 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLimitations of Physics-Informed Neural Networks: a Study on Smart Grid Surrogation
Aug 29, 2025Physics-Informed Neural Networks (PINNs) present a transformative approach for smart grid modeling by integrating physical laws directly into learning frameworks, addressing critical challenges of data scarcity and physical consistency in conventional data-driven methods. This paper evaluates PINNs' capabilities as surrogate models for smart grid dynamics, comparing their performance against XGBoost, Random Forest, and Linear Regression across three key experiments: interpolation, cross-validation, and episodic trajectory prediction. By training PINNs exclusively through physics-based loss functions (enforcing power balance, operational constraints, and grid stability) we demonstrate their superior generalization, outperforming data-driven models in error reduction. Notably, PINNs maintain comparatively lower MAE in dynamic grid operations, reliably capturing state transitions in both random and expert-driven control scenarios, while traditional models exhibit erratic performance. Despite slight degradation in extreme operational regimes, PINNs consistently enforce physical feasibility, proving vital for safety-critical applications. Our results contribute to establishing PINNs as a paradigm-shifting tool for smart grid surrogation, bridging data-driven flexibility with first-principles rigor. This work advances real-time grid control and scalable digital twins, emphasizing the necessity of physics-aware architectures in mission-critical energy systems.
Integrated Water Resource Management in the Segura Hydrographic Basin: An Artificial Intelligence Approach
Nov 11, 2024


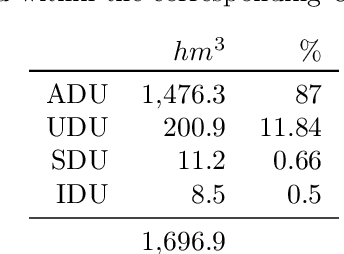
Managing resources effectively in uncertain demand, variable availability, and complex governance policies is a significant challenge. This paper presents a paradigmatic framework for addressing these issues in water management scenarios by integrating advanced physical modelling, remote sensing techniques, and Artificial Intelligence algorithms. The proposed approach accurately predicts water availability, estimates demand, and optimizes resource allocation on both short- and long-term basis, combining a comprehensive hydrological model, agronomic crop models for precise demand estimation, and Mixed-Integer Linear Programming for efficient resource distribution. In the study case of the Segura Hydrographic Basin, the approach successfully allocated approximately 642 million cubic meters ($hm^3$) of water over six months, minimizing the deficit to 9.7% of the total estimated demand. The methodology demonstrated significant environmental benefits, reducing CO2 emissions while optimizing resource distribution. This robust solution supports informed decision-making processes, ensuring sustainable water management across diverse contexts. The generalizability of this approach allows its adaptation to other basins, contributing to improved governance and policy implementation on a broader scale. Ultimately, the methodology has been validated and integrated into the operational water management practices in the Segura Hydrographic Basin in Spain.
* 15 pages, 14 figures, 8 tables
A scalable framework for annotating photovoltaic cell defects in electroluminescence images
Dec 15, 2022



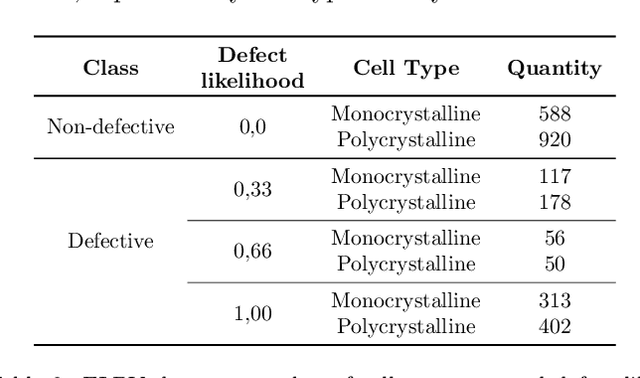
The correct functioning of photovoltaic (PV) cells is critical to ensuring the optimal performance of a solar plant. Anomaly detection techniques for PV cells can result in significant cost savings in operation and maintenance (O&M). Recent research has focused on deep learning techniques for automatically detecting anomalies in Electroluminescence (EL) images. Automated anomaly annotations can improve current O&M methodologies and help develop decision-making systems to extend the life-cycle of the PV cells and predict failures. This paper addresses the lack of anomaly segmentation annotations in the literature by proposing a combination of state-of-the-art data-driven techniques to create a Golden Standard benchmark. The proposed method stands out for (1) its adaptability to new PV cell types, (2) cost-efficient fine-tuning, and (3) leverage public datasets to generate advanced annotations. The methodology has been validated in the annotation of a widely used dataset, obtaining a reduction of the annotation cost by 60%.
