 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffeomorphic Transformations for Time Series Analysis: An Efficient Approach to Nonlinear Warping
Sep 25, 2023The proliferation and ubiquity of temporal data across many disciplines has sparked interest for similarity, classification and clustering methods specifically designed to handle time series data. A core issue when dealing with time series is determining their pairwise similarity, i.e., the degree to which a given time series resembles another. Traditional distance measures such as the Euclidean are not well-suited due to the time-dependent nature of the data. Elastic metrics such as dynamic time warping (DTW) offer a promising approach, but are limited by their computational complexity, non-differentiability and sensitivity to noise and outliers. This thesis proposes novel elastic alignment methods that use parametric \& diffeomorphic warping transformations as a means of overcoming the shortcomings of DTW-based metrics. The proposed method is differentiable \& invertible, well-suited for deep learning architectures, robust to noise and outliers, computationally efficient, and is expressive and flexible enough to capture complex patterns. Furthermore, a closed-form solution was developed for the gradient of these diffeomorphic transformations, which allows an efficient search in the parameter space, leading to better solutions at convergence. Leveraging the benefits of these closed-form diffeomorphic transformations, this thesis proposes a suite of advancements that include: (a) an enhanced temporal transformer network for time series alignment and averaging, (b) a deep-learning based time series classification model to simultaneously align and classify signals with high accuracy, (c) an incremental time series clustering algorithm that is warping-invariant, scalable and can operate under limited computational and time resources, and finally, (d) a normalizing flow model that enhances the flexibility of affine transformations in coupling and autoregressive layers.
Closed-Form Diffeomorphic Transformations for Time Series Alignment
Jun 16, 2022
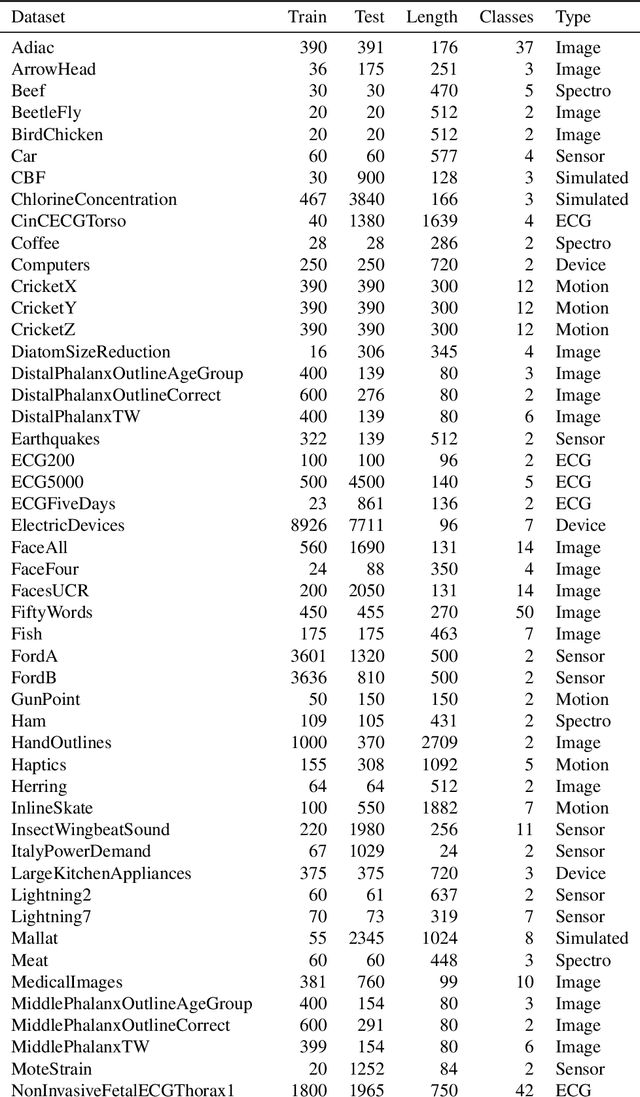
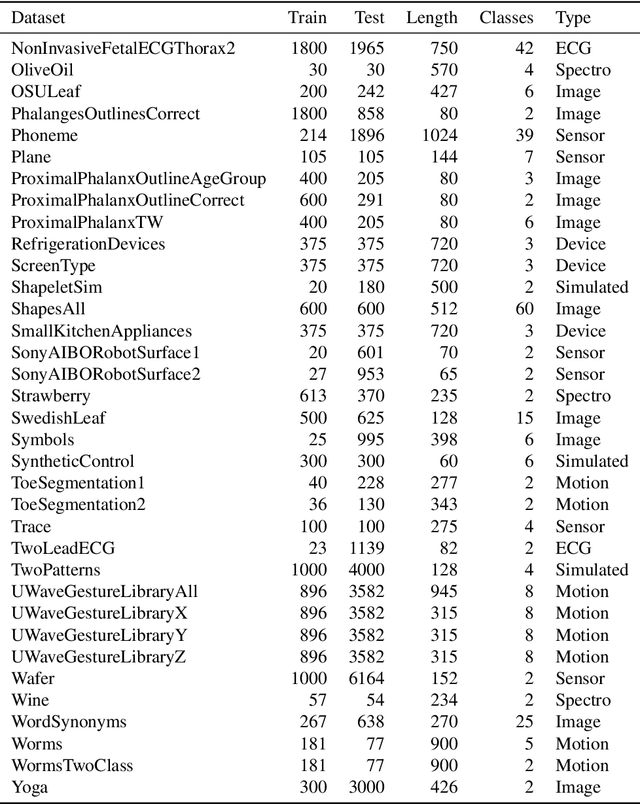

Time series alignment methods call for highly expressive, differentiable and invertible warping functions which preserve temporal topology, i.e diffeomorphisms. Diffeomorphic warping functions can be generated from the integration of velocity fields governed by an ordinary differential equation (ODE). Gradient-based optimization frameworks containing diffeomorphic transformations require to calculate derivatives to the differential equation's solution with respect to the model parameters, i.e. sensitivity analysis. Unfortunately, deep learning frameworks typically lack automatic-differentiation-compatible sensitivity analysis methods; and implicit functions, such as the solution of ODE, require particular care. Current solutions appeal to adjoint sensitivity methods, ad-hoc numerical solvers or ResNet's Eulerian discretization. In this work, we present a closed-form expression for the ODE solution and its gradient under continuous piecewise-affine (CPA) velocity functions. We present a highly optimized implementation of the results on CPU and GPU. Furthermore, we conduct extensive experiments on several datasets to validate the generalization ability of our model to unseen data for time-series joint alignment. Results show significant improvements both in terms of efficiency and accuracy.
