 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic outlier generation for anomaly detection in autonomous driving
Aug 04, 2023Anomaly detection, or outlier detection, is a crucial task in various domains to identify instances that significantly deviate from established patterns or the majority of data. In the context of autonomous driving, the identification of anomalies is particularly important to prevent safety-critical incidents, as deep learning models often exhibit overconfidence in anomalous or outlier samples. In this study, we explore different strategies for training an image semantic segmentation model with an anomaly detection module. By introducing modifications to the training stage of the state-of-the-art DenseHybrid model, we achieve significant performance improvements in anomaly detection. Moreover, we propose a simplified detector that achieves comparable results to our modified DenseHybrid approach, while also surpassing the performance of the original DenseHybrid model. These findings demonstrate the efficacy of our proposed strategies for enhancing anomaly detection in the context of autonomous driving.
Rotational augmentation techniques: a new perspective on ensemble learning for image classification
Jun 12, 2023The popularity of data augmentation techniques in machine learning has increased in recent years, as they enable the creation of new samples from existing datasets. Rotational augmentation, in particular, has shown great promise by revolving images and utilising them as additional data points for training. This research study introduces a new approach to enhance the performance of classification methods where the testing sets were generated employing transformations on every image from the original dataset. Subsequently, ensemble-based systems were implemented to determine the most reliable outcome in each subset acquired from the augmentation phase to get a final prediction for every original image. The findings of this study suggest that rotational augmentation techniques can significantly improve the accuracy of standard classification models; and the selection of a voting scheme can considerably impact the model's performance. Overall, the study found that using an ensemble-based voting system produced more accurate results than simple voting.
MFR 2021: Masked Face Recognition Competition
Jun 29, 2021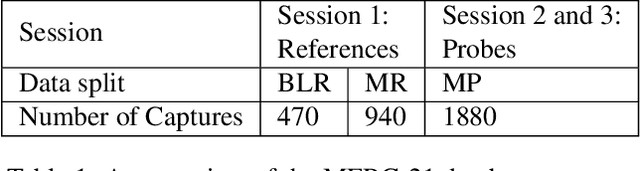

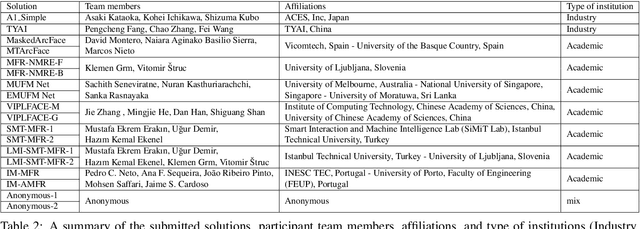
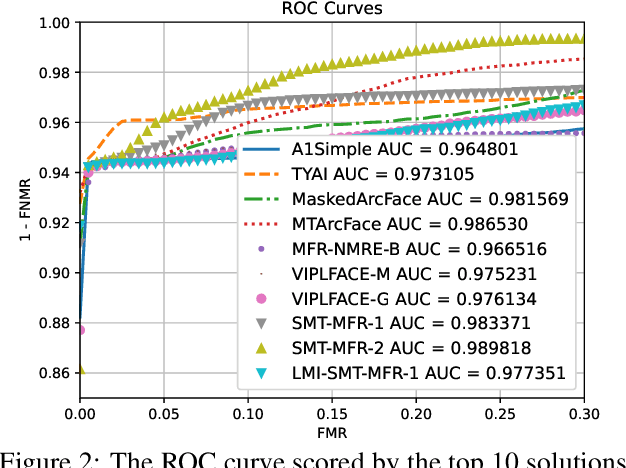
This paper presents a summary of the Masked Face Recognition Competitions (MFR) held within the 2021 International Joint Conference on Biometrics (IJCB 2021). The competition attracted a total of 10 participating teams with valid submissions. The affiliations of these teams are diverse and associated with academia and industry in nine different countries. These teams successfully submitted 18 valid solutions. The competition is designed to motivate solutions aiming at enhancing the face recognition accuracy of masked faces. Moreover, the competition considered the deployability of the proposed solutions by taking the compactness of the face recognition models into account. A private dataset representing a collaborative, multi-session, real masked, capture scenario is used to evaluate the submitted solutions. In comparison to one of the top-performing academic face recognition solutions, 10 out of the 18 submitted solutions did score higher masked face verification accuracy.
Boosting Masked Face Recognition with Multi-Task ArcFace
Apr 21, 2021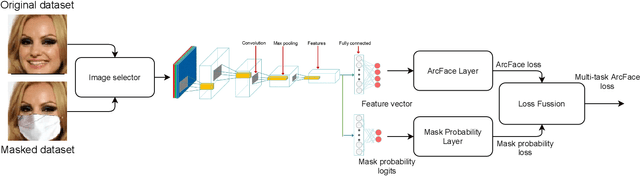
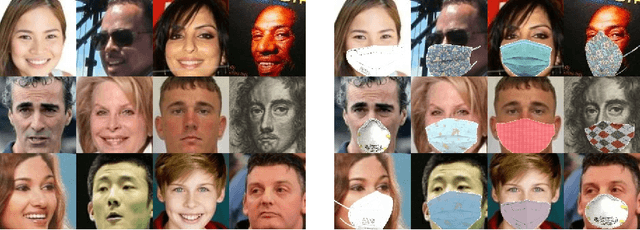
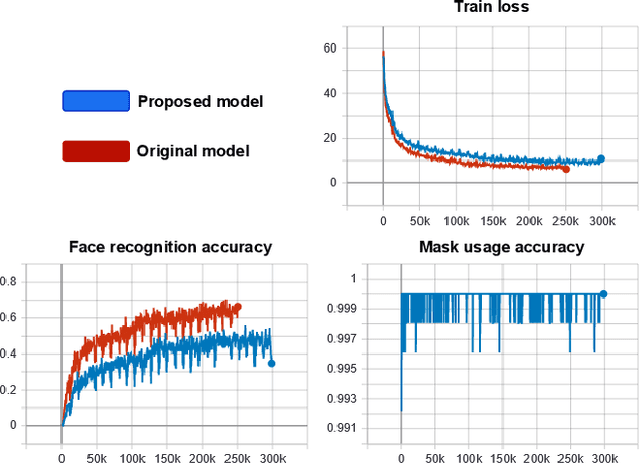

