incision's MIRA, Moon Surgical Maestro, and a variety of custom systems, spanning surgical manipulation, robotic ultrasound, and endoscopy procedures. We demonstrate the research enabled by this dataset through two foundation models. GR00T-H is the first open foundation vision-language-action model for medical robotics, which is the only evaluated model to achieve full end-to-end task completion on a structured suturing benchmark (25% of trials vs. 0% for all others) and achieves 64% average success across a 29-step ex vivo suturing sequence. We also train Cosmos-H-Surgical-Simulator, the first action-conditioned world model to enable multi-embodiment surgical simulation from a single checkpoint, spanning nine robotic platforms and supporting in silico policy evaluation and synthetic data generation for the medical domain. These results suggest that open, large-scale medical robot data collection can serve as critical infrastructure for the research community, enabling advances in robot learning, world modeling, and beyond.
SoftMimicGen: A Data Generation System for Scalable Robot Learning in Deformable Object Manipulation
Mar 26, 2026Large-scale robot datasets have facilitated the learning of a wide range of robot manipulation skills, but these datasets remain difficult to collect and scale further, owing to the intractable amount of human time, effort, and cost required. Simulation and synthetic data generation have proven to be an effective alternative to fuel this need for data, especially with the advent of recent work showing that such synthetic datasets can dramatically reduce real-world data requirements and facilitate generalization to novel scenarios unseen in real-world demonstrations. However, this paradigm has been limited to rigid-body tasks, which are easy to simulate. Deformable object manipulation encompasses a large portion of real-world manipulation and remains a crucial gap to address towards increasing adoption of the synthetic simulation data paradigm. In this paper, we introduce SoftMimicGen, an automated data generation pipeline for deformable object manipulation tasks. We introduce a suite of high-fidelity simulation environments that encompasses a wide range of deformable objects (stuffed animal, rope, tissue, towel) and manipulation behaviors (high-precision threading, dynamic whipping, folding, pick-and-place), across four robot embodiments: a single-arm manipulator, bimanual arms, a humanoid, and a surgical robot. We apply SoftMimicGen to generate datasets across the task suite, train high-performing policies from the data, and systematically analyze the data generation system. Project website: \href{https://softmimicgen.github.io}{softmimicgen.github.io}.
SuFIA-BC: Generating High Quality Demonstration Data for Visuomotor Policy Learning in Surgical Subtasks
Apr 21, 2025



Behavior cloning facilitates the learning of dexterous manipulation skills, yet the complexity of surgical environments, the difficulty and expense of obtaining patient data, and robot calibration errors present unique challenges for surgical robot learning. We provide an enhanced surgical digital twin with photorealistic human anatomical organs, integrated into a comprehensive simulator designed to generate high-quality synthetic data to solve fundamental tasks in surgical autonomy. We present SuFIA-BC: visual Behavior Cloning policies for Surgical First Interactive Autonomy Assistants. We investigate visual observation spaces including multi-view cameras and 3D visual representations extracted from a single endoscopic camera view. Through systematic evaluation, we find that the diverse set of photorealistic surgical tasks introduced in this work enables a comprehensive evaluation of prospective behavior cloning models for the unique challenges posed by surgical environments. We observe that current state-of-the-art behavior cloning techniques struggle to solve the contact-rich and complex tasks evaluated in this work, regardless of their underlying perception or control architectures. These findings highlight the importance of customizing perception pipelines and control architectures, as well as curating larger-scale synthetic datasets that meet the specific demands of surgical tasks. Project website: https://orbit-surgical.github.io/sufia-bc/