Storehouse: a Reinforcement Learning Environment for Optimizing Warehouse Management
Jul 08, 2022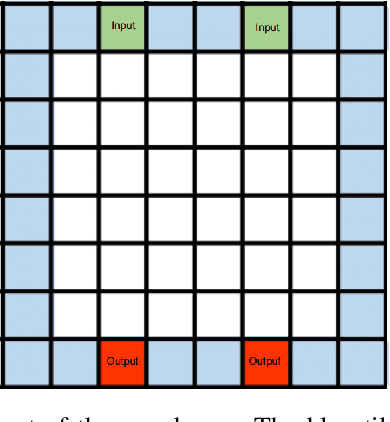
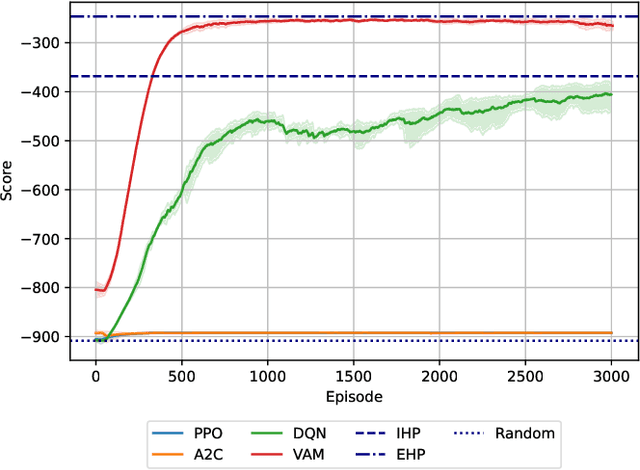
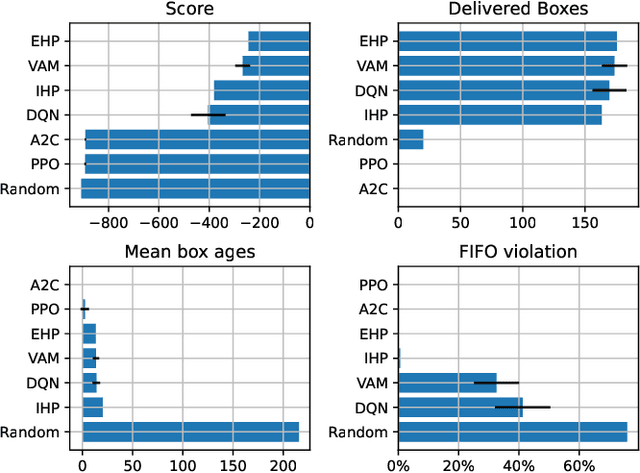
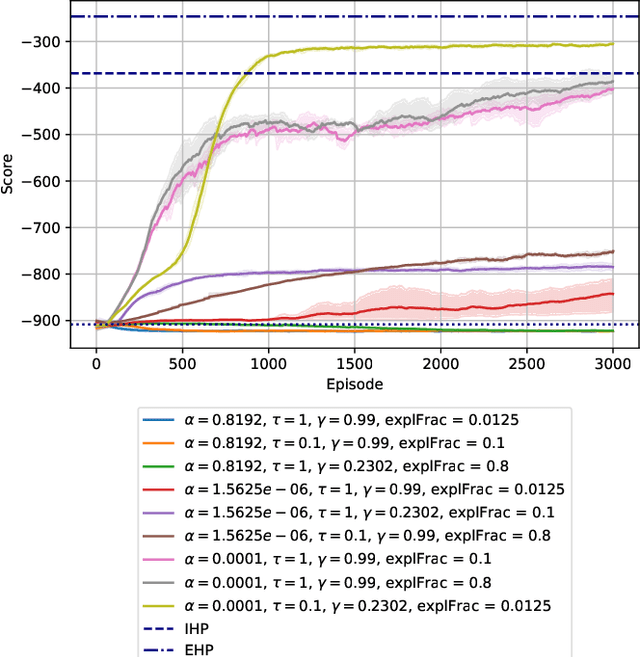
Warehouse Management Systems have been evolving and improving thanks to new Data Intelligence techniques. However, many current optimizations have been applied to specific cases or are in great need of manual interaction. Here is where Reinforcement Learning techniques come into play, providing automatization and adaptability to current optimization policies. In this paper, we present Storehouse, a customizable environment that generalizes the definition of warehouse simulations for Reinforcement Learning. We also validate this environment against state-of-the-art reinforcement learning algorithms and compare these results to human and random policies.