A survey study of success factors in data science projects
Jan 17, 2022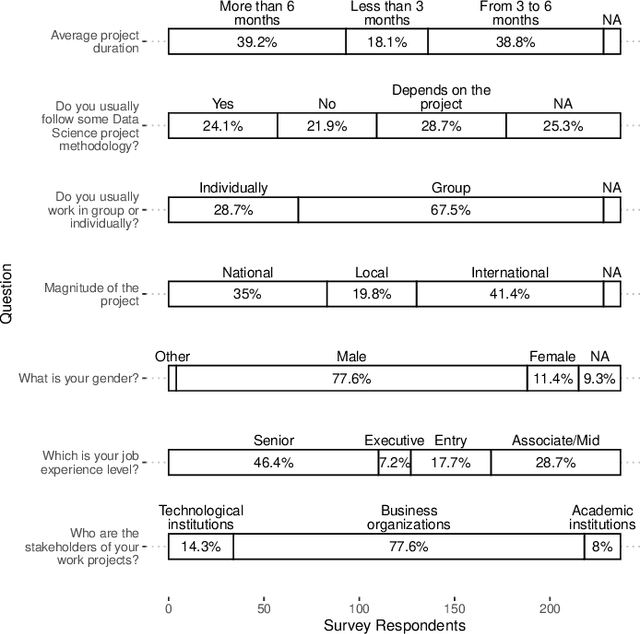
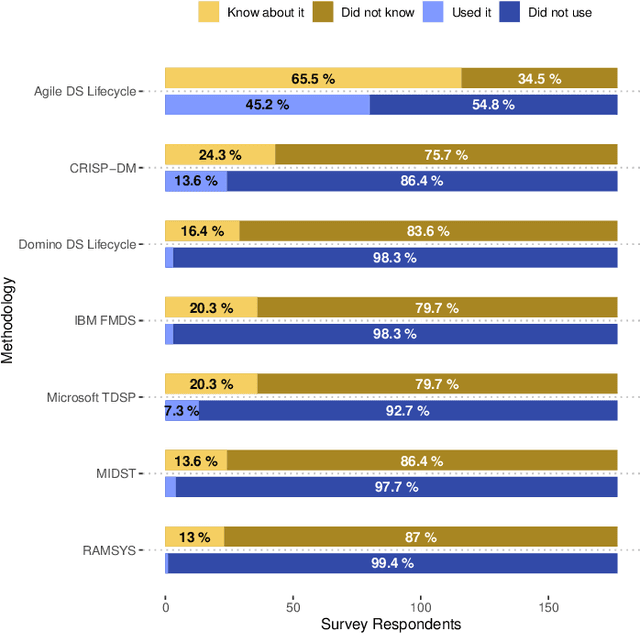
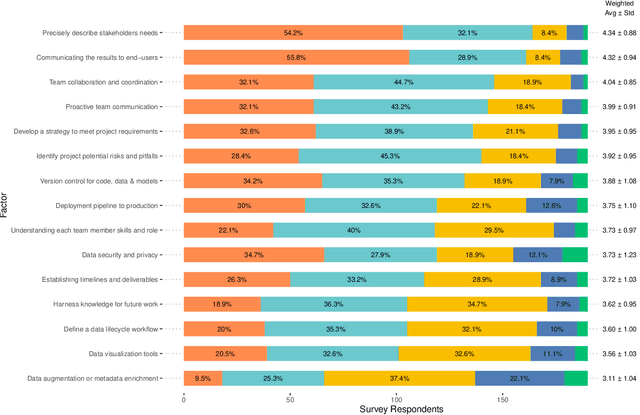
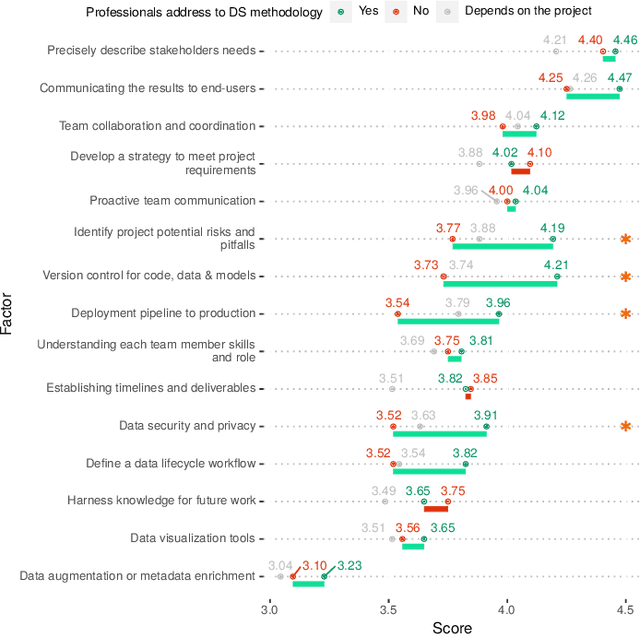
In recent years, the data science community has pursued excellence and made significant research efforts to develop advanced analytics, focusing on solving technical problems at the expense of organizational and socio-technical challenges. According to previous surveys on the state of data science project management, there is a significant gap between technical and organizational processes. In this article we present new empirical data from a survey to 237 data science professionals on the use of project management methodologies for data science. We provide additional profiling of the survey respondents' roles and their priorities when executing data science projects. Based on this survey study, the main findings are: (1) Agile data science lifecycle is the most widely used framework, but only 25% of the survey participants state to follow a data science project methodology. (2) The most important success factors are precisely describing stakeholders' needs, communicating the results to end-users, and team collaboration and coordination. (3) Professionals who adhere to a project methodology place greater emphasis on the project's potential risks and pitfalls, version control, the deployment pipeline to production, and data security and privacy.
