 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Invariant Representation of Tasks for Robust Surgical State Estimation
Feb 18, 2021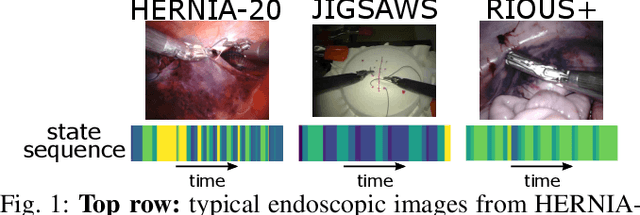
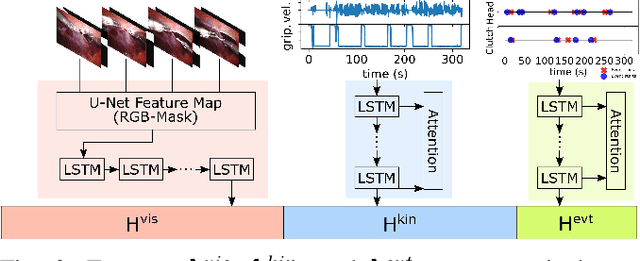
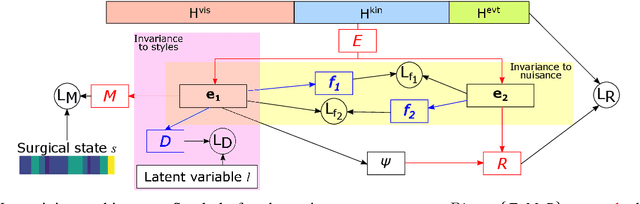
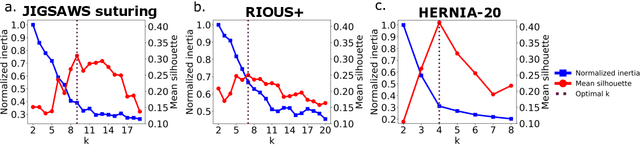
Surgical state estimators in robot-assisted surgery (RAS) - especially those trained via learning techniques - rely heavily on datasets that capture surgeon actions in laboratory or real-world surgical tasks. Real-world RAS datasets are costly to acquire, are obtained from multiple surgeons who may use different surgical strategies, and are recorded under uncontrolled conditions in highly complex environments. The combination of high diversity and limited data calls for new learning methods that are robust and invariant to operating conditions and surgical techniques. We propose StiseNet, a Surgical Task Invariance State Estimation Network with an invariance induction framework that minimizes the effects of variations in surgical technique and operating environments inherent to RAS datasets. StiseNet's adversarial architecture learns to separate nuisance factors from information needed for surgical state estimation. StiseNet is shown to outperform state-of-the-art state estimation methods on three datasets (including a new real-world RAS dataset: HERNIA-20).
daVinciNet: Joint Prediction of Motion and Surgical State in Robot-Assisted Surgery
Sep 24, 2020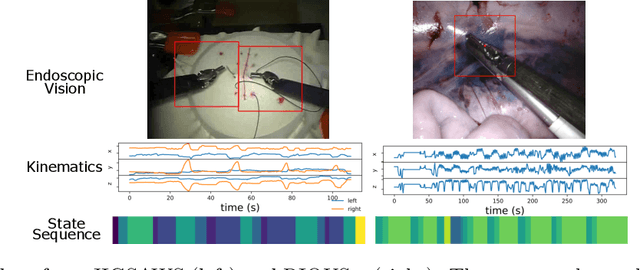
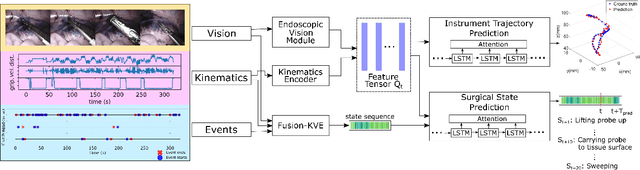
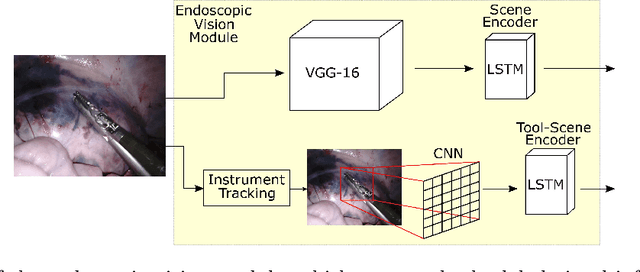
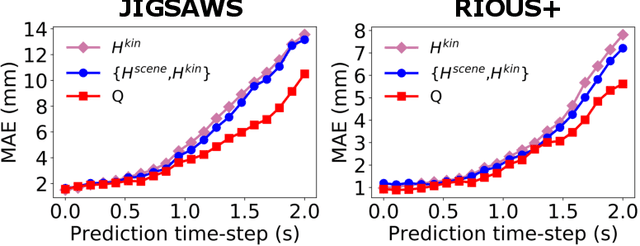
This paper presents a technique to concurrently and jointly predict the future trajectories of surgical instruments and the future state(s) of surgical subtasks in robot-assisted surgeries (RAS) using multiple input sources. Such predictions are a necessary first step towards shared control and supervised autonomy of surgical subtasks. Minute-long surgical subtasks, such as suturing or ultrasound scanning, often have distinguishable tool kinematics and visual features, and can be described as a series of fine-grained states with transition schematics. We propose daVinciNet - an