 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBifurcated Remaining Useful Life Prediction: A Hybrid Approach for Realistic Uncertainty Characterization
May 29, 2026This study presents a novel hybrid prognostic framework for uncertainty-aware Remaining Useful Life (RUL) estimation in turbofan engines using the NASA C-MAPSS dataset. The framework employs a state-aware strategy that bifurcates the engines operational lifespan into "healthy" and "degraded" regimes. An LSTM-based autoencoder, trained strictly on nominal data (RUL > 150 cycles), monitors reconstruction error to act as a robust state classifier. For the healthy regime, a Conditional Weibull Survival Analysis is used for Mean Residual Life estimation. For the degraded regime, a Probabilistic Neural Network with Monte Carlo Dropout captures both aleatoric and epistemic uncertainties. Rather than using rigid binary labels, a calibrated sigmoid function converts the autoencoders output into continuous state probabilities, dynamically weighting the final ensemble prediction. The primary strength of this framework is its generation of physically consistent uncertainty bands, yielding high-confidence predictions near end-of-life while accurately reflecting the inherent variance of early operation, providing a robust tool for risk-informed maintenance.
Exploring Multi-Agent Reinforcement Learning for Unrelated Parallel Machine Scheduling
Nov 12, 2024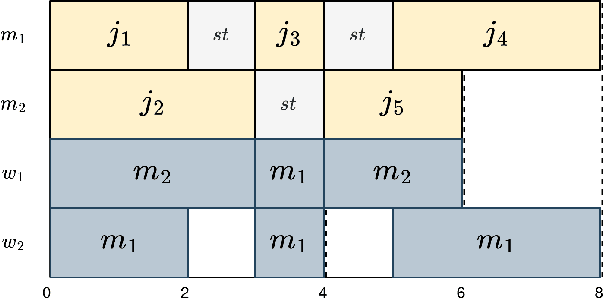



Scheduling problems pose significant challenges in resource, industry, and operational management. This paper addresses the Unrelated Parallel Machine Scheduling Problem (UPMS) with setup times and resources using a Multi-Agent Reinforcement Learning (MARL) approach. The study introduces the Reinforcement Learning environment and conducts empirical analyses, comparing MARL with Single-Agent algorithms. The experiments employ various deep neural network policies for single- and Multi-Agent approaches. Results demonstrate the efficacy of the Maskable extension of the Proximal Policy Optimization (PPO) algorithm in Single-Agent scenarios and the Multi-Agent PPO algorithm in Multi-Agent setups. While Single-Agent algorithms perform adequately in reduced scenarios, Multi-Agent approaches reveal challenges in cooperative learning but a scalable capacity. This research contributes insights into applying MARL techniques to scheduling optimization, emphasizing the need for algorithmic sophistication balanced with scalability for intelligent scheduling solutions.
Integrated Water Resource Management in the Segura Hydrographic Basin: An Artificial Intelligence Approach
Nov 11, 2024


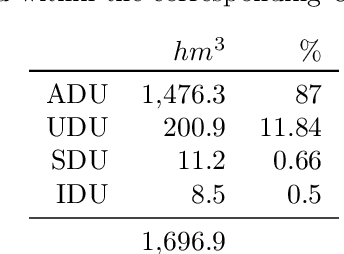
Managing resources effectively in uncertain demand, variable availability, and complex governance policies is a significant challenge. This paper presents a paradigmatic framework for addressing these issues in water management scenarios by integrating advanced physical modelling, remote sensing techniques, and Artificial Intelligence algorithms. The proposed approach accurately predicts water availability, estimates demand, and optimizes resource allocation on both short- and long-term basis, combining a comprehensive hydrological model, agronomic crop models for precise demand estimation, and Mixed-Integer Linear Programming for efficient resource distribution. In the study case of the Segura Hydrographic Basin, the approach successfully allocated approximately 642 million cubic meters ($hm^3$) of water over six months, minimizing the deficit to 9.7% of the total estimated demand. The methodology demonstrated significant environmental benefits, reducing CO2 emissions while optimizing resource distribution. This robust solution supports informed decision-making processes, ensuring sustainable water management across diverse contexts. The generalizability of this approach allows its adaptation to other basins, contributing to improved governance and policy implementation on a broader scale. Ultimately, the methodology has been validated and integrated into the operational water management practices in the Segura Hydrographic Basin in Spain.