* 6 pages, 7 figures, 2 tables, accepted at IEEE Big Data 2021, International Workshop on Methods to Improve Big Data Science Projects
A novel method for error analysis in radiation thermometry with application to industrial furnaces
Jan 10, 2022
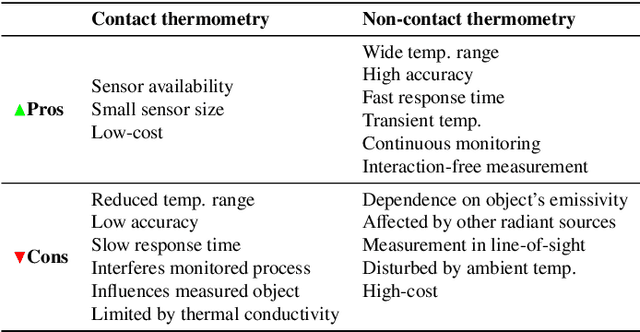
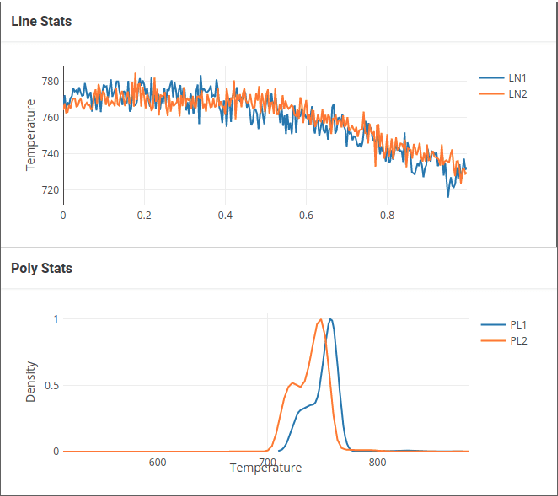

Accurate temperature measurements are essential for the proper monitoring and control of industrial furnaces. However, measurement uncertainty is a risk for such a critical parameter. Certain instrumental and environmental errors must be considered when using spectral-band radiation thermometry techniques, such as the uncertainty in the emissivity of the target surface, reflected radiation from surrounding objects, or atmospheric absorption and emission, to name a few. Undesired contributions to measured radiation can be isolated using measurement models, also known as error-correction models. This paper presents a methodology for budgeting significant sources of error and uncertainty during temperature measurements in a petrochemical furnace scenario. A continuous monitoring system is also presented, aided by a deep-learning-based measurement correction model, to allow domain experts to analyze the furnace's operation in real-time. To validate the proposed system's functionality, a real-world application case in a petrochemical plant is presented. The proposed solution demonstrates the viability of precise industrial furnace monitoring, thereby increasing operational security and improving the efficiency of such energy-intensive systems.
ArchABM: an agent-based simulator of human interaction with the built environment. $CO_2$ and viral load analysis for indoor air quality
Nov 02, 2021
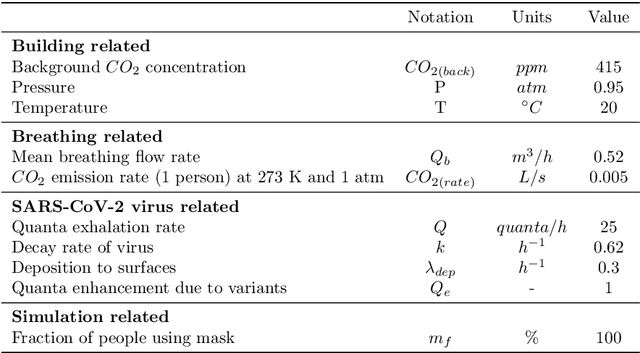
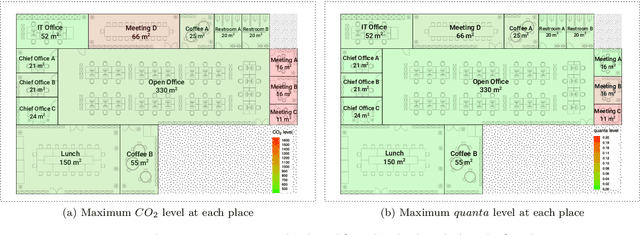

Recent evidence suggests that SARS-CoV-2, which is the virus causing a global pandemic in 2020, is predominantly transmitted via airborne aerosols in indoor environments. This calls for novel strategies when assessing and controlling a building's indoor air quality (IAQ). IAQ can generally be controlled by ventilation and/or policies to regulate human-building-interaction. However, in a building, occupants use rooms in different ways, and it may not be obvious which measure or combination of measures leads to a cost- and energy-effective solution ensuring good IAQ across the entire building. Therefore, in this article, we introduce a novel agent-based simulator, ArchABM, designed to assist in creating new or adapt existing buildings by estimating adequate room sizes, ventilation parameters and testing the effect of policies while taking into account IAQ as a result of complex human-building interaction patterns. A recently published aerosol model was adapted to calculate time-dependent carbon dioxide ($CO_2$) and virus quanta concentrations in each room and inhaled $CO_2$ and virus quanta for each occupant over a day as a measure of physiological response. ArchABM is flexible regarding the aerosol model and the building layout due to its modular architecture, which allows implementing further models, any number and size of rooms, agents, and actions reflecting human-building interaction patterns. We present a use case based on a real floor plan and working schedules adopted in our research center. This study demonstrates how advanced simulation tools can contribute to improving IAQ across a building, thereby ensuring a healthy indoor environment.
