 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Multi-Agent Reinforcement Learning for Unrelated Parallel Machine Scheduling
Nov 12, 2024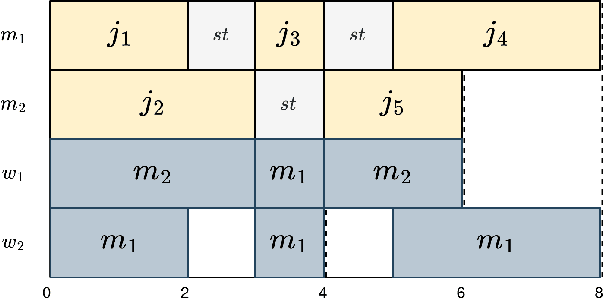



Scheduling problems pose significant challenges in resource, industry, and operational management. This paper addresses the Unrelated Parallel Machine Scheduling Problem (UPMS) with setup times and resources using a Multi-Agent Reinforcement Learning (MARL) approach. The study introduces the Reinforcement Learning environment and conducts empirical analyses, comparing MARL with Single-Agent algorithms. The experiments employ various deep neural network policies for single- and Multi-Agent approaches. Results demonstrate the efficacy of the Maskable extension of the Proximal Policy Optimization (PPO) algorithm in Single-Agent scenarios and the Multi-Agent PPO algorithm in Multi-Agent setups. While Single-Agent algorithms perform adequately in reduced scenarios, Multi-Agent approaches reveal challenges in cooperative learning but a scalable capacity. This research contributes insights into applying MARL techniques to scheduling optimization, emphasizing the need for algorithmic sophistication balanced with scalability for intelligent scheduling solutions.
AMBER -- Advanced SegFormer for Multi-Band Image Segmentation: an application to Hyperspectral Imaging
Sep 14, 2024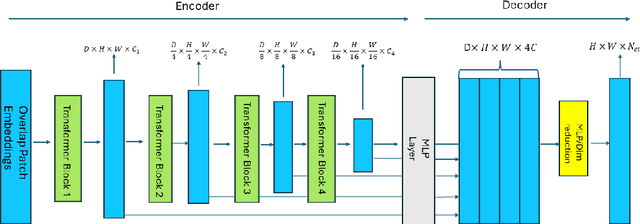



Deep learning has revolutionized the field of hyperspectral image (HSI) analysis, enabling the extraction of complex and hierarchical features. While convolutional neural networks (CNNs) have been the backbone of HSI classification, their limitations in capturing global contextual features have led to the exploration of Vision Transformers (ViTs). This paper introduces AMBER, an advanced SegFormer specifically designed for multi-band image segmentation. AMBER enhances the original SegFormer by incorporating three-dimensional convolutions to handle hyperspectral data. Our experiments, conducted on the Indian Pines, Pavia University, and PRISMA datasets, show that AMBER outperforms traditional CNN-based methods in terms of Overall Accuracy, Kappa coefficient, and Average Accuracy on the first two datasets, and achieves state-of-the-art performance on the PRISMA dataset.
Galaxy spectroscopy without spectra: Galaxy properties from photometric images with conditional diffusion models
Jun 26, 2024



Modern spectroscopic surveys can only target a small fraction of the vast amount of photometrically cataloged sources in wide-field surveys. Here, we report the development of a generative AI method capable of predicting optical galaxy spectra from photometric broad-band images alone. This method draws from the latest advances in diffusion models in combination with contrastive networks. We pass multi-band galaxy images into the architecture to obtain optical spectra. From these, robust values for galaxy properties can be derived with any methods in the spectroscopic toolbox, such as standard population synthesis techniques and Lick indices. When trained and tested on 64x64-pixel images from the Sloan Digital Sky Survey, the global bimodality of star-forming and quiescent galaxies in photometric space is recovered, as well as a mass-metallicity relation of star-forming galaxies. The comparison between the observed and the artificially created spectra shows good agreement in overall metallicity, age, Dn4000, stellar velocity dispersion, and E(B-V) values. Photometric redshift estimates of our generative algorithm can compete with other current, specialized deep-learning techniques. Moreover, this work is the first attempt in the literature to infer velocity dispersion from photometric images. Additionally, we can predict the presence of an active galactic nucleus up to an accuracy of 82%. With our method, scientifically interesting galaxy properties, normally requiring spectroscopic inputs, can be obtained in future data sets from large-scale photometric surveys alone. The spectra prediction via AI can further assist in creating realistic mock catalogs.