Segmentation of cell-level anomalies in electroluminescence images of photovoltaic modules
Jun 21, 2021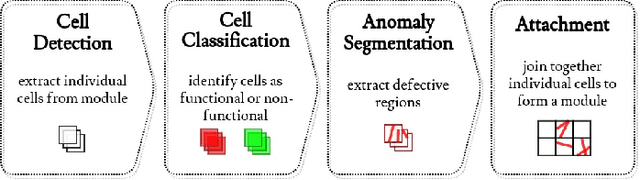
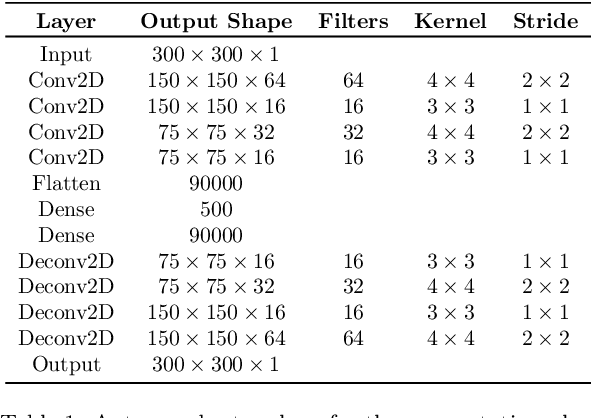
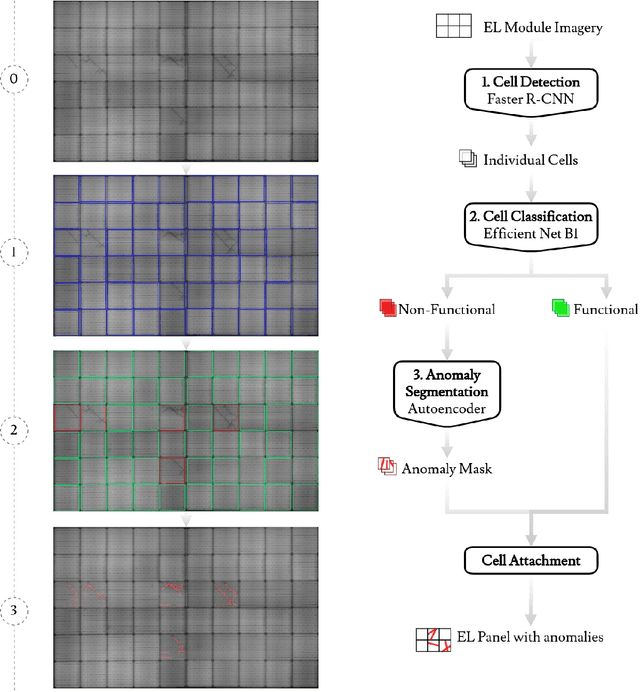
In the operation & maintenance (O&M) of photovoltaic (PV) plants, the early identification of failures has become crucial to maintain productivity and prolong components' life. Of all defects, cell-level anomalies can lead to serious failures and may affect surrounding PV modules in the long run. These fine defects are usually captured with high spatial resolution electroluminescence (EL) imaging. The difficulty of acquiring such images has limited the availability of data. For this work, multiple data resources and augmentation techniques have been used to surpass this limitation. Current state-of-the-art detection methods extract barely low-level information from individual PV cell images, and their performance is conditioned by the available training data. In this article, we propose an end-to-end deep learning pipeline that detects, locates and segments cell-level anomalies from entire photovoltaic modules via EL images. The proposed modular pipeline combines three deep learning techniques: 1. object detection (modified Faster-RNN), 2. image classification (EfficientNet) and 3. weakly supervised segmentation (autoencoder). The modular nature of the pipeline allows to upgrade the deep learning models to the further improvements in the state-of-the-art and also extend the pipeline towards new functionalities.
