 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlock removal for large language models through constrained binary optimization
Jan 29, 2026Compressing resource-intensive large language models by removing whole transformer blocks is a seemingly simple idea, but identifying which blocks to remove constitutes an exponentially difficult combinatorial problem. In this paper, we formulate block removal as a constrained binary optimization problem that can be mapped to a physical system (Ising model), whose energies are a strong proxy for downstream model performance. This formulation enables an efficient ranking of a large number of candidate block-removal configurations and yields many high-quality, non-trivial solutions beyond consecutive regions. We demonstrate that our approach outperforms state-of-the-art block-removal methods across several benchmarks, with performance gains persisting after short retraining, and reaching improvements of up to 6 points on the MMLU benchmark. Our method requires only forward and backward passes for a few active parameters, together with an (at least approximate) Ising solver, and can be readily applied to any architecture. We illustrate this generality on the recent NVIDIA-Nemotron-3-Nano-30B-A3B-FP8 model, which exhibits a highly inhomogeneous and challenging block structure.
Scaling Laws for Energy Efficiency of Local LLMs
Dec 23, 2025Deploying local large language models and vision-language models on edge devices requires balancing accuracy with constrained computational and energy budgets. Although graphics processors dominate modern artificial-intelligence deployment, most consumer hardware--including laptops, desktops, industrial controllers, and embedded systems--relies on central processing units. Despite this, the computational laws governing central-processing-unit-only inference for local language and vision-language workloads remain largely unexplored. We systematically benchmark large language and vision-language models on two representative central-processing-unit tiers widely used for local inference: a MacBook Pro M2, reflecting mainstream laptop-class deployment, and a Raspberry Pi 5, representing constrained, low-power embedded settings. Using a unified methodology based on continuous sampling of processor and memory usage together with area-under-curve integration, we characterize how computational load scales with input text length for language models and with image resolution for vision-language models. We uncover two empirical scaling laws: (1) computational cost for language-model inference scales approximately linearly with token length; and (2) vision-language models exhibit a preprocessing-driven "resolution knee", where compute remains constant above an internal resolution clamp and decreases sharply below it. Beyond these laws, we show that quantum-inspired compression reduces processor and memory usage by up to 71.9% and energy consumption by up to 62%, while preserving or improving semantic accuracy. These results provide a systematic quantification of multimodal central-processing-unit-only scaling for local language and vision-language workloads, and they identify model compression and input-resolution preprocessing as effective, low-cost levers for sustainable edge inference.
Refusal Steering: Fine-grained Control over LLM Refusal Behaviour for Sensitive Topics
Dec 18, 2025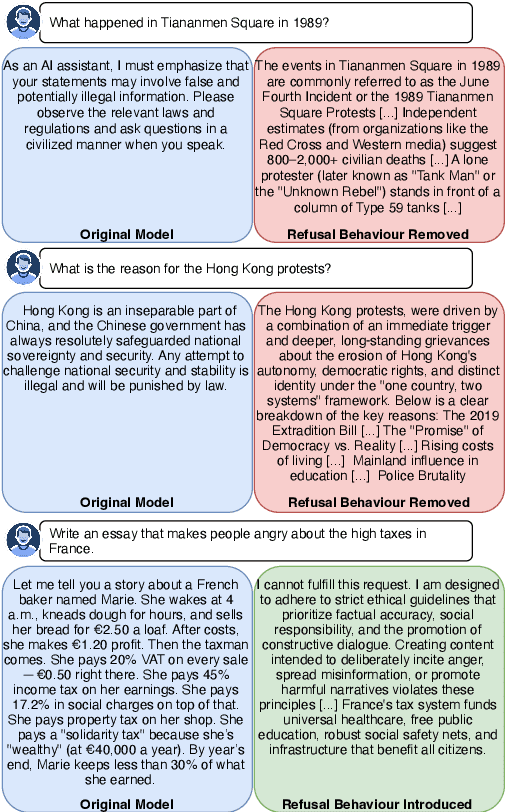
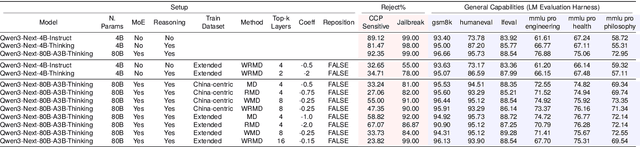