3D Detection and Characterisation of ALMA Sources through Deep Learning
Nov 21, 2022



We present a Deep-Learning (DL) pipeline developed for the detection and characterization of astronomical sources within simulated Atacama Large Millimeter/submillimeter Array (ALMA) data cubes. The pipeline is composed of six DL models: a Convolutional Autoencoder for source detection within the spatial domain of the integrated data cubes, a Recurrent Neural Network (RNN) for denoising and peak detection within the frequency domain, and four Residual Neural Networks (ResNets) for source characterization. The combination of spatial and frequency information improves completeness while decreasing spurious signal detection. To train and test the pipeline, we developed a simulation algorithm able to generate realistic ALMA observations, i.e. both sky model and dirty cubes. The algorithm simulates always a central source surrounded by fainter ones scattered within the cube. Some sources were spatially superimposed in order to test the pipeline deblending capabilities. The detection performances of the pipeline were compared to those of other methods and significant improvements in performances were achieved. Source morphologies are detected with subpixel accuracies obtaining mean residual errors of $10^{-3}$ pixel ($0.1$ mas) and $10^{-1}$ mJy/beam on positions and flux estimations, respectively. Projection angles and flux densities are also recovered within $10\%$ of the true values for $80\%$ and $73\%$ of all sources in the test set, respectively. While our pipeline is fine-tuned for ALMA data, the technique is applicable to other interferometric observatories, as SKA, LOFAR, VLBI, and VLTI.
ULISSE: A Tool for One-shot Sky Exploration and its Application to Active Galactic Nuclei Detection
Aug 23, 2022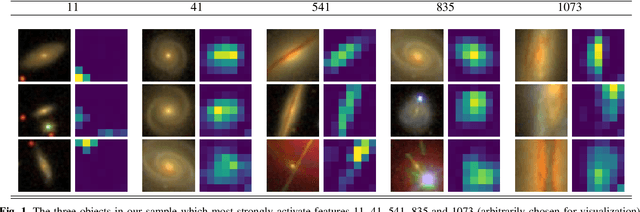
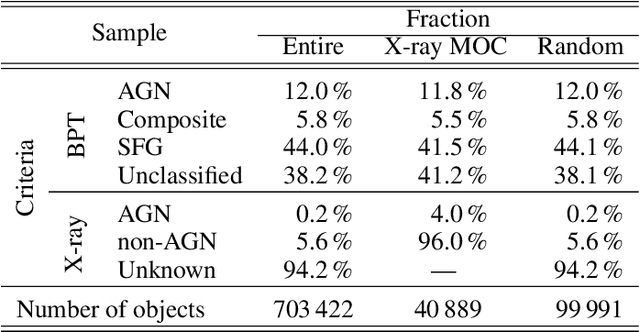
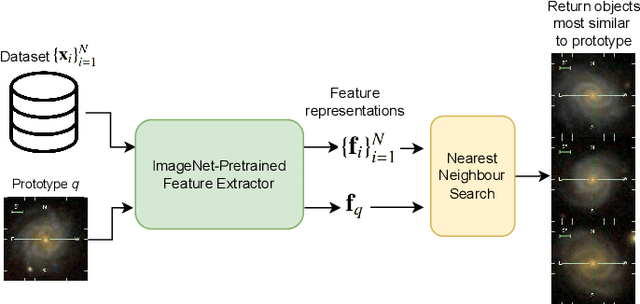
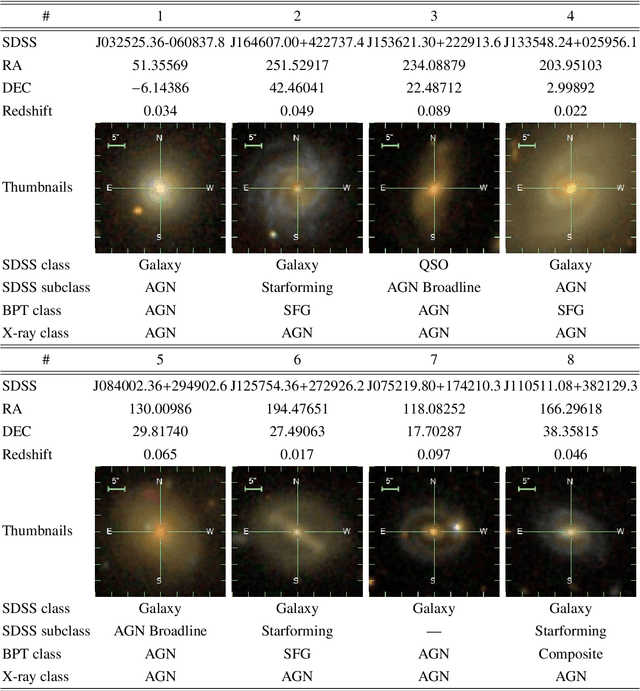
Modern sky surveys are producing ever larger amounts of observational data, which makes the application of classical approaches for the classification and analysis of objects challenging and time-consuming. However, this issue may be significantly mitigated by the application of automatic machine and deep learning methods. We propose ULISSE, a new deep learning tool that, starting from a single prototype object, is capable of identifying objects sharing the same morphological and photometric properties, and hence of creating a list of candidate sosia. In this work, we focus on applying our method to the detection of AGN candidates in a Sloan Digital Sky Survey galaxy