Segmentation of cell-level anomalies in electroluminescence images of photovoltaic modules
Jun 21, 2021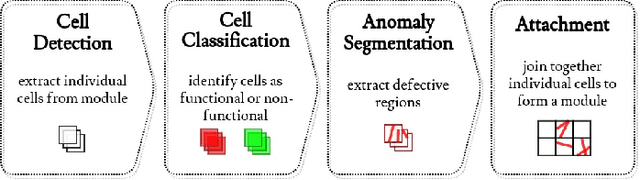
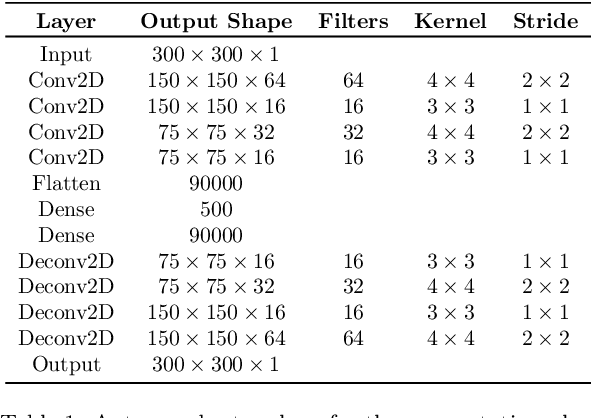
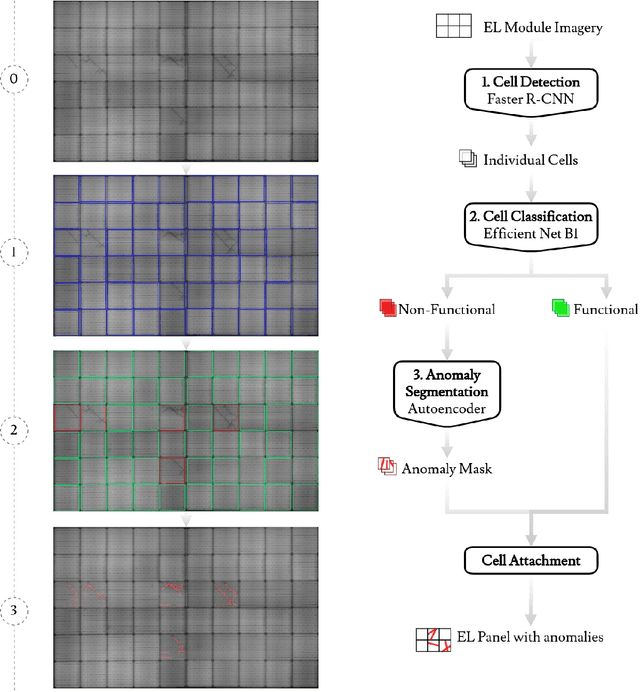
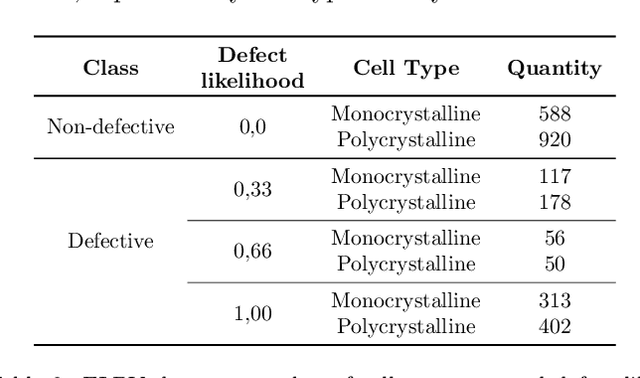
In the operation & maintenance (O&M) of photovoltaic (PV) plants, the early identification of failures has become crucial to maintain productivity and prolong components' life. Of all defects, cell-level anomalies can lead to serious failures and may affect surrounding PV modules in the long run. These fine defects are usually captured with high spatial resolution electroluminescence (EL) imaging. The difficulty of acquiring such images has limited the availability of data. For this work, multiple data resources and augmentation techniques have been used to surpass this limitation. Current state-of-the-art detection methods extract barely low-level information from individual PV cell images, and their performance is conditioned by the available training data. In this article, we propose an end-to-end deep learning pipeline that detects, locates and segments cell-level anomalies from entire photovoltaic modules via EL images. The proposed modular pipeline combines three deep learning techniques: 1. object detection (modified Faster-RNN), 2. image classification (EfficientNet) and 3. weakly supervised segmentation (autoencoder). The modular nature of the pipeline allows to upgrade the deep learning models to the further improvements in the state-of-the-art and also extend the pipeline towards new functionalities.
* 16 pages, 14 figures
Labelling Drifts in a Fault Detection System for Wind Turbine Maintenance