SuFIA: Language-Guided Augmented Dexterity for Robotic Surgical Assistants
May 08, 2024



In this work, we present SuFIA, the first framework for natural language-guided augmented dexterity for robotic surgical assistants. SuFIA incorporates the strong reasoning capabilities of large language models (LLMs) with perception modules to implement high-level planning and low-level control of a robot for surgical sub-task execution. This enables a learning-free approach to surgical augmented dexterity without any in-context examples or motion primitives. SuFIA uses a human-in-the-loop paradigm by restoring control to the surgeon in the case of insufficient information, mitigating unexpected errors for mission-critical tasks. We evaluate SuFIA on four surgical sub-tasks in a simulation environment and two sub-tasks on a physical surgical robotic platform in the lab, demonstrating its ability to perform common surgical sub-tasks through supervised autonomous operation under challenging physical and workspace conditions. Project website: orbit-surgical.github.io/sufia
Towards Deterministic End-to-end Latency for Medical AI Systems in NVIDIA Holoscan
Feb 06, 2024
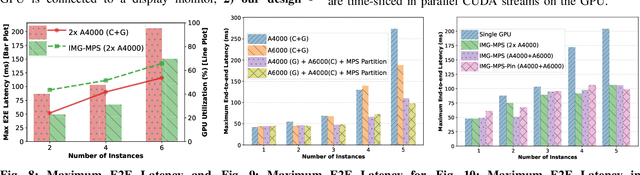


The introduction of AI and ML technologies into medical devices has revolutionized healthcare diagnostics and treatments. Medical device manufacturers are keen to maximize the advantages afforded by AI and ML by consolidating multiple applications onto a single platform. However, concurrent execution of several AI applications, each with its own visualization components, leads to unpredictable end-to-end latency, primarily due to GPU resource contentions. To mitigate this, manufacturers typically deploy separate workstations for distinct AI applications, thereby increasing financial, energy, and maintenance costs. This paper addresses these challenges within the context of NVIDIA's Holoscan platform, a real-time AI system for streaming sensor data and images. We propose a system design optimized for heterogeneous GPU workloads, encompassing both compute and graphics tasks. Our design leverages CUDA MPS for spatial partitioning of compute workloads and isolates compute and graphics processing onto separate GPUs. We demonstrate significant performance improvements across various end-to-end latency determinism metrics through empirical evaluation with real-world Holoscan medical device applications. For instance, the proposed design reduces maximum latency by 21-30% and improves latency distribution flatness by 17-25% for up to five concurrent endoscopy tool tracking AI applications, compared to a single-GPU baseline. Against a default multi-GPU setup, our optimizations decrease maximum latency by 35% for up to six concurrent applications by improving GPU utilization by 42%. This paper provides clear design insights for AI applications in the edge-computing domain including medical systems, where performance predictability of concurrent and heterogeneous GPU workloads is a critical requirement.
Learning Invariant Representation of Tasks for Robust Surgical State Estimation
Feb 18, 2021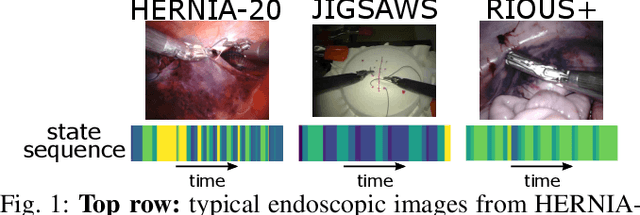
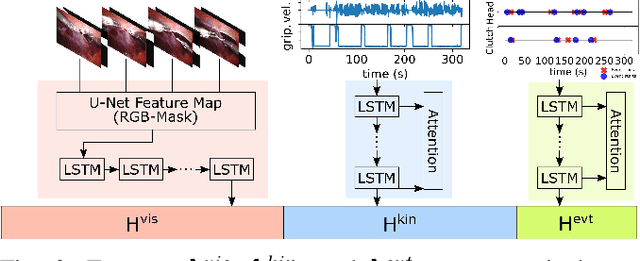
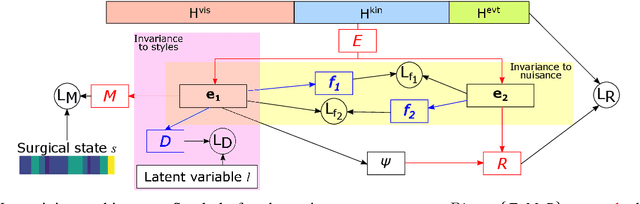
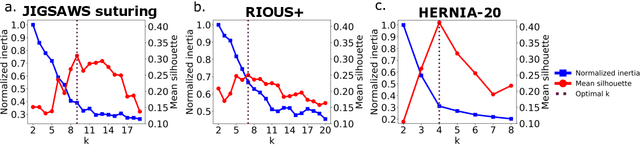
Surgical state estimators in robot-assisted surgery (RAS) - especially those trained via learning techniques - rely heavily on datasets that capture surgeon actions in laboratory or real-world surgical tasks. Real-world RAS datasets are costly to acquire, are obtained from multiple surgeons who may use different surgical strategies, and are recorded under uncontrolled conditions in highly complex environments. The combination of high diversity and limited data calls for new learning methods that are robust and invariant to operating conditions and surgical techniques. We propose StiseNet, a Surgical Task Invariance State Estimation Network with an invariance induction framework that minimizes the effects of variations in surgical technique and operating environments inherent to RAS datasets. StiseNet's adversarial architecture learns to separate nuisance factors from information needed for surgical state estimation. StiseNet is shown to outperform state-of-the-art state estimation methods on three datasets (including a new real-world RAS dataset: HERNIA-20).