sample, since the identification and classification of Active Galactic Nuclei (AGN) in the optical band still remains a challenging task in extragalactic astronomy. Intended for the initial exploration of large sky surveys, ULISSE directly uses features extracted from the ImageNet dataset to perform a similarity search. The method is capable of rapidly identifying a list of candidates, starting from only a single image of a given prototype, without the need for any time-consuming neural network training. Our experiments show ULISSE is able to identify AGN candidates based on a combination of host galaxy morphology, color and the presence of a central nuclear source, with a retrieval efficiency ranging from 21% to 65% (including composite sources) depending on the prototype, where the random guess baseline is 12%. We find ULISSE to be most effective in retrieving AGN in early-type host galaxies, as opposed to prototypes with spiral- or late-type properties. Based on the results described in this work, ULISSE can be a promising tool for selecting different types of astrophysical objects in current and future wide-field surveys (e.g. Euclid, LSST etc.) that target millions of sources every single night.
Feature Selection based on Machine Learning in MRIs for Hippocampal Segmentation
Jan 16, 2015
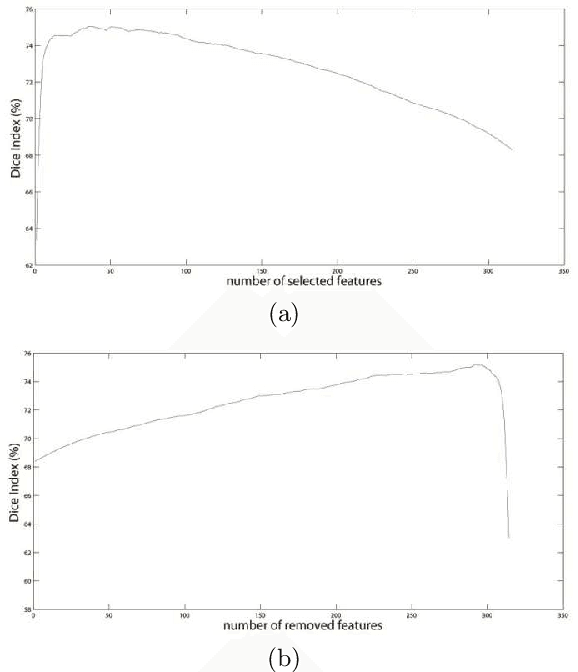
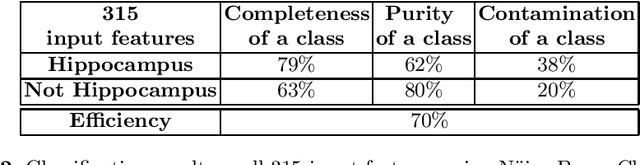

Neurodegenerative diseases are frequently associated with structural changes in the brain. Magnetic Resonance Imaging (MRI) scans can show these variations and therefore be used as a supportive feature for a number of neurodegenerative diseases. The hippocampus has been known to be a biomarker for Alzheimer disease and other neurological and psychiatric diseases. However, it requires accurate, robust and reproducible delineation of hippocampal structures. Fully automatic methods are usually the voxel based approach, for each voxel a number of local features were calculated. In this paper we compared four different techniques for feature selection from a set of 315 features extracted for each voxel: (i) filter method based on the Kolmogorov-Smirnov test; two wrapper methods, respectively, (ii) Sequential Forward Selection and (iii) Sequential Backward Elimination; and (iv) embedded method based on the Random Forest Classifier on a set of 10 T1-weighted brain MRIs and tested on an independent set of 25 subjects. The resulting segmentations were compared with manual reference labelling. By using only 23 features for each voxel (sequential backward elimination) we obtained comparable state of-the-art performances with respect to the standard tool FreeSurfer.
