 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstrained hybrid modelling to predict microbial dynamics and organic matter turnover in soil systems
Jun 18, 2026Soil microorganisms control organic matter cycling and largely determine how soil systems can cope with and mitigate climate change and environmental threats. Representing microbial dynamics in process-based soil models is therefore critical to predict carbon cycling in soils, albeit highly challenging to inform from data. One promising approach to improve their parametrisation is the integration of genomic data, yet modelling the complex and unknown relationship between genomes and the processes the microbes are driving is an unsolved problem. In this work, we present the first hybrid modeling framework for deriving biokinetic parameter values of a process-based soil organic matter turnover model from metagenome-inferred functional traits based on DNA sequencing data. Our model predicts biokinetic parameters of the process-based model from genomic trait data with a neural network and integrates constraints from ecological theory and literature to ensure realistic behavior, even of non-observed state variables. We evaluate our method on synthetic genomic trait datasets of varying complexity and on real data, showing that our approach improves performance over multiple baselines and learns the dynamics of unmeasurable components of the process-based model effectively, even for small training datasets.
TRAFA: Anticipating User Actions to Reduce Errors in Procedural Tasks with Predictive Feedback
May 23, 2026Interactive assistance systems typically provide feedback after an action has been completed, supporting error recovery but not preventing the error itself. We present TRAFA, a real-time predictive feedback system for procedural tasks that intervenes before errors are committed. TRAFA operationalizes predictive feedback through a Track-Forecast-Act framework that tracks hand and object state, forecasts user motion conditioned on scene context, and triggers feedback when a predicted action is likely to violate task constraints. We instantiate this pipeline in a sequential assembly setting and evaluate it through both technical benchmarking and a controlled user study against conventional reactive feedback. Our results show that predictive feedback improves task accuracy and efficiency while maintaining a comparable number of feedback events. These findings position feedback timing as a key dimension in system design and show how real-time anticipation can be integrated into interactive systems to prevent errors before they occur.
Inferring geometry and material properties from Mueller matrices with machine learning
Aug 27, 2025Mueller matrices (MMs) encode information on geometry and material properties, but recovering both simultaneously is an ill-posed problem. We explore whether MMs contain sufficient information to infer surface geometry and material properties with machine learning. We use a dataset of spheres of various isotropic materials, with MMs captured over the full angular domain at five visible wavelengths (450-650 nm). We train machine learning models to predict material properties and surface normals using only these MMs as input. We demonstrate that, even when the material type is unknown, surface normals can be predicted and object geometry reconstructed. Moreover, MMs allow models to identify material types correctly. Further analyses show that diagonal elements are key for material characterization, and off-diagonal elements are decisive for normal estimation.
Non-Linear Outlier Synthesis for Out-of-Distribution Detection
Nov 20, 2024



The reliability of supervised classifiers is severely hampered by their limitations in dealing with unexpected inputs, leading to great interest in out-of-distribution (OOD) detection. Recently, OOD detectors trained on synthetic outliers, especially those generated by large diffusion models, have shown promising results in defining robust OOD decision boundaries. Building on this progress, we present NCIS, which enhances the quality of synthetic outliers by operating directly in the diffusion's model embedding space rather than combining disjoint models as in previous work and by modeling class-conditional manifolds with a conditional volume-preserving network for more expressive characterization of the training distribution. We demonstrate that these improvements yield new state-of-the-art OOD detection results on standard ImageNet100 and CIFAR100 benchmarks and provide insights into the importance of data pre-processing and other key design choices. We make our code available at \url{https://github.com/LarsDoorenbos/NCIS}.
Learning Non-Linear Invariants for Unsupervised Out-of-Distribution Detection
Jul 04, 2024



The inability of deep learning models to handle data drawn from unseen distributions has sparked much interest in unsupervised out-of-distribution (U-OOD) detection, as it is crucial for reliable deep learning models. Despite considerable attention, theoretically-motivated approaches are few and far between, with most methods building on top of some form of heuristic. Recently, U-OOD was formalized in the context of data invariants, allowing a clearer understanding of how to characterize U-OOD, and methods leveraging affine invariants have attained state-of-the-art results on large-scale benchmarks. Nevertheless, the restriction to affine invariants hinders the expressiveness of the approach. In this work, we broaden the affine invariants formulation to a more general case and propose a framework consisting of a normalizing flow-like architecture capable of learning non-linear invariants. Our novel approach achieves state-of-the-art results on an extensive U-OOD benchmark, and we demonstrate its further applicability to tabular data. Finally, we show our method has the same desirable properties as those based on affine invariants.
Galaxy spectroscopy without spectra: Galaxy properties from photometric images with conditional diffusion models
Jun 26, 2024