Stereo Correspondence and Reconstruction of Endoscopic Data Challenge
Jan 28, 2021

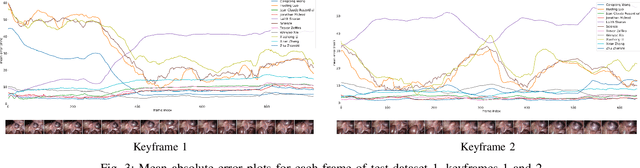
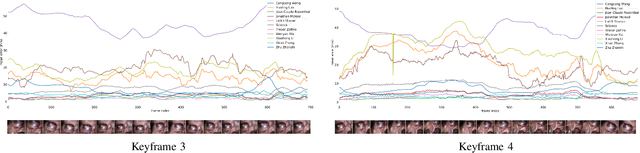
The stereo correspondence and reconstruction of endoscopic data sub-challenge was organized during the Endovis challenge at MICCAI 2019 in Shenzhen, China. The task was to perform dense depth estimation using 7 training datasets and 2 test sets of structured light data captured using porcine cadavers. These were provided by a team at Intuitive Surgical. 10 teams participated in the challenge day. This paper contains 3 additional methods which were submitted after the challenge finished as well as a supplemental section from these teams on issues they found with the dataset.
daVinciNet: Joint Prediction of Motion and Surgical State in Robot-Assisted Surgery
Sep 24, 2020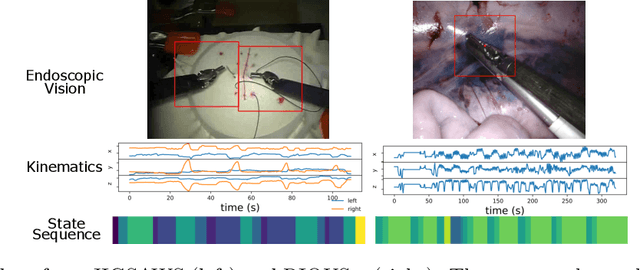
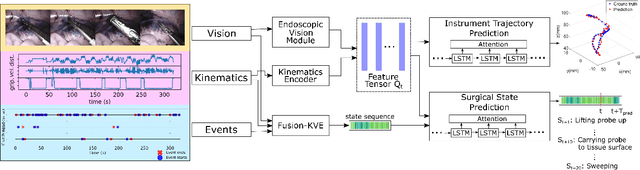
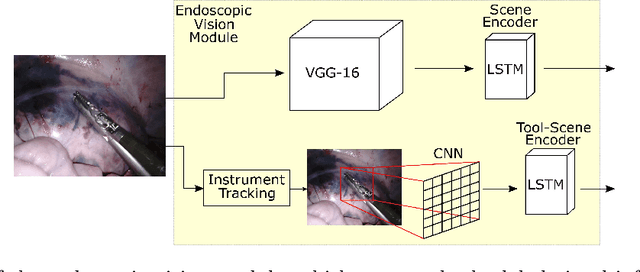
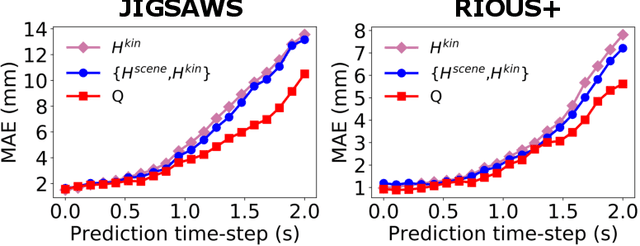
This paper presents a technique to concurrently and jointly predict the future trajectories of surgical instruments and the future state(s) of surgical subtasks in robot-assisted surgeries (RAS) using multiple input sources. Such predictions are a necessary first step towards shared control and supervised autonomy of surgical subtasks. Minute-long surgical subtasks, such as suturing or ultrasound scanning, often have distinguishable tool kinematics and visual features, and can be described as a series of fine-grained states with transition schematics. We propose daVinciNet - an end-to-end dual-task model for robot motion and surgical state predictions. daVinciNet performs concurrent end-effector trajectory and surgical state predictions using features extracted from multiple data streams, including robot kinematics, endoscopic vision, and system events. We evaluate our proposed model on an extended Robotic Intra-Operative Ultrasound (RIOUS+) imaging dataset collected on a da Vinci Xi surgical system and the JHU-ISI Gesture and Skill Assessment Working Set (JIGSAWS). Our model achieves up to 93.85% short-term (0.5s) and 82.11% long-term (2s) state prediction accuracy, as well as 1.07mm short-term and 5.62mm long-term trajectory prediction error.