* 15 pages, 14 figures, 8 tables
Rotational augmentation techniques: a new perspective on ensemble learning for image classification
Jun 12, 2023The popularity of data augmentation techniques in machine learning has increased in recent years, as they enable the creation of new samples from existing datasets. Rotational augmentation, in particular, has shown great promise by revolving images and utilising them as additional data points for training. This research study introduces a new approach to enhance the performance of classification methods where the testing sets were generated employing transformations on every image from the original dataset. Subsequently, ensemble-based systems were implemented to determine the most reliable outcome in each subset acquired from the augmentation phase to get a final prediction for every original image. The findings of this study suggest that rotational augmentation techniques can significantly improve the accuracy of standard classification models; and the selection of a voting scheme can considerably impact the model's performance. Overall, the study found that using an ensemble-based voting system produced more accurate results than simple voting.
dbcsp: User-friendly R package for Distance-Based Common Spacial Patterns
Sep 02, 2021
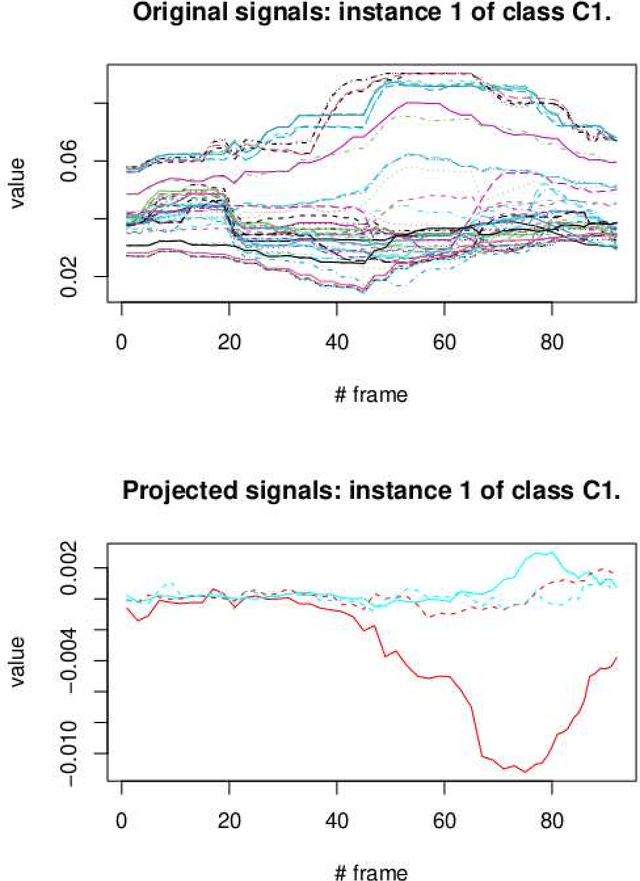
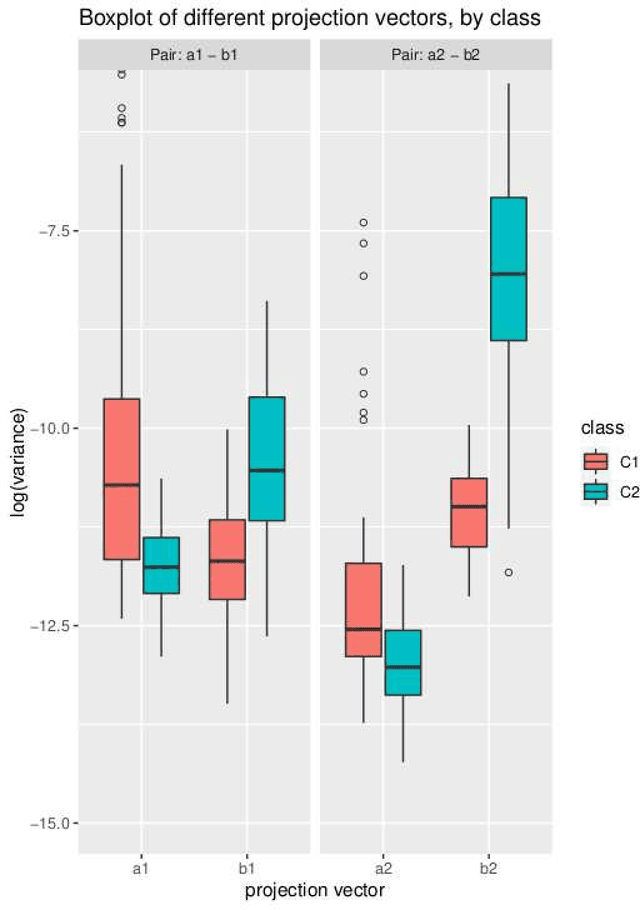
Common Spacial Patterns (CSP) is a widely used method to analyse electroencephalography (EEG) data, concerning the supervised classification of brain's activity. More generally, it can be useful to distinguish between multivariate signals recorded during a time span for two different classes. CSP is based on the simultaneous