 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Multi-Agent Reinforcement Learning for Unrelated Parallel Machine Scheduling
Nov 12, 2024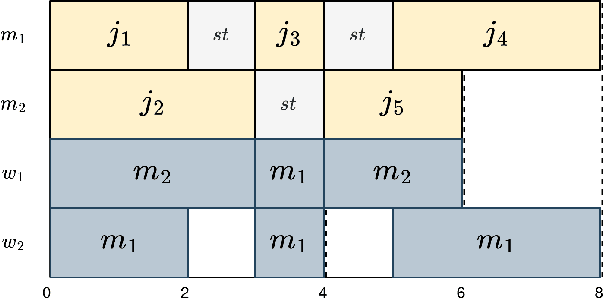



Scheduling problems pose significant challenges in resource, industry, and operational management. This paper addresses the Unrelated Parallel Machine Scheduling Problem (UPMS) with setup times and resources using a Multi-Agent Reinforcement Learning (MARL) approach. The study introduces the Reinforcement Learning environment and conducts empirical analyses, comparing MARL with Single-Agent algorithms. The experiments employ various deep neural network policies for single- and Multi-Agent approaches. Results demonstrate the efficacy of the Maskable extension of the Proximal Policy Optimization (PPO) algorithm in Single-Agent scenarios and the Multi-Agent PPO algorithm in Multi-Agent setups. While Single-Agent algorithms perform adequately in reduced scenarios, Multi-Agent approaches reveal challenges in cooperative learning but a scalable capacity. This research contributes insights into applying MARL techniques to scheduling optimization, emphasizing the need for algorithmic sophistication balanced with scalability for intelligent scheduling solutions.
Integrated Water Resource Management in the Segura Hydrographic Basin: An Artificial Intelligence Approach
Nov 11, 2024


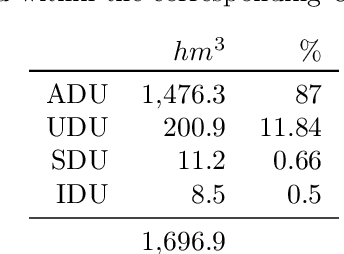
Managing resources effectively in uncertain demand, variable availability, and complex governance policies is a significant challenge. This paper presents a paradigmatic framework for addressing these issues in water management scenarios by integrating advanced physical modelling, remote sensing techniques, and Artificial Intelligence algorithms. The proposed approach accurately predicts water availability, estimates demand, and optimizes resource allocation on both short- and long-term basis, combining a comprehensive hydrological model, agronomic crop models for precise demand estimation, and Mixed-Integer Linear Programming for efficient resource distribution. In the study case of the Segura Hydrographic Basin, the approach successfully allocated approximately 642 million cubic meters ($hm^3$) of water over six months, minimizing the deficit to 9.7% of the total estimated demand. The methodology demonstrated significant environmental benefits, reducing CO2 emissions while optimizing resource distribution. This robust solution supports informed decision-making processes, ensuring sustainable water management across diverse contexts. The generalizability of this approach allows its adaptation to other basins, contributing to improved governance and policy implementation on a broader scale. Ultimately, the methodology has been validated and integrated into the operational water management practices in the Segura Hydrographic Basin in Spain.
* 15 pages, 14 figures, 8 tables
A scalable framework for annotating photovoltaic cell defects in electroluminescence images
Dec 15, 2022



The correct functioning of photovoltaic (PV) cells is critical to ensuring the optimal performance of a solar plant. Anomaly detection techniques for PV cells can result in significant cost savings in operation and maintenance (O&M). Recent research has focused on deep learning techniques for automatically detecting anomalies in Electroluminescence (EL) images. Automated anomaly annotations can improve current O&M methodologies and help develop decision-making systems to extend the life-cycle of the PV cells and predict failures. This paper addresses the lack of anomaly segmentation annotations in the literature by proposing a combination of state-of-the-art data-driven techniques to create a Golden Standard benchmark. The proposed method stands out for (1) its adaptability to new PV cell types, (2) cost-efficient fine-tuning, and (3) leverage public datasets to generate advanced annotations. The methodology has been validated in the annotation of a widely used dataset, obtaining a reduction of the annotation cost by 60%.