Modern spectroscopic surveys can only target a small fraction of the vast amount of photometrically cataloged sources in wide-field surveys. Here, we report the development of a generative AI method capable of predicting optical galaxy spectra from photometric broad-band images alone. This method draws from the latest advances in diffusion models in combination with contrastive networks. We pass multi-band galaxy images into the architecture to obtain optical spectra. From these, robust values for galaxy properties can be derived with any methods in the spectroscopic toolbox, such as standard population synthesis techniques and Lick indices. When trained and tested on 64x64-pixel images from the Sloan Digital Sky Survey, the global bimodality of star-forming and quiescent galaxies in photometric space is recovered, as well as a mass-metallicity relation of star-forming galaxies. The comparison between the observed and the artificially created spectra shows good agreement in overall metallicity, age, Dn4000, stellar velocity dispersion, and E(B-V) values. Photometric redshift estimates of our generative algorithm can compete with other current, specialized deep-learning techniques. Moreover, this work is the first attempt in the literature to infer velocity dispersion from photometric images. Additionally, we can predict the presence of an active galactic nucleus up to an accuracy of 82%. With our method, scientifically interesting galaxy properties, normally requiring spectroscopic inputs, can be obtained in future data sets from large-scale photometric surveys alone. The spectra prediction via AI can further assist in creating realistic mock catalogs.
Continual Unsupervised Out-of-Distribution Detection
Jun 04, 2024



Deep learning models excel when the data distribution during training aligns with testing data. Yet, their performance diminishes when faced with out-of-distribution (OOD) samples, leading to great interest in the field of OOD detection. Current approaches typically assume that OOD samples originate from an unconcentrated distribution complementary to the training distribution. While this assumption is appropriate in the traditional unsupervised OOD (U-OOD) setting, it proves inadequate when considering the place of deployment of the underlying deep learning model. To better reflect this real-world scenario, we introduce the novel setting of continual U-OOD detection. To tackle this new setting, we propose a method that starts from a U-OOD detector, which is agnostic to the OOD distribution, and slowly updates during deployment to account for the actual OOD distribution. Our method uses a new U-OOD scoring function that combines the Mahalanobis distance with a nearest-neighbor approach. Furthermore, we design a confidence-scaled few-shot OOD detector that outperforms previous methods. We show our method greatly improves upon strong baselines from related fields.
SuFIA: Language-Guided Augmented Dexterity for Robotic Surgical Assistants
May 08, 2024