diagonalization of the average covariance matrices of signals from both classes and it allows to project the data into a low-dimensional subspace. Once data are represented in a low-dimensional subspace, a classification step must be carried out. The original CSP method is based on the Euclidean distance between signals and here, we extend it so that it can be applied on any appropriate distance for data at hand. Both, the classical CSP and the new Distance-Based CSP (DB-CSP) are implemented in an R package, called dbcsp.
MFR 2021: Masked Face Recognition Competition
Jun 29, 2021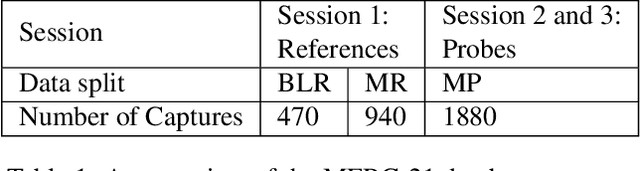

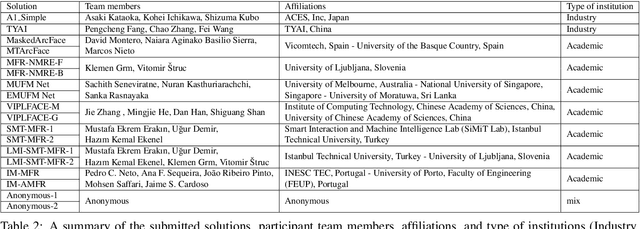
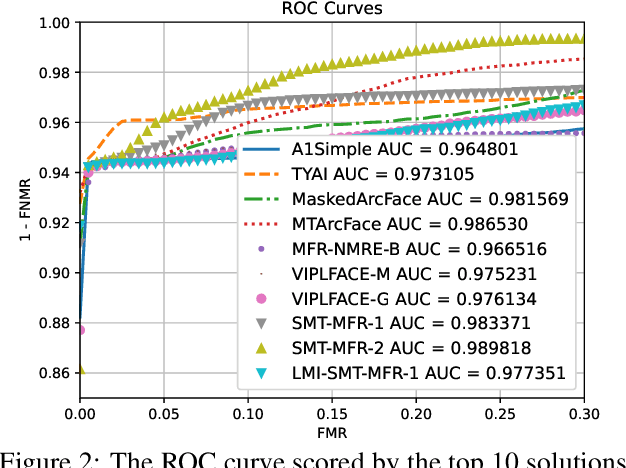
This paper presents a summary of the Masked Face Recognition Competitions (MFR) held within the 2021 International Joint Conference on Biometrics (IJCB 2021). The competition attracted a total of 10 participating teams with valid submissions. The affiliations of these teams are diverse and associated with academia and industry in nine different countries. These teams successfully submitted 18 valid solutions. The competition is designed to motivate solutions aiming at enhancing the face recognition accuracy of masked faces. Moreover, the competition considered the deployability of the proposed solutions by taking the compactness of the face recognition models into account. A private dataset representing a collaborative, multi-session, real masked, capture scenario is used to evaluate the submitted solutions. In comparison to one of the top-performing academic face recognition solutions, 10 out of the 18 submitted solutions did score higher masked face verification accuracy.