Closed-Form Diffeomorphic Transformations for Time Series Alignment
Jun 16, 2022

Time series alignment methods call for highly expressive, differentiable and invertible warping functions which preserve temporal topology, i.e diffeomorphisms. Diffeomorphic warping functions can be generated from the integration of velocity fields governed by an ordinary differential equation (ODE). Gradient-based optimization frameworks containing diffeomorphic transformations require to calculate derivatives to the differential equation's solution with respect to the model parameters, i.e. sensitivity analysis. Unfortunately, deep learning frameworks typically lack automatic-differentiation-compatible sensitivity analysis methods; and implicit functions, such as the solution of ODE, require particular care. Current solutions appeal to adjoint sensitivity methods, ad-hoc numerical solvers or ResNet's Eulerian discretization. In this work, we present a closed-form expression for the ODE solution and its gradient under continuous piecewise-affine (CPA) velocity functions. We present a highly optimized implementation of the results on CPU and GPU. Furthermore, we conduct extensive experiments on several datasets to validate the generalization ability of our model to unseen data for time-series joint alignment. Results show significant improvements both in terms of efficiency and accuracy.
A survey study of success factors in data science projects
Jan 17, 2022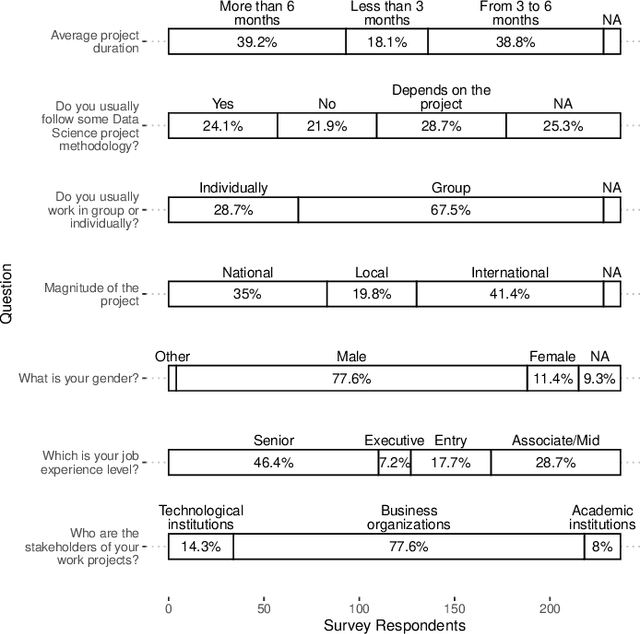
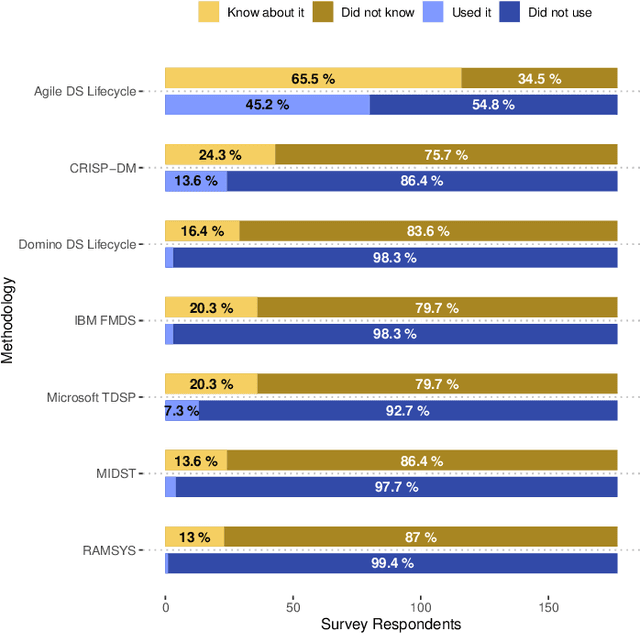
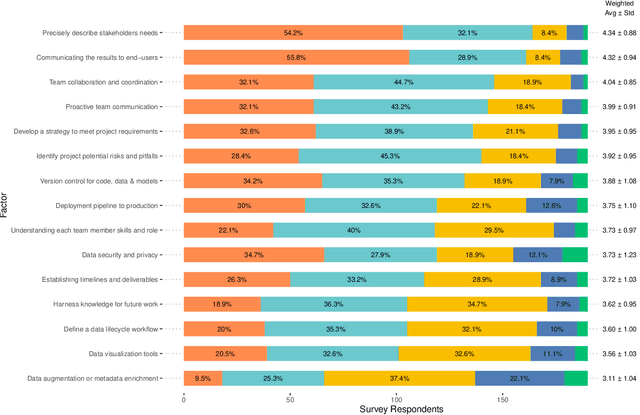
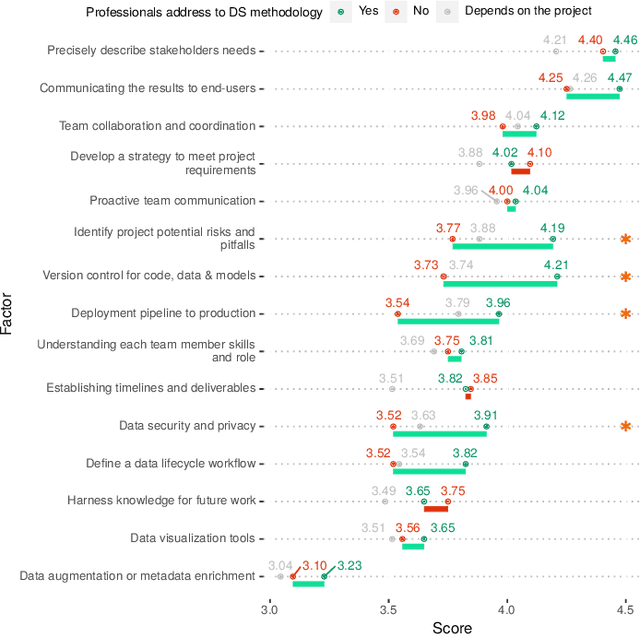
In recent years, the data science community has pursued excellence and made significant research efforts to develop advanced analytics, focusing on solving technical problems at the expense of organizational and socio-technical challenges. According to previous surveys on the state of data science project management, there is a significant gap between technical and organizational processes. In this article we present new empirical data from a survey to 237 data science professionals on the use of project management methodologies for data science. We provide additional profiling of the survey respondents' roles and their priorities when executing data science projects. Based on this survey study, the main findings are: (1) Agile data science lifecycle is the most widely used framework, but only 25% of the survey participants state to follow a data science project methodology. (2) The most important success factors are precisely describing stakeholders' needs, communicating the results to end-users, and team collaboration and coordination. (3) Professionals who adhere to a project methodology place greater emphasis on the project's potential risks and pitfalls, version control, the deployment pipeline to production, and data security and privacy.