In this paper, we address the problem of face recognition with masks. Given the global health crisis caused by COVID-19, mouth and nose-covering masks have become an essential everyday-clothing-accessory. This sanitary measure has put the state-of-the-art face recognition models on the ropes since they have not been designed to work with masked faces. In addition, the need has arisen for applications capable of detecting whether the subjects are wearing masks to control the spread of the virus. To overcome these problems a full training pipeline is presented based on the ArcFace work, with several modifications for the backbone and the loss function. From the original face-recognition dataset, a masked version is generated using data augmentation, and both datasets are combined during the training process. The selected network, based on ResNet-50, is modified to also output the probability of mask usage without adding any computational cost. Furthermore, the ArcFace loss is combined with the mask-usage classification loss, resulting in a new function named Multi-Task ArcFace (MTArcFace). Experimental results show that the proposed approach highly boosts the original model accuracy when dealing with masked faces, while preserving almost the same accuracy on the original non-masked datasets. Furthermore, it achieves an average accuracy of 99.78% in mask-usage classification.
Efficient Large-Scale Face Clustering Using an Online Mixture of Gaussians
Mar 31, 2021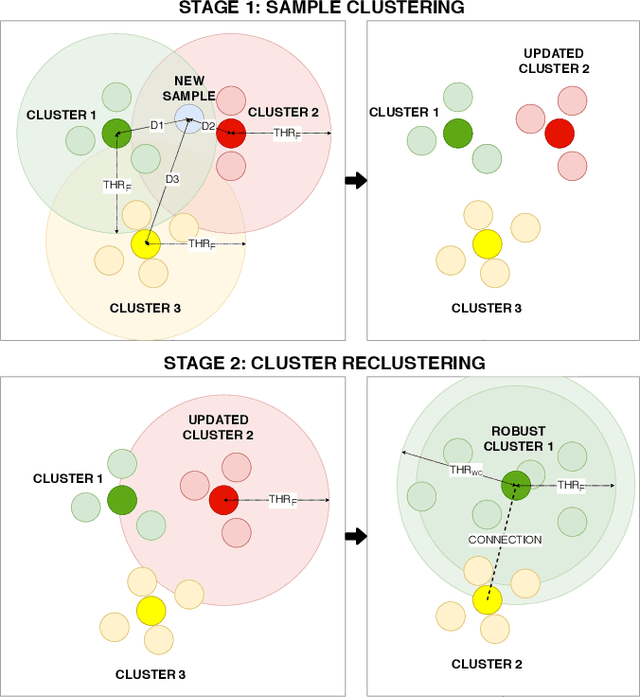
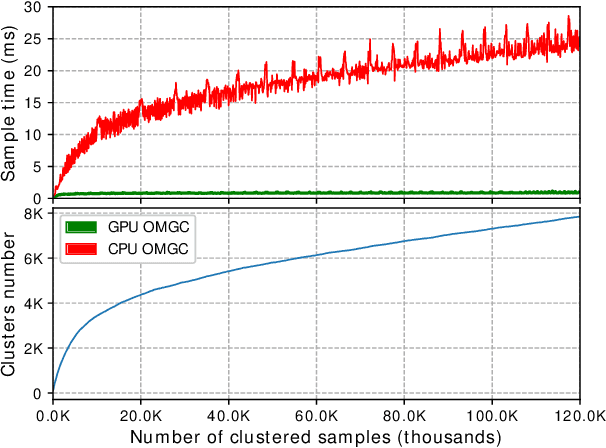


In this work, we address the problem of large-scale online face clustering: given a continuous stream of unknown faces, create a database grouping the incoming faces by their identity. The database must be updated every time a new face arrives. In addition, the solution must be efficient, accurate and scalable. For this purpose, we present an online gaussian mixture-based clustering method (OGMC). The key idea of this method is the proposal that an identity can be represented by more than just one distribution or cluster. Using feature vectors (f-vectors) extracted from the incoming faces, OGMC generates clusters that may be connected to others depending on their proximity and their robustness. Every time a cluster is updated with a new sample, its connections are also updated. With this approach, we reduce the dependency of the clustering process on the order and the size of the incoming data and we are able to deal with complex data distributions. Experimental results show that the proposed approach outperforms state-of-the-art clustering methods on large-scale face clustering benchmarks not only in accuracy, but also in efficiency and scalability.