end-to-end dual-task model for robot motion and surgical state predictions. daVinciNet performs concurrent end-effector trajectory and surgical state predictions using features extracted from multiple data streams, including robot kinematics, endoscopic vision, and system events. We evaluate our proposed model on an extended Robotic Intra-Operative Ultrasound (RIOUS+) imaging dataset collected on a da Vinci Xi surgical system and the JHU-ISI Gesture and Skill Assessment Working Set (JIGSAWS). Our model achieves up to 93.85% short-term (0.5s) and 82.11% long-term (2s) state prediction accuracy, as well as 1.07mm short-term and 5.62mm long-term trajectory prediction error.
Temporal Segmentation of Surgical Sub-tasks through Deep Learning with Multiple Data Sources
Feb 07, 2020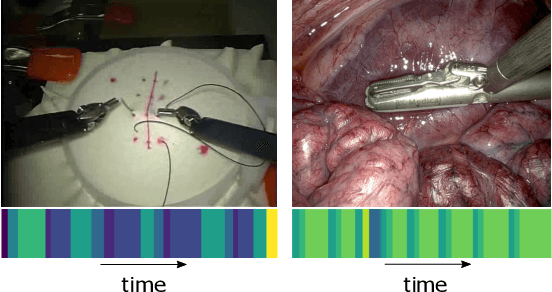

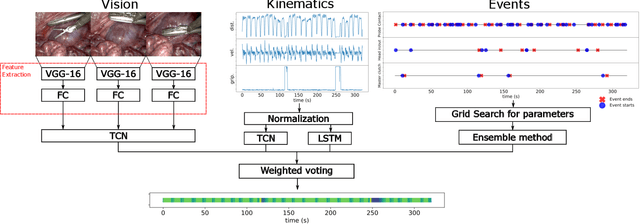
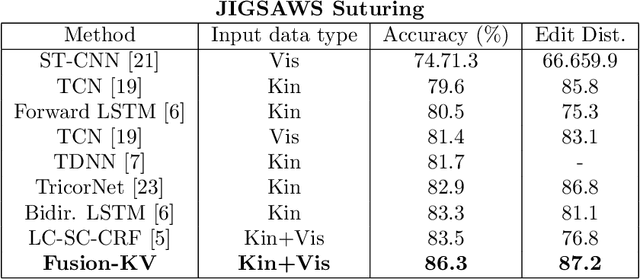
Many tasks in robot-assisted surgeries (RAS) can be represented by finite-state machines (FSMs), where each state represents either an action (such as picking up a needle) or an observation (such as bleeding). A crucial step towards the automation of such surgical tasks is the temporal perception of the current surgical scene, which requires a real-time estimation of the states in the FSMs. The objective of this work is to estimate the current state of the surgical task based on the actions performed or events occurred as the task progresses. We propose Fusion-KVE, a unified surgical state estimation model that incorporates multiple data sources including the Kinematics, Vision, and system Events. Additionally, we examine the strengths and weaknesses of different state estimation models in segmenting states with different representative features or levels of granularity. We evaluate our model on the JHU-ISI Gesture and Skill Assessment Working Set (JIGSAWS), as well as a more complex dataset involving robotic intra-operative ultrasound (RIOUS) imaging, created using the da Vinci Xi surgical system. Our model achieves a superior frame-wise state estimation accuracy up to 89.4%, which improves the state-of-the-art surgical state estimation models in both JIGSAWS suturing dataset and our RIOUS dataset.