Efficient Large-Scale Face Clustering Using an Online Mixture of Gaussians
Mar 31, 2021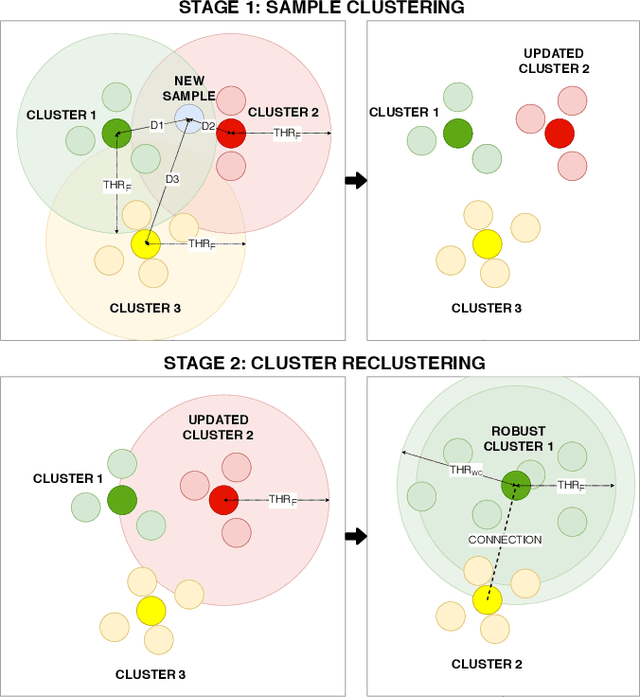
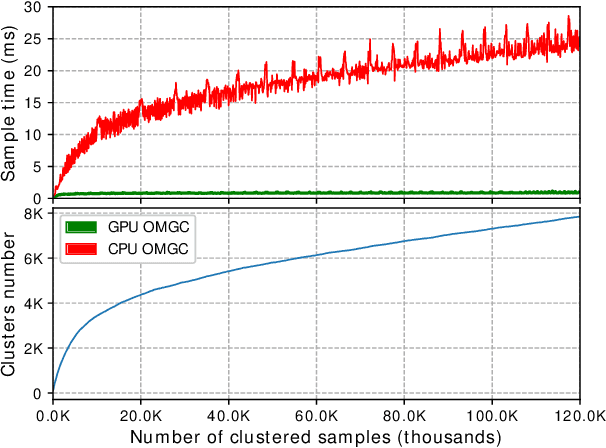


In this work, we address the problem of large-scale online face clustering: given a continuous stream of unknown faces, create a database grouping the incoming faces by their identity. The database must be updated every time a new face arrives. In addition, the solution must be efficient, accurate and scalable. For this purpose, we present an online gaussian mixture-based clustering method (OGMC). The key idea of this method is the proposal that an identity can be represented by more than just one distribution or cluster. Using feature vectors (f-vectors) extracted from the incoming faces, OGMC generates clusters that may be connected to others depending on their proximity and their robustness. Every time a cluster is updated with a new sample, its connections are also updated. With this approach, we reduce the dependency of the clustering process on the order and the size of the incoming data and we are able to deal with complex data distributions. Experimental results show that the proposed approach outperforms state-of-the-art clustering methods on large-scale face clustering benchmarks not only in accuracy, but also in efficiency and scalability.