* To appear on "Computational and Mathematical Methods in Medicine", Hindawi Publishing Corporation. 19 pages, 7 figures
Feature Selection Strategies for Classifying High Dimensional Astronomical Data Sets
Oct 08, 2013
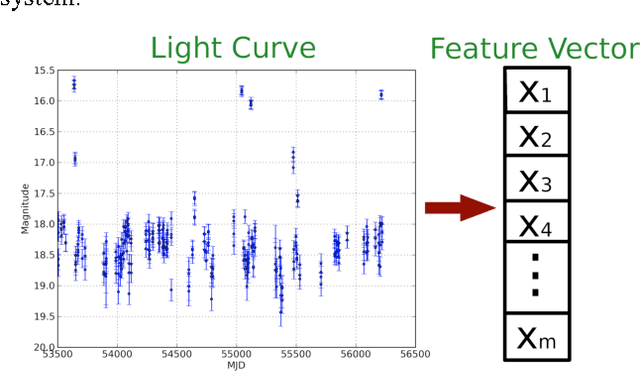
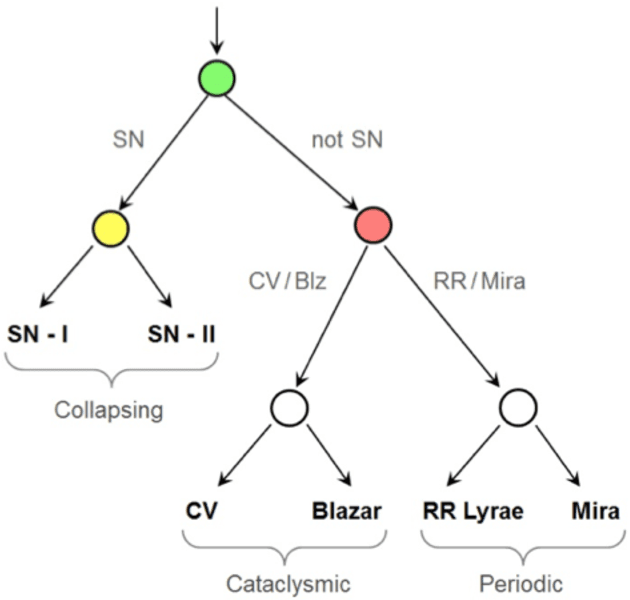
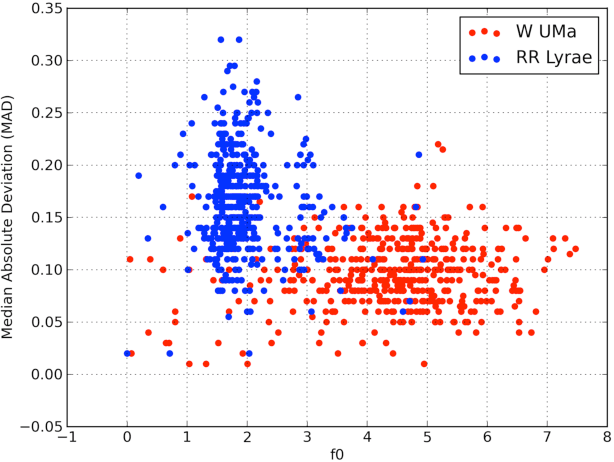
The amount of collected data in many scientific fields is increasing, all of them requiring a common task: extract knowledge from massive, multi parametric data sets, as rapidly and efficiently possible. This is especially true in astronomy where synoptic sky surveys are enabling new research frontiers in the time domain astronomy and posing several new object classification challenges in multi dimensional spaces; given the high number of parameters available for each object, feature selection is quickly becoming a crucial task in analyzing astronomical data sets. Using data sets extracted from the ongoing Catalina Real-Time Transient Surveys (CRTS) and the Kepler Mission we illustrate a variety of feature selection strategies used to identify the subsets that give the most information and the results achieved applying these techniques to three major astronomical problems.