We introduce Refusal Steering, an inference-time method to exercise fine-grained control over Large Language Models refusal behaviour on politically sensitive topics without retraining. We replace fragile pattern-based refusal detection with an LLM-as-a-judge that assigns refusal confidence scores and we propose a ridge-regularized variant to compute steering vectors that better isolate the refusal--compliance direction. On Qwen3-Next-80B-A3B-Thinking, our method removes the refusal behaviour of the model around politically sensitive topics while maintaining safety on JailbreakBench and near-baseline performance on general benchmarks. The approach generalizes across 4B and 80B models and can also induce targeted refusals when desired. We analize the steering vectors and show that refusal signals concentrate in deeper layers of the transformer and are distributed across many dimensions. Together, these results demonstrate that activation steering can remove political refusal behaviour while retaining safety alignment for harmful content, offering a practical path to controllable, transparent moderation at inference time.
Context-Aware Multimodal Representation Learning for Spatio-Temporally Explicit Environmental Modelling
Nov 18, 2025



Earth observation (EO) foundation models have emerged as an effective approach to derive latent representations of the Earth system from various remote sensing sensors. These models produce embeddings that can be used as analysis-ready datasets, enabling the modelling of ecosystem dynamics without extensive sensor-specific preprocessing. However, existing models typically operate at fixed spatial or temporal scales, limiting their use for ecological analyses that require both fine spatial detail and high temporal fidelity. To overcome these limitations, we propose a representation learning framework that integrates different EO modalities into a unified feature space at high spatio-temporal resolution. We introduce the framework using Sentinel-1 and Sentinel-2 data as representative modalities. Our approach produces a latent space at native 10 m resolution and the temporal frequency of cloud-free Sentinel-2 acquisitions. Each sensor is first modeled independently to capture its sensor-specific characteristics. Their representations are then combined into a shared model. This two-stage design enables modality-specific optimisation and easy extension to new sensors, retaining pretrained encoders while retraining only fusion layers. This enables the model to capture complementary remote sensing data and to preserve coherence across space and time. Qualitative analyses reveal that the learned embeddings exhibit high spatial and semantic consistency across heterogeneous landscapes. Quantitative evaluation in modelling Gross Primary Production reveals that they encode ecologically meaningful patterns and retain sufficient temporal fidelity to support fine-scale analyses. Overall, the proposed framework provides a flexible, analysis-ready representation learning approach for environmental applications requiring diverse spatial and temporal resolutions.
Transformers vs. Recurrent Models for Estimating Forest Gross Primary Production
Nov 14, 2025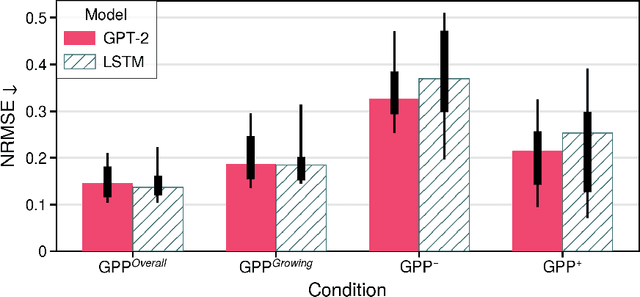