2D Image Features Detector And Descriptor Selection Expert System
Jun 04, 2020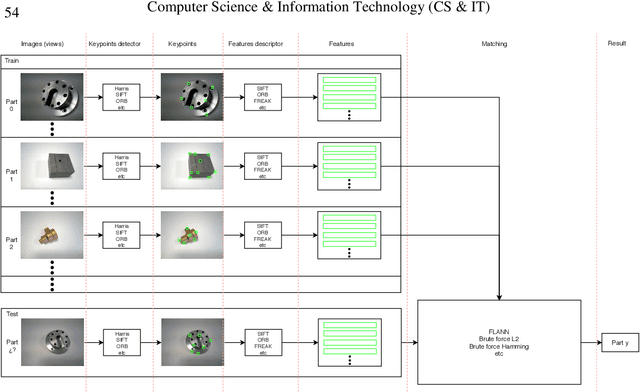
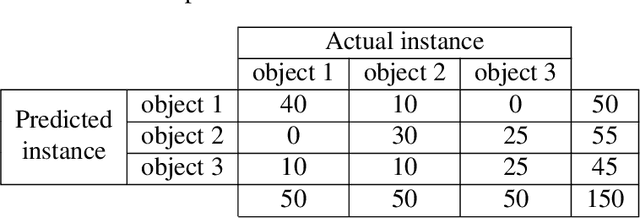
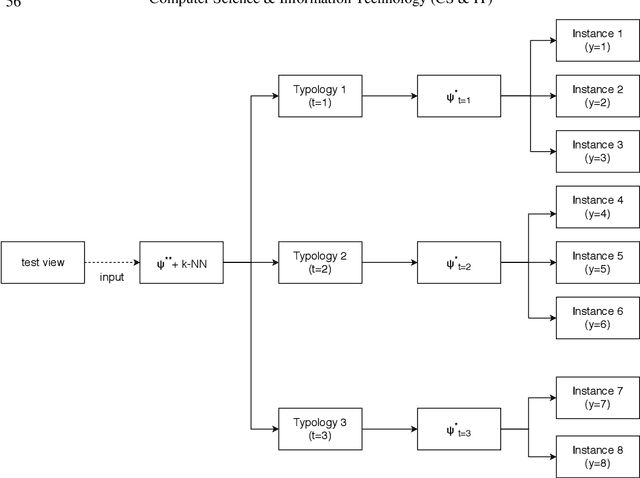

Detection and description of keypoints from an image is a well-studied problem in Computer Vision. Some methods like SIFT, SURF or ORB are computationally really efficient. This paper proposes a solution for a particular case study on object recognition of industrial parts based on hierarchical classification. Reducing the number of instances leads to better performance, indeed, that is what the use of the hierarchical classification is looking for. We demonstrate that this method performs better than using just one method like ORB, SIFT or FREAK, despite being fairly slower.
* 10 pages, 5 figures, 5 tables
Trace transform based method for color image domain identification
