 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fully Interpretable Statistical Approach for Roadside LiDAR Background Subtraction
Oct 25, 2025



We present a fully interpretable and flexible statistical method for background subtraction in roadside LiDAR data, aimed at enhancing infrastructure-based perception in automated driving. Our approach introduces both a Gaussian distribution grid (GDG), which models the spatial statistics of the background using background-only scans, and a filtering algorithm that uses this representation to classify LiDAR points as foreground or background. The method supports diverse LiDAR types, including multiline 360 degree and micro-electro-mechanical systems (MEMS) sensors, and adapts to various configurations. Evaluated on the publicly available RCooper dataset, it outperforms state-of-the-art techniques in accuracy and flexibility, even with minimal background data. Its efficient implementation ensures reliable performance on low-resource hardware, enabling scalable real-world deployment.
Occlusion-aware Driver Monitoring System using the Driver Monitoring Dataset
Apr