Temporal Segmentation of Surgical Sub-tasks through Deep Learning with Multiple Data Sources
Feb 07, 2020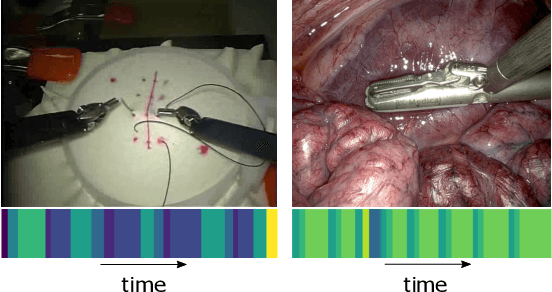

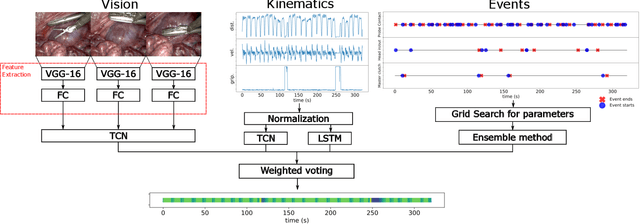
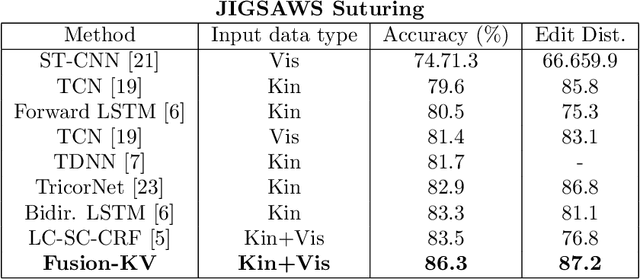
Many tasks in robot-assisted surgeries (RAS) can be represented by finite-state machines (FSMs), where each state represents either an action (such as picking up a needle) or an observation (such as bleeding). A crucial step towards the automation of such surgical tasks is the temporal perception of the current surgical scene, which requires a real-time estimation of the states in the FSMs. The objective of this work is to estimate the current state of the surgical task based on the actions performed or events occurred as the task progresses. We propose Fusion-KVE, a unified surgical state estimation model that incorporates multiple data sources including the Kinematics, Vision, and system Events. Additionally, we examine the strengths and weaknesses of different state estimation models in segmenting states with different representative features or levels of granularity. We evaluate our model on the JHU-ISI Gesture and Skill Assessment Working Set (JIGSAWS), as well as a more complex dataset involving robotic intra-operative ultrasound (RIOUS) imaging, created using the da Vinci Xi surgical system. Our model achieves a superior frame-wise state estimation accuracy up to 89.4%, which improves the state-of-the-art surgical state estimation models in both JIGSAWS suturing dataset and our RIOUS dataset.