* 6 pages, 7 figures, 2 tables, accepted at IEEE Big Data 2021, International Workshop on Methods to Improve Big Data Science Projects
A novel method for error analysis in radiation thermometry with application to industrial furnaces
Jan 10, 2022
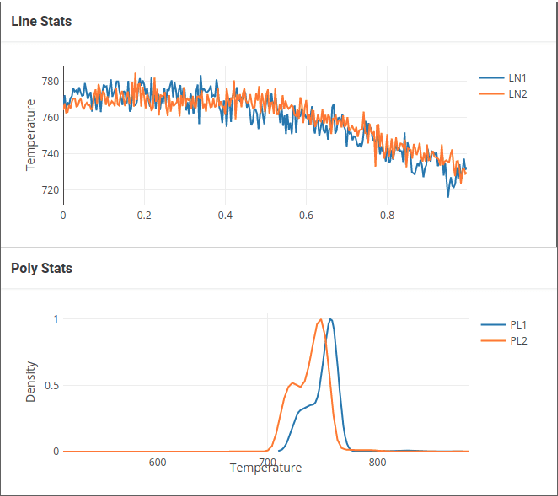

Accurate temperature measurements are essential for the proper monitoring and control of industrial furnaces. However, measurement uncertainty is a risk for such a critical parameter. Certain instrumental and environmental errors must be considered when using spectral-band radiation thermometry techniques, such as the uncertainty in the emissivity of the target surface, reflected radiation from surrounding objects, or atmospheric absorption and emission, to name a few. Undesired contributions to measured radiation can be isolated using measurement models, also known as error-correction models. This paper presents a methodology for budgeting significant sources of error and uncertainty during temperature measurements in a petrochemical furnace scenario. A continuous monitoring system is also presented, aided by a deep-learning-based measurement correction model, to allow domain experts to analyze the furnace's operation in real-time. To validate the proposed system's functionality, a real-world application case in a petrochemical plant is presented. The proposed solution demonstrates the viability of precise industrial furnace monitoring, thereby increasing operational security and improving the efficiency of such energy-intensive systems.
ArchABM: an agent-based simulator of human interaction with the built environment. $CO_2$ and viral load analysis for indoor air quality
Nov 02, 2021
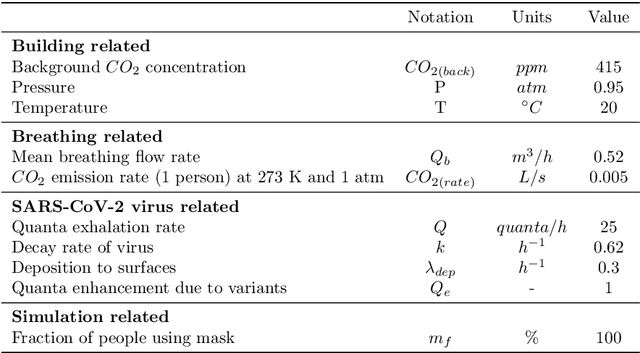
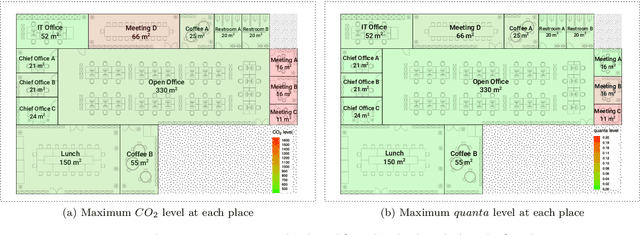

Recent evidence suggests that SARS-CoV-2, which is the virus causing a global pandemic in 2020, is predominantly transmitted via airborne aerosols in indoor environments. This calls for novel strategies when assessing and controlling a building's indoor air quality (IAQ). IAQ can generally be controlled by ventilation and/or policies to regulate human-building-interaction. However, in a building, occupants use rooms in different ways, and it may not be obvious which measure or combination of measures leads to a cost- and energy-effective solution ensuring good IAQ across the entire building. Therefore, in this article, we introduce a novel agent-based simulator, ArchABM, designed to assist in creating new or adapt existing buildings by estimating adequate room sizes, ventilation parameters and testing the effect of policies while taking into account IAQ as a result of complex human-building interaction patterns. A recently published aerosol model was adapted to calculate time-dependent carbon dioxide ($CO_2$) and virus quanta concentrations in each room and inhaled $CO_2$ and virus quanta for each occupant over a day as a measure of physiological response. ArchABM is flexible regarding the aerosol model and the building layout due to its modular architecture, which allows implementing further models, any number and size of rooms, agents, and actions reflecting human-building interaction patterns. We present a use case based on a real floor plan and working schedules adopted in our research center. This study demonstrates how advanced simulation tools can contribute to improving IAQ across a building, thereby ensuring a healthy indoor environment.