Nov 26, 2012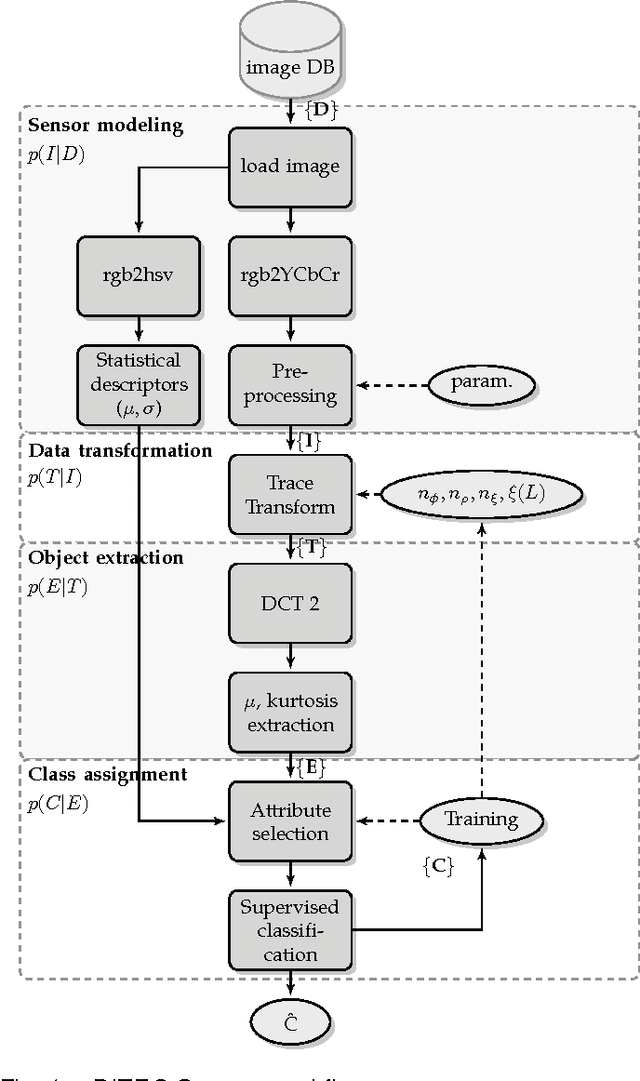
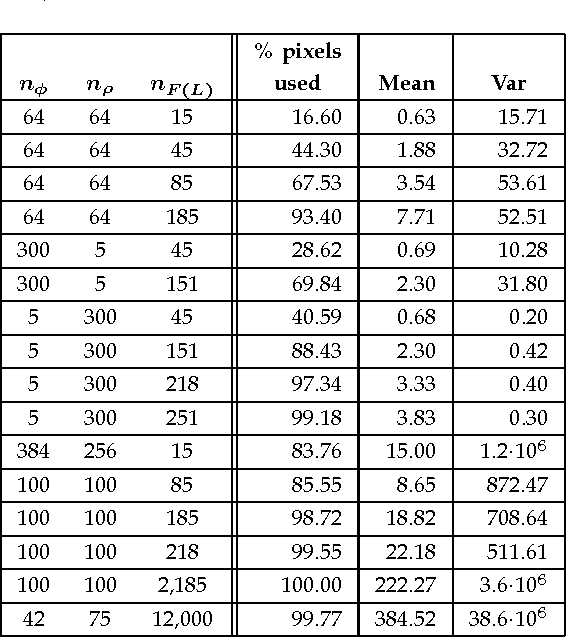
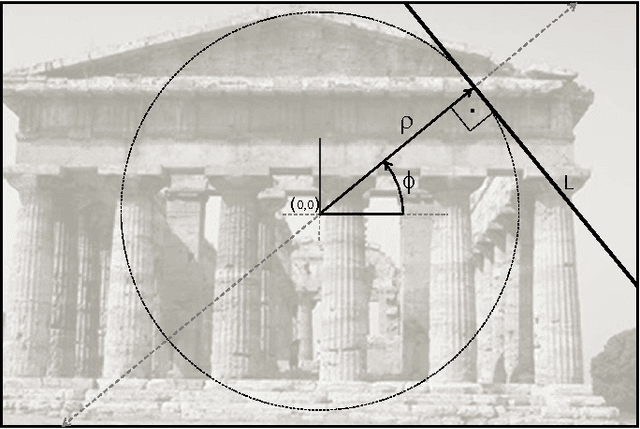
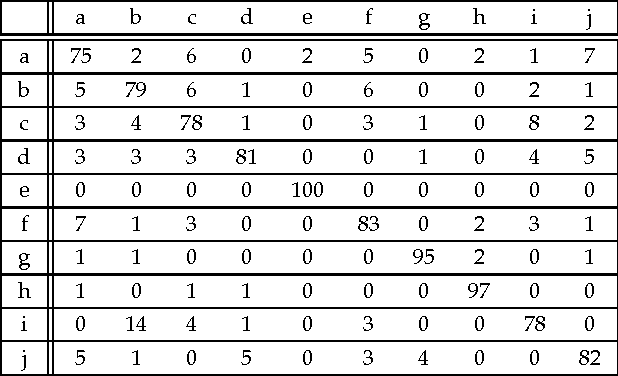
Context categorization is a fundamental pre-requisite for multi-domain multimedia content analysis applications in order to manage contextual information in an efficient manner. In this paper, we introduce a new color image context categorization method (DITEC) based on the trace transform. The problem of dimensionality reduction of the obtained trace transform signal is addressed through statistical descriptors that keep the underlying information. These extracted features offer a highly discriminant behavior for content categorization. The theoretical properties of the method are analyzed and validated experimentally through two different datasets.