* 16 pages, 14 figures
Determining input variable ranges in Industry 4.0: A heuristic for estimating the domain of a real-valued function or trained regression model given an output range
Apr 03, 2019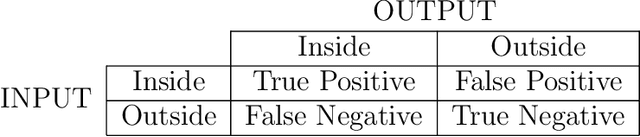
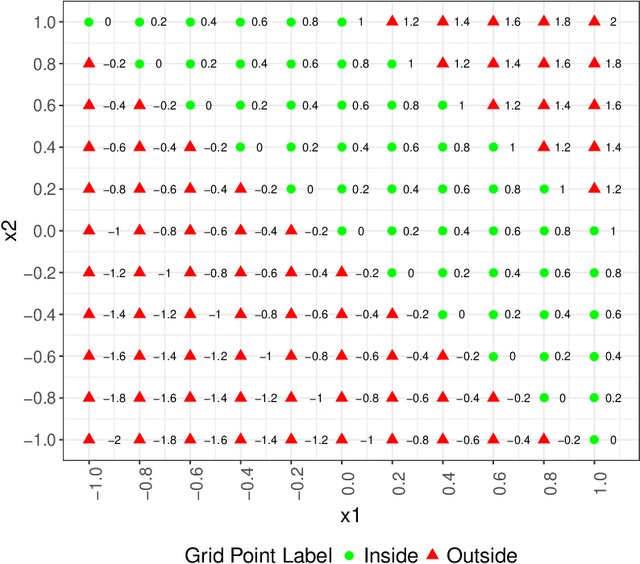
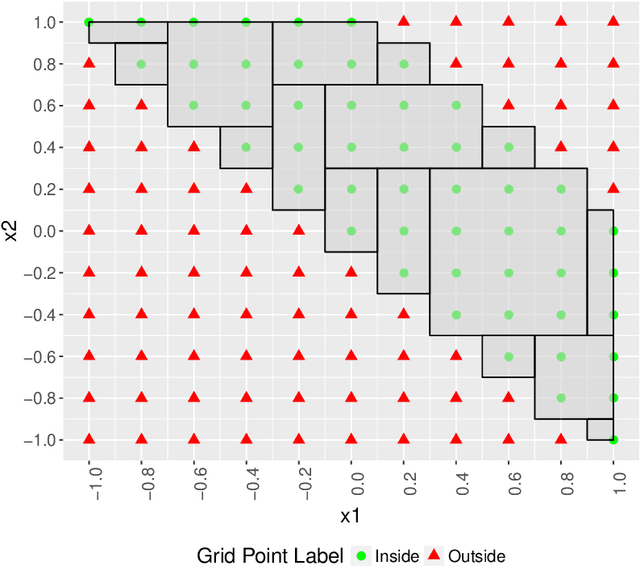
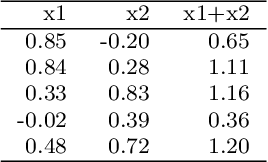
Industrial process control systems try to keep an output variable within a given tolerance around a target value. PID control systems have been widely used in industry to control input variables in order to reach this goal. However, this kind of Transfer Function based approach cannot be extended to complex processes where input data might be non-numeric, high dimensional, sparse, etc. In such cases, there is still a need for determining the subspace of input data that produces an output within a given range. This paper presents a non-stochastic heuristic to determine input values for a mathematical function or trained regression model given an output range. The proposed method creates a synthetic training data set of input combinations with a class label that indicates whether the output is within the given target range or not. Then, a decision tree classifier is used to determine the subspace of input data of interest. This method is more general than a traditional controller as the target range for the output does not have to be centered around a reference value and it can be applied given a regression model of the output variable, which may have categorical variables as inputs and may be high dimensional, sparse... The proposed heuristic is validated with a proof of concept on a real use case where the quality of a lamination factory is established to identify the suitable subspace of production variable values.