Segmentation of cell-level anomalies in electroluminescence images of photovoltaic modules
Jun 21, 2021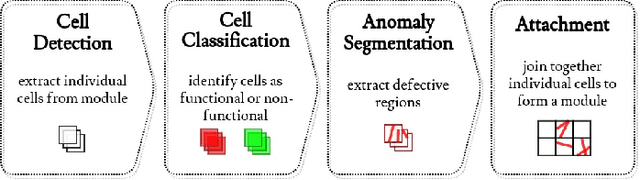
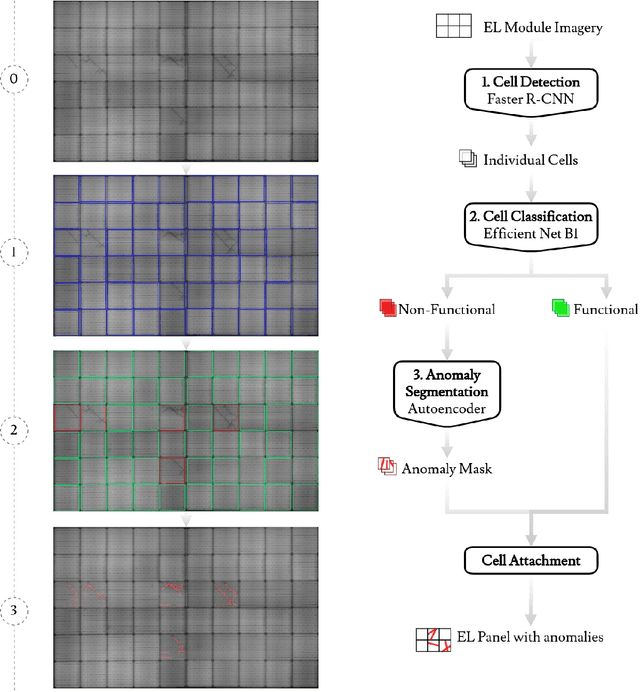
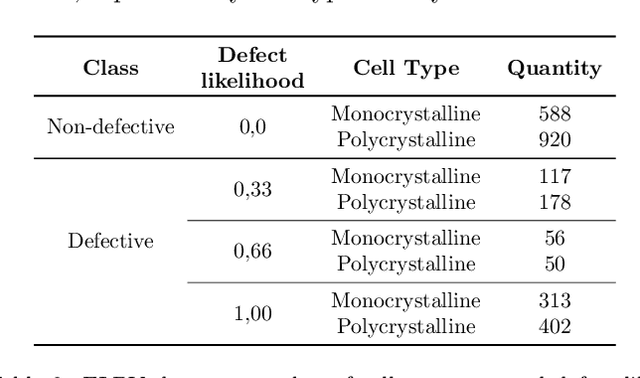
In the operation & maintenance (O&M) of photovoltaic (PV) plants, the early identification of failures has become crucial to maintain productivity and prolong components' life. Of all defects, cell-level anomalies can lead to serious failures and may affect surrounding PV modules in the long run. These fine defects are usually captured with high spatial resolution electroluminescence (EL) imaging. The difficulty of acquiring such images has limited the availability of data. For this work, multiple data resources and augmentation techniques have been used to surpass this limitation. Current state-of-the-art detection methods extract barely low-level information from individual PV cell images, and their performance is conditioned by the available training data. In this article, we propose an end-to-end deep learning pipeline that detects, locates and segments cell-level anomalies from entire photovoltaic modules via EL images. The proposed modular pipeline combines three deep learning techniques: 1. object detection (modified Faster-RNN), 2. image classification (EfficientNet) and 3. weakly supervised segmentation (autoencoder). The modular nature of the pipeline allows to upgrade the deep learning models to the further improvements in the state-of-the-art and also extend the pipeline towards new functionalities.