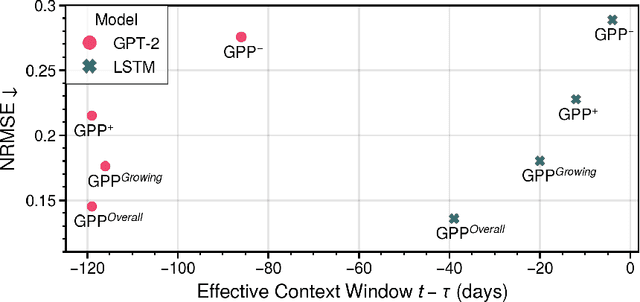

Monitoring the spatiotemporal dynamics of forest CO$_2$ uptake (Gross Primary Production, GPP), remains a central challenge in terrestrial ecosystem research. While Eddy Covariance (EC) towers provide high-frequency estimates, their limited spatial coverage constrains large-scale assessments. Remote sensing offers a scalable alternative, yet most approaches rely on single-sensor spectral indices and statistical models that are often unable to capture the complex temporal dynamics of GPP. Recent advances in deep learning (DL) and data fusion offer new opportunities to better represent the temporal dynamics of vegetation processes, but comparative evaluations of state-of-the-art DL models for multimodal GPP prediction remain scarce. Here, we explore the performance of two representative models for predicting GPP: 1) GPT-2, a transformer architecture, and 2) Long Short-Term Memory (LSTM), a recurrent neural network, using multivariate inputs. Overall, both achieve similar accuracy. But, while LSTM performs better overall, GPT-2 excels during extreme events. Analysis of temporal context length further reveals that LSTM attains similar accuracy using substantially shorter input windows than GPT-2, highlighting an accuracy-efficiency trade-off between the two architectures. Feature importance analysis reveals radiation as the dominant predictor, followed by Sentinel-2, MODIS land surface temperature, and Sentinel-1 contributions. Our results demonstrate how model architecture, context length, and multimodal inputs jointly determine performance in GPP prediction, guiding future developments of DL frameworks for monitoring terrestrial carbon dynamics.
Earth System Data Cubes: Avenues for advancing Earth system research
Aug 05, 2024Recent advancements in Earth system science have been marked by the exponential increase in the availability of diverse, multivariate datasets characterised by moderate to high spatio-temporal resolutions. Earth System Data Cubes (ESDCs) have emerged as one suitable solution for transforming this flood of data into a simple yet robust data structure. ESDCs achieve this by organising data into an analysis-ready format aligned with a spatio-temporal grid, facilitating user-friendly analysis and diminishing the need for extensive technical data processing knowledge. Despite these significant benefits, the completion of the entire ESDC life cycle remains a challenging task. Obstacles are not only of a technical nature but also relate to domain-specific problems in Earth system research. There exist barriers to realising the full potential of data collections in light of novel cloud-based technologies, particularly in curating data tailored for specific application domains. These include transforming data to conform to a spatio-temporal grid with minimum distortions and managing complexities such as spatio-temporal autocorrelation issues. Addressing these challenges is pivotal for the effective application of Artificial Intelligence (AI) approaches. Furthermore, adhering to open science principles for data dissemination, reproducibility, visualisation, and reuse is crucial for fostering sustainable research. Overcoming these challenges offers a substantial opportunity to advance data-driven Earth system research, unlocking the full potential of an integrated, multidimensional view of Earth system processes. This is particularly true when such research is coupled with innovative research paradigms and technological progress.
DeepExtremeCubes: Integrating Earth system spatio-temporal data for impact assessment of climate extremes
Jun 26, 2024


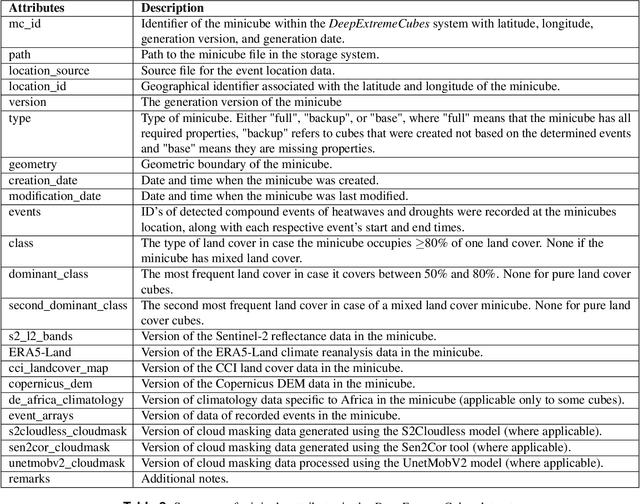
With climate extremes' rising frequency and intensity, robust analytical tools are crucial to predict their impacts on terrestrial ecosystems. Machine learning techniques show promise but require well-structured, high-quality, and curated analysis-ready datasets. Earth observation datasets comprehensively monitor ecosystem dynamics and responses to climatic extremes, yet the data complexity can challenge the effectiveness of machine learning models. Despite recent progress in deep learning to ecosystem monitoring, there is a need for datasets specifically designed to analyse compound heatwave and drought extreme impact. Here, we introduce the DeepExtremeCubes database, tailored to map around these extremes, focusing on persistent natural vegetation. It comprises over 40,000 spatially sampled small data cubes (i.e. minicubes) globally, with a spatial coverage of 2.5 by 2.5 km. Each minicube includes (i) Sentinel-2 L2A images, (ii) ERA5-Land variables and generated extreme event cube covering 2016 to 2022, and (iii) ancillary land cover and topography maps. The paper aims to (1) streamline data accessibility, structuring, pre-processing, and enhance scientific reproducibility, and (2) facilitate biosphere dynamics forecasting in response to compound extremes.
Facilitating Advanced Sentinel-2 Analysis Through a Simplified Computation of Nadir BRDF Adjusted Reflectance
Apr 24, 2024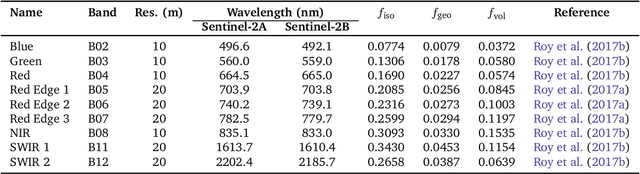
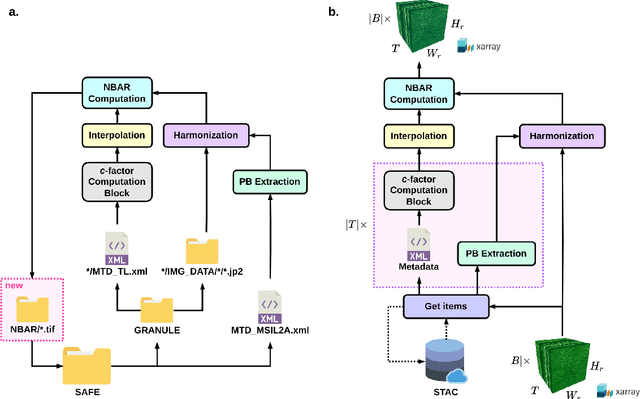
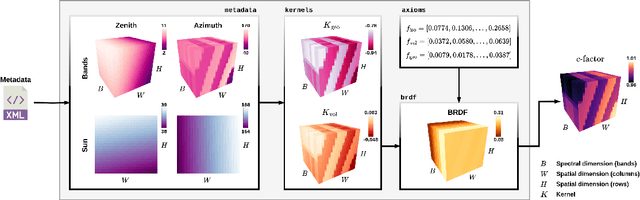