Genetic Algorithm Modeling with GPU Parallel Computing Technology
Nov 23, 2012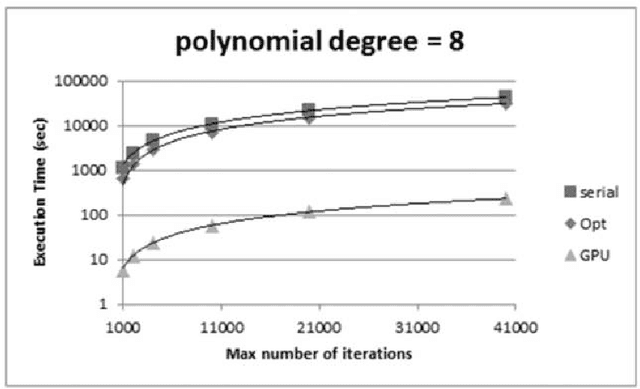
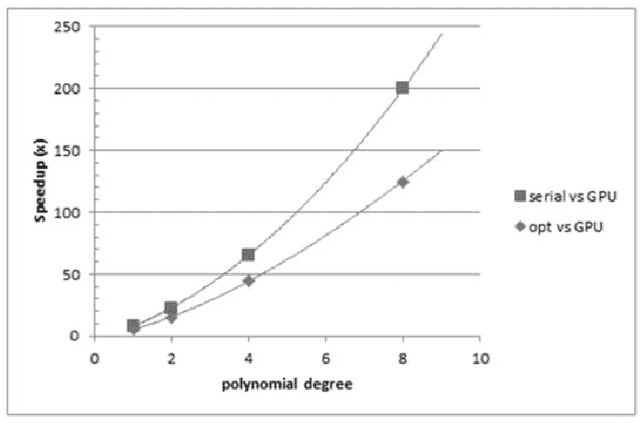
We present a multi-purpose genetic algorithm, designed and implemented with GPGPU / CUDA parallel computing technology. The model was derived from a multi-core CPU serial implementation, named GAME, already scientifically successfully tested and validated on astrophysical massive data classification problems, through a web application resource (DAMEWARE), specialized in data mining based on Machine Learning paradigms. Since genetic algorithms are inherently parallel, the GPGPU computing paradigm has provided an exploit of the internal training features of the model, permitting a strong optimization in terms of processing performances and scalability.
Astroinformatics of galaxies and quasars: a new general method for photometric redshifts estimation
Jul 15, 2011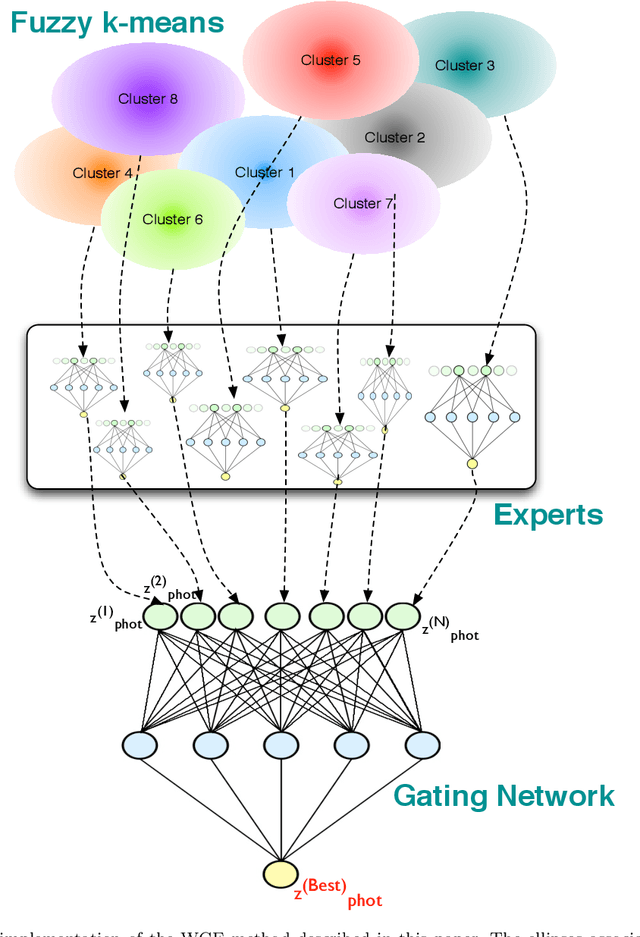
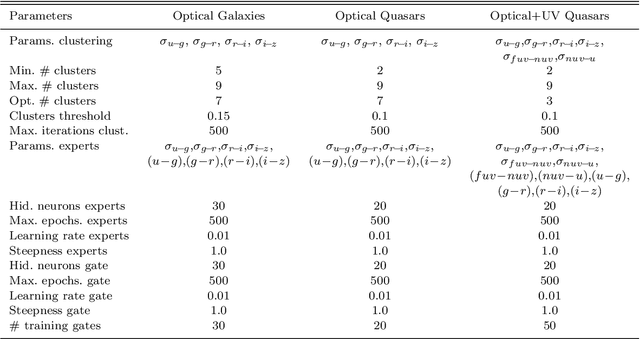
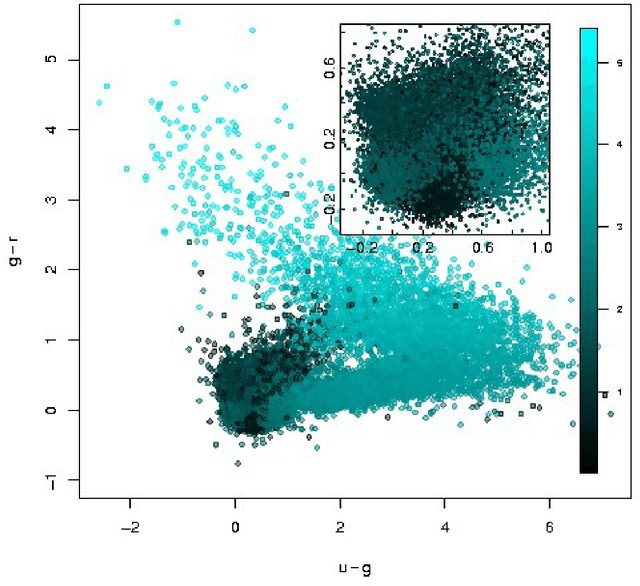
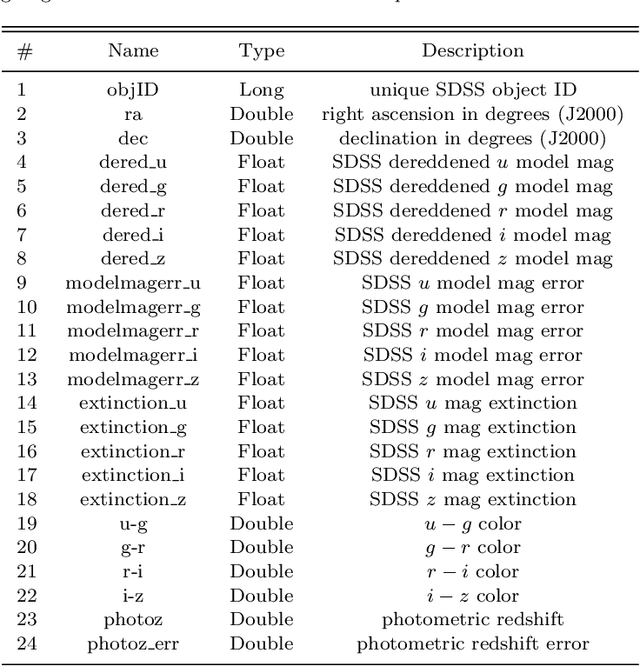
With the availability of the huge amounts of data produced by current and future large multi-band photometric surveys, photometric redshifts have become a crucial tool for extragalactic astronomy and cosmology. In this paper we present a novel method, called Weak Gated Experts (WGE), which allows to derive photometric redshifts through a combination of data mining techniques. \noindent The WGE, like many other machine learning techniques, is based on the exploitation of a spectroscopic knowledge base composed by sources for which a spectroscopic value of the redshift is available. This method achieves a variance \sigma^2(\Delta z)=2.3x10^{-4} (\sigma^2(\Delta z) =0.08), where \Delta z = z_{phot} - z_{spec}) for the reconstruction of the photometric redshifts for the optical galaxies from the SDSS and for the optical quasars respectively, while the Root Mean Square (RMS) of the \Delta z variable distributions for the two experiments is respectively equal to 0.021 and 0.35. The WGE provides also a mechanism for the estimation of the accuracy of each photometric redshift. We also present and discuss the catalogs obtained for the optical SDSS galaxies, for the optical candidate quasars extracted from the DR7 SDSS photometric dataset {The sample of SDSS sources on which the accuracy of the reconstruction has been assessed is composed of bright sources, for a subset of which spectroscopic redshifts have been measured.}, and for optical SDSS candidate quasars observed by GALEX in the UV range. The WGE method exploits the new technological paradigm provided by the Virtual Observatory and the emerging field of Astroinformatics.