2018 Robotic Scene Segmentation Challenge
Feb 03, 2020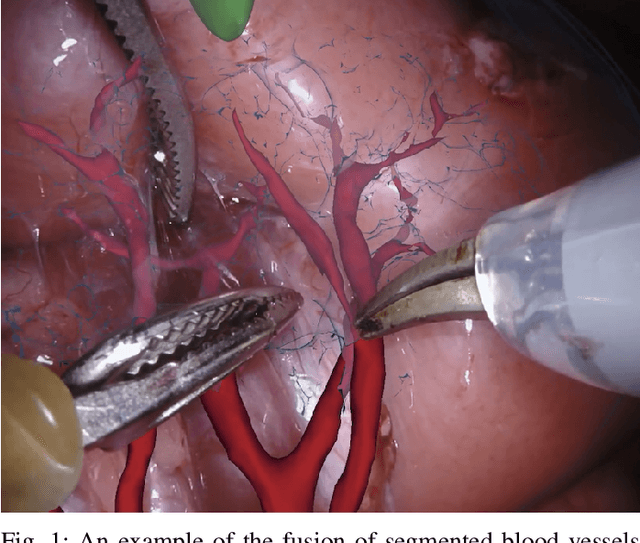
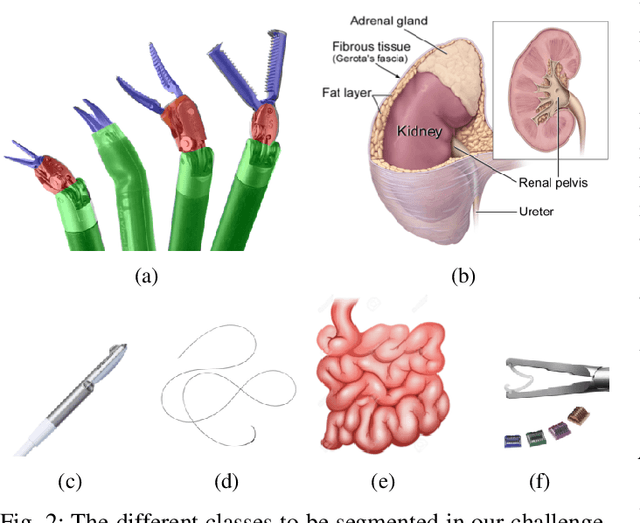
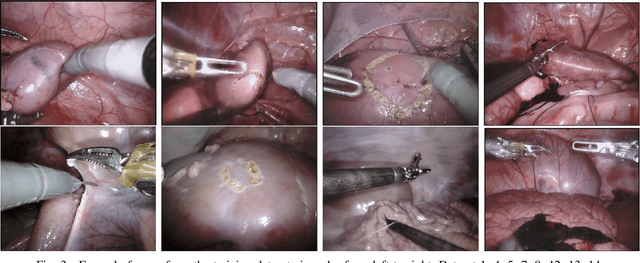
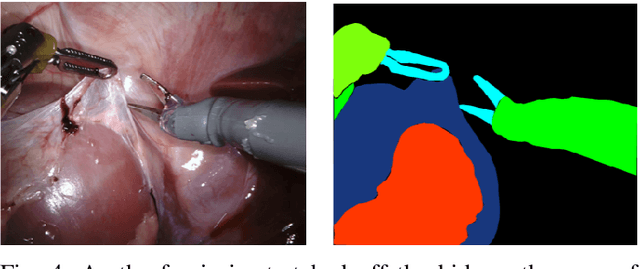
In 2015 we began a sub-challenge at the EndoVis workshop at MICCAI in Munich using endoscope images of ex-vivo tissue with automatically generated annotations from robot forward kinematics and instrument CAD models. However, the limited background variation and simple motion rendered the dataset uninformative in learning about which techniques would be suitable for segmentation in real surgery. In 2017, at the same workshop in Quebec we introduced the robotic instrument segmentation dataset with 10 teams participating in the challenge to perform binary, articulating parts and type segmentation of da Vinci instruments. This challenge included realistic instrument motion and more complex porcine tissue as background and was widely addressed with modifications on U-Nets and other popular CNN architectures. In 2018 we added to the complexity by introducing a set of anatomical objects and medical devices to the segmented classes. To avoid over-complicating the challenge, we continued with porcine data which is dramatically simpler than human tissue due to the lack of fatty tissue occluding many organs.