Jun 18, 2021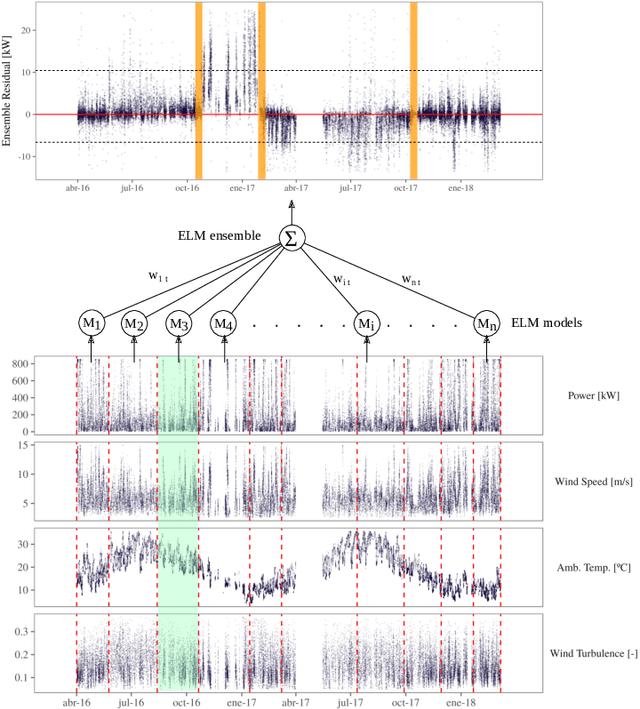

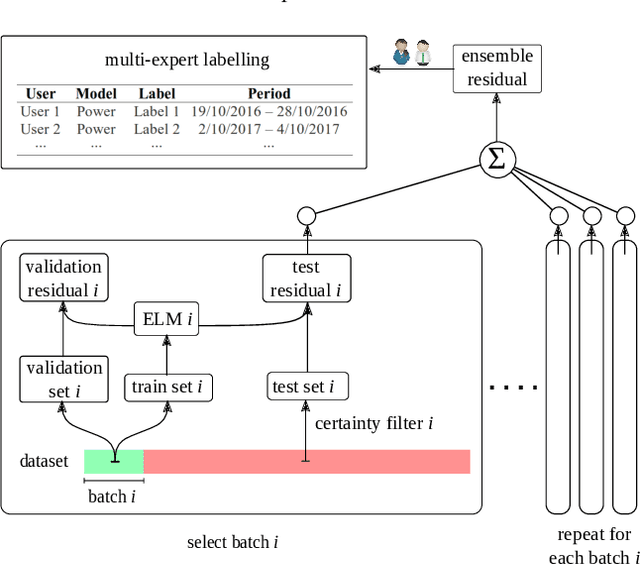
A failure detection system is the first step towards predictive maintenance strategies. A popular data-driven method to detect incipient failures and anomalies is the training of normal behaviour models by applying a machine learning technique like feed-forward neural networks (FFNN) or extreme learning machines (ELM). However, the performance of any of these modelling techniques can be deteriorated by the unexpected rise of non-stationarities in the dynamic environment in which industrial assets operate. This unpredictable statistical change in the measured variable is known as concept drift. In this article a wind turbine maintenance case is presented, where non-stationarities of various kinds can happen unexpectedly. Such concept drift events are desired to be detected by means of statistical detectors and window-based approaches. However, in real complex systems, concept drifts are not as clear and evident as in artificially generated datasets. In order to evaluate the effectiveness of current drift detectors and also to design an appropriate novel technique for this specific industrial application, it is essential to dispose beforehand of a characterization of the existent drifts. Under the lack of information in this regard, a methodology for labelling concept drift events in the lifetime of wind turbines is proposed. This methodology will facilitate the creation of a drift database that will serve both as a training ground for concept drift detectors and as a valuable information to enhance the knowledge about maintenance of complex systems.
* 11 pages, 2 figures, 1 table