In this work, we present SuFIA, the first framework for natural language-guided augmented dexterity for robotic surgical assistants. SuFIA incorporates the strong reasoning capabilities of large language models (LLMs) with perception modules to implement high-level planning and low-level control of a robot for surgical sub-task execution. This enables a learning-free approach to surgical augmented dexterity without any in-context examples or motion primitives. SuFIA uses a human-in-the-loop paradigm by restoring control to the surgeon in the case of insufficient information, mitigating unexpected errors for mission-critical tasks. We evaluate SuFIA on four surgical sub-tasks in a simulation environment and two sub-tasks on a physical surgical robotic platform in the lab, demonstrating its ability to perform common surgical sub-tasks through supervised autonomous operation under challenging physical and workspace conditions. Project website: orbit-surgical.github.io/sufia
Hyperbolic Random Forests
Aug 25, 2023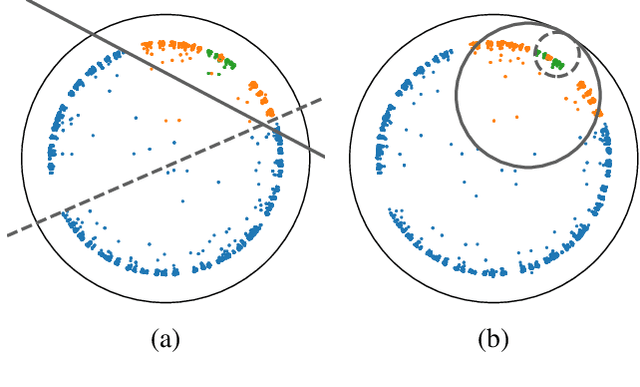
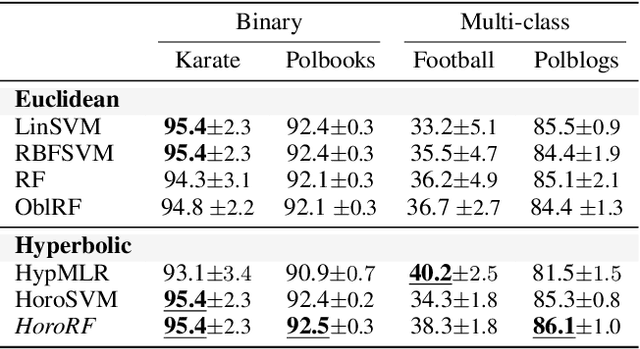
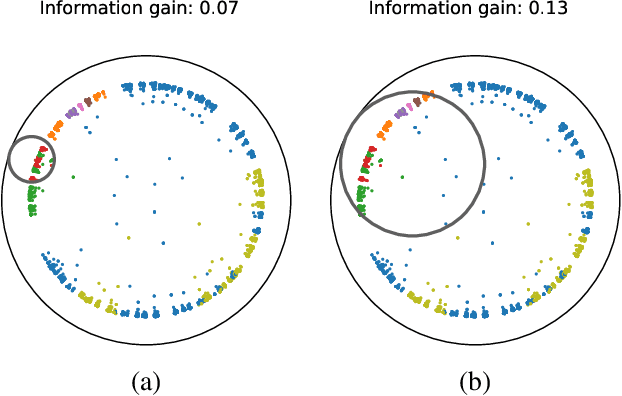
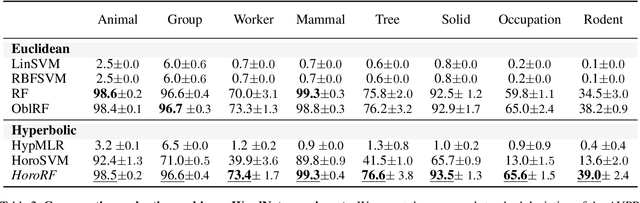
Hyperbolic space is becoming a popular choice for representing data due to the hierarchical structure - whether implicit or explicit - of many real-world datasets. Along with it comes a need for algorithms capable of solving fundamental tasks, such as classification, in hyperbolic space. Recently, multiple papers have investigated hyperbolic alternatives to hyperplane-based classifiers, such as logistic regression and SVMs. While effective, these approaches struggle with more complex hierarchical data. We, therefore, propose to generalize the well-known random forests to hyperbolic space. We do this by redefining the notion of a split using horospheres. Since finding the globally optimal split is computationally intractable, we find candidate horospheres through a large-margin classifier. To make hyperbolic random forests work on multi-class data and imbalanced experiments, we furthermore outline a new method for combining classes based on their lowest common ancestor and a class-balanced version of the large-margin loss. Experiments on standard and new benchmarks show that our approach outperforms both conventional random forest algorithms and recent hyperbolic classifiers.
Unsupervised out-of-distribution detection for safer robotically guided retinal microsurgery
May 03, 2023Purpose: A fundamental problem in designing safe machine learning systems is identifying when samples presented to a deployed model differ from those observed at training time. Detecting so-called out-of-distribution (OoD) samples is crucial in safety-critical applications such as robotically guided retinal microsurgery, where distances between the instrument and the retina are derived from sequences of 1D images that are acquired by an instrument-integrated optical coherence tomography (iiOCT) probe. Methods: This work investigates the feasibility of using an OoD detector to identify when images from the iiOCT probe are inappropriate for subsequent machine learning-based distance estimation. We show how a simple OoD detector based on the Mahalanobis distance can successfully reject corrupted samples coming from real-world ex vivo porcine eyes. Results: Our results demonstrate that the proposed approach can successfully detect OoD samples and help maintain the performance of the downstream task within reasonable levels. MahaAD outperformed a supervised approach trained on the same kind of corruptions and achieved the best performance in detecting OoD cases from a collection of iiOCT samples with real-world corruptions. Conclusion: The results indicate that detecting corrupted iiOCT data through OoD detection is feasible and does not need prior knowledge of possible corruptions. Consequently, MahaAD could aid in ensuring patient safety during robotically guided microsurgery by preventing deployed prediction models from estimating distances that put the patient at risk.