* 16 pages, 14 figures
Data Science Methodologies: Current Challenges and Future Approaches
Jun 14, 2021
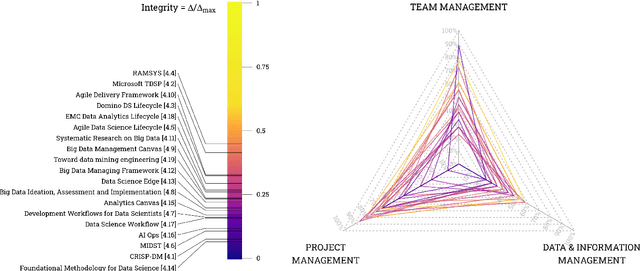
Data science has employed great research efforts in developing advanced analytics, improving data models and cultivating new algorithms. However, not many authors have come across the organizational and socio-technical challenges that arise when executing a data science project: lack of vision and clear objectives, a biased emphasis on technical issues, a low level of maturity for ad-hoc projects and the ambiguity of roles in data science are among these challenges. Few methodologies have been proposed on the literature that tackle these type of challenges, some of them date back to the mid-1990, and consequently they are not updated to the current paradigm and the latest developments in big data and machine learning technologies. In addition, fewer methodologies offer a complete guideline across team, project and data & information management. In this article we would like to explore the necessity of developing a more holistic approach for carrying out data science projects. We first review methodologies that have been presented on the literature to work on data science projects and classify them according to the their focus: project, team, data and information management. Finally, we propose a conceptual framework containing general characteristics that a methodology for managing data science projects with a holistic point of view should have. This framework can be used by other researchers as a roadmap for the design of new data science methodologies or the updating of existing ones.
* 23 pages, 23 figures, 5 tables
Trace transform based method for color image domain identification
Nov 26, 2012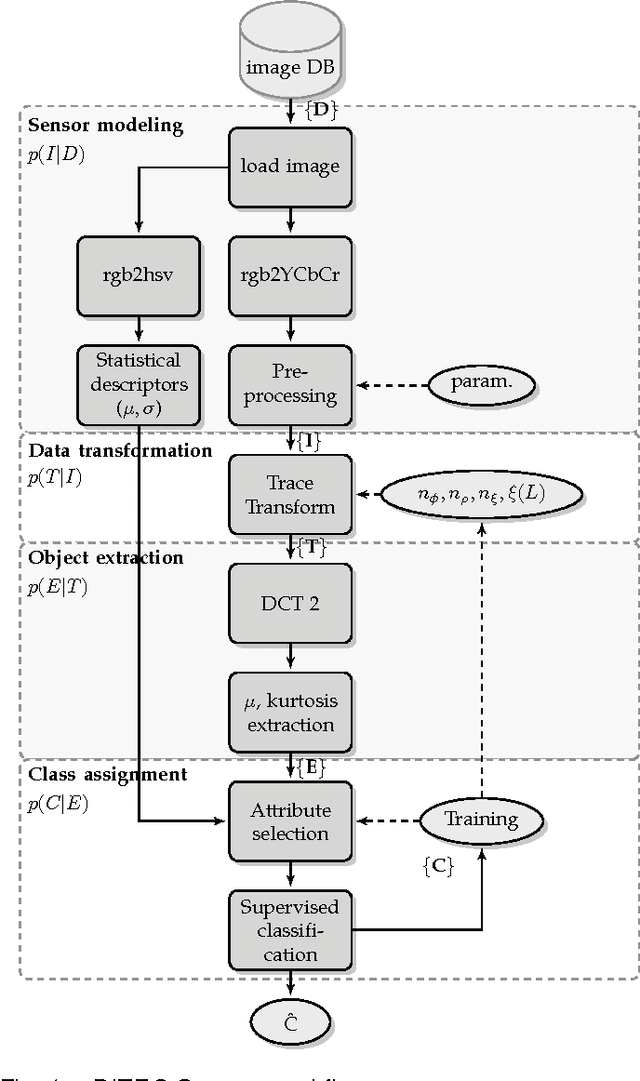
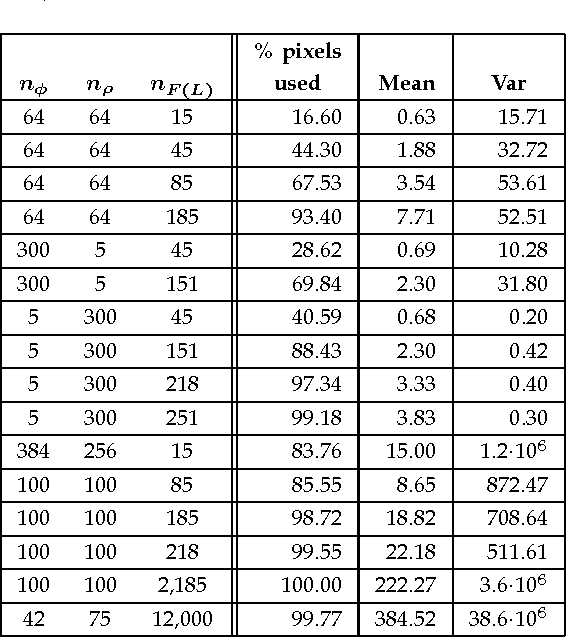
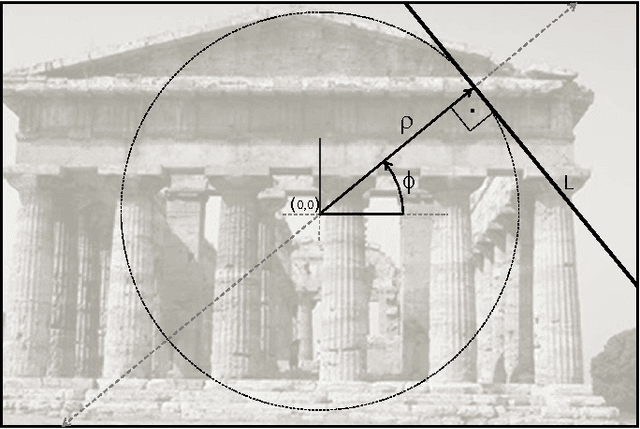
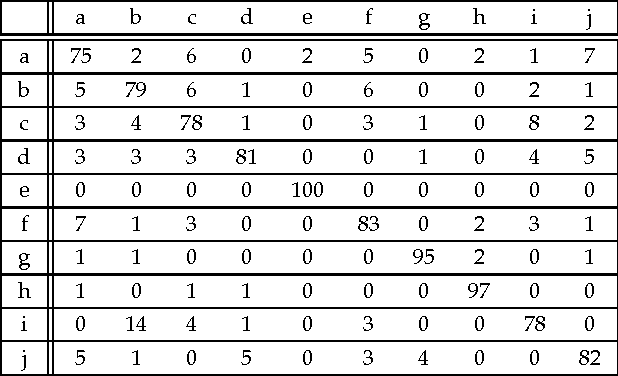
Context categorization is a fundamental pre-requisite for multi-domain multimedia content analysis applications in order to manage contextual information in an efficient manner. In this paper, we introduce a new color image context categorization method (DITEC) based on the trace transform. The problem of dimensionality reduction of the obtained trace transform signal is addressed through statistical descriptors that keep the underlying information. These extracted features offer a highly discriminant behavior for content categorization. The theoretical properties of the method are analyzed and validated experimentally through two different datasets.