Data Science Methodologies: Current Challenges and Future Approaches
Jun 14, 2021
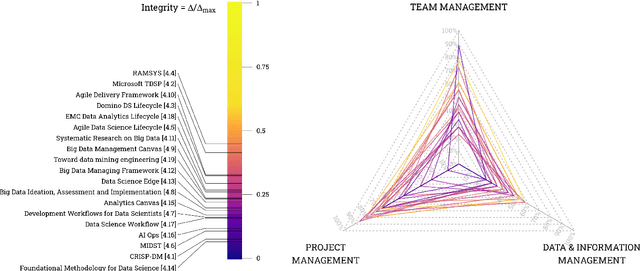
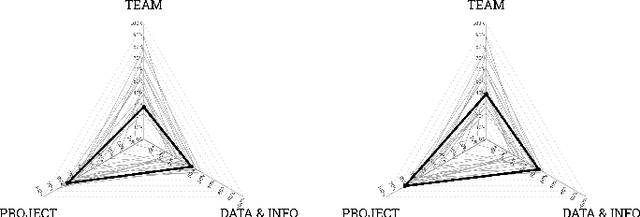
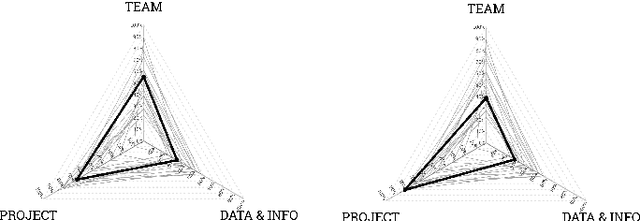
Data science has employed great research efforts in developing advanced analytics, improving data models and cultivating new algorithms. However, not many authors have come across the organizational and socio-technical challenges that arise when executing a data science project: lack of vision and clear objectives, a biased emphasis on technical issues, a low level of maturity for ad-hoc projects and the ambiguity of roles in data science are among these challenges. Few methodologies have been proposed on the literature that tackle these type of challenges, some of them date back to the mid-1990, and consequently they are not updated to the current paradigm and the latest developments in big data and machine learning technologies. In addition, fewer methodologies offer a complete guideline across team, project and data & information management. In this article we would like to explore the necessity of developing a more holistic approach for carrying out data science projects. We first review methodologies that have been presented on the literature to work on data science projects and classify them according to the their focus: project, team, data and information management. Finally, we propose a conceptual framework containing general characteristics that a methodology for managing data science projects with a holistic point of view should have. This framework can be used by other researchers as a roadmap for the design of new data science methodologies or the updating of existing ones.
* 23 pages, 23 figures, 5 tables