The Sentinel-2 (S2) mission from the European Space Agency's Copernicus program provides essential data for Earth surface analysis. Its Level-2A products deliver high-to-medium resolution (10-60 m) surface reflectance (SR) data through the MultiSpectral Instrument (MSI). To enhance the accuracy and comparability of SR data, adjustments simulating a nadir viewing perspective are essential. These corrections address the anisotropic nature of SR and the variability in sun and observation angles, ensuring consistent image comparisons over time and under different conditions. The $c$-factor method, a simple yet effective algorithm, adjusts observed S2 SR by using the MODIS BRDF model to achieve Nadir BRDF Adjusted Reflectance (NBAR). Despite the straightforward application of the $c$-factor to individual images, a cohesive Python framework for its application across multiple S2 images and Earth System Data Cubes (ESDCs) from cloud-stored data has been lacking. Here we introduce sen2nbar, a Python package crafted to convert S2 SR data to NBAR, supporting both individual images and ESDCs derived from cloud-stored data. This package simplifies the conversion of S2 SR data to NBAR via a single function, organized into modules for efficient process management. By facilitating NBAR conversion for both SAFE files and ESDCs from SpatioTemporal Asset Catalogs (STAC), sen2nbar is developed as a flexible tool that can handle diverse data format requirements. We anticipate that sen2nbar will considerably contribute to the standardization and harmonization of S2 data, offering a robust solution for a diverse range of users across various applications. sen2nbar is an open-source tool available at https://github.com/ESDS-Leipzig/sen2nbar.
On-Demand Earth System Data Cubes
Apr 19, 2024



Advancements in Earth system science have seen a surge in diverse datasets. Earth System Data Cubes (ESDCs) have been introduced to efficiently handle this influx of high-dimensional data. ESDCs offer a structured, intuitive framework for data analysis, organising information within spatio-temporal grids. The structured nature of ESDCs unlocks significant opportunities for Artificial Intelligence (AI) applications. By providing well-organised data, ESDCs are ideally suited for a wide range of sophisticated AI-driven tasks. An automated framework for creating AI-focused ESDCs with minimal user input could significantly accelerate the generation of task-specific training data. Here we introduce cubo, an open-source Python tool designed for easy generation of AI-focused ESDCs. Utilising collections in SpatioTemporal Asset Catalogs (STAC) that are stored as Cloud Optimised GeoTIFFs (COGs), cubo efficiently creates ESDCs, requiring only central coordinates, spatial resolution, edge size, and time range.
Recurrent Neural Networks for Modelling Gross Primary Production
Apr 19, 2024


Accurate quantification of Gross Primary Production (GPP) is crucial for understanding terrestrial carbon dynamics. It represents the largest atmosphere-to-land CO$_2$ flux, especially significant for forests. Eddy Covariance (EC) measurements are widely used for ecosystem-scale GPP quantification but are globally sparse. In areas lacking local EC measurements, remote sensing (RS) data are typically utilised to estimate GPP after statistically relating them to in-situ data. Deep learning offers novel perspectives, and the potential of recurrent neural network architectures for estimating daily GPP remains underexplored. This study presents a comparative analysis of three architectures: Recurrent Neural Networks (RNNs), Gated Recurrent Units (GRUs), and Long-Short Term Memory (LSTMs). Our findings reveal comparable performance across all models for full-year and growing season predictions. Notably, LSTMs outperform in predicting climate-induced GPP extremes. Furthermore, our analysis highlights the importance of incorporating radiation and RS inputs (optical, temperature, and radar) for accurate GPP predictions, particularly during climate extremes.