Trace transform based method for color image domain identification
Nov 26, 2012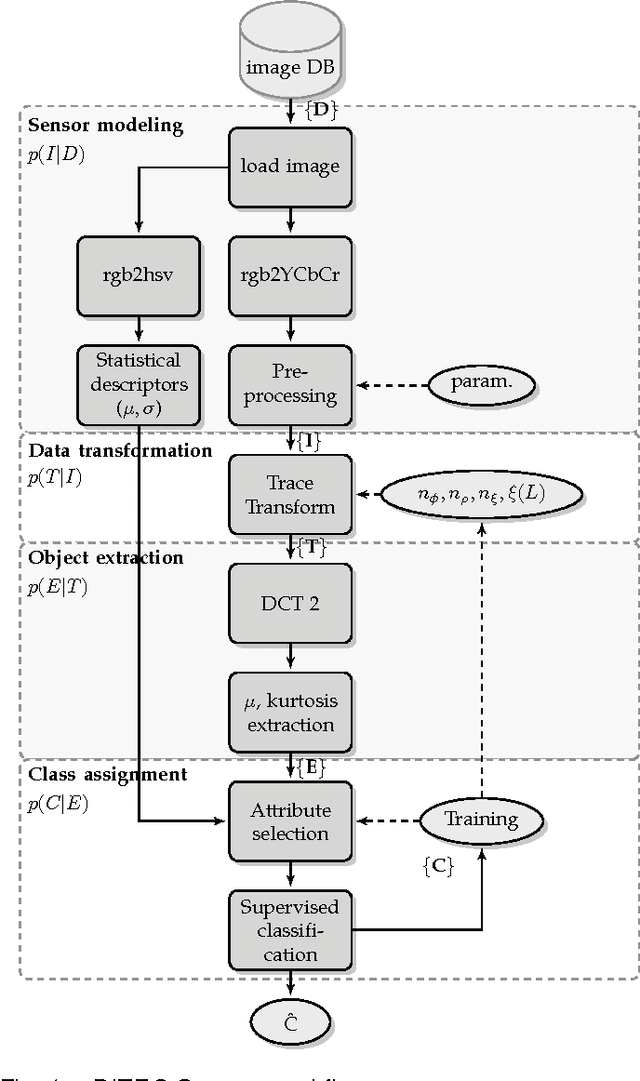
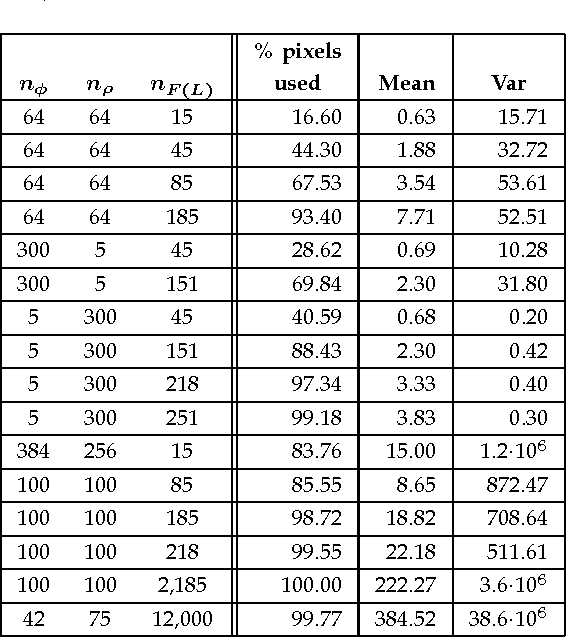
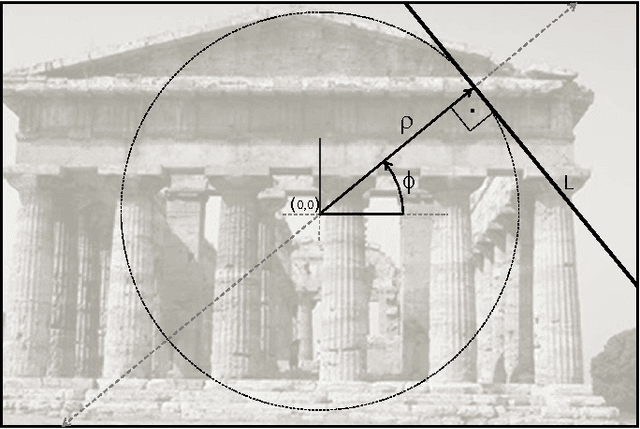
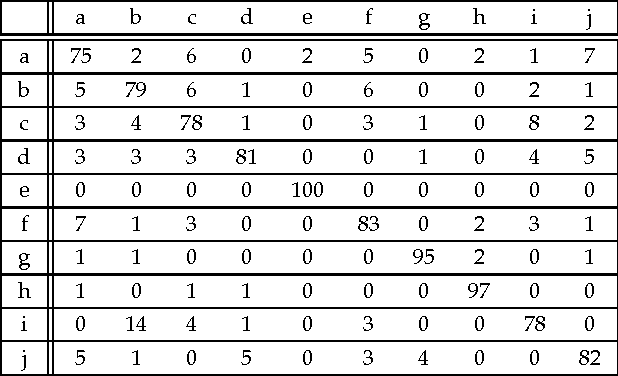
Context categorization is a fundamental pre-requisite for multi-domain multimedia content analysis applications in order to manage contextual information in an efficient manner. In this paper, we introduce a new color image context categorization method (DITEC) based on the trace transform. The problem of dimensionality reduction of the obtained trace transform signal is addressed through statistical descriptors that keep the underlying information. These extracted features offer a highly discriminant behavior for content categorization. The theoretical properties of the method are analyzed and validated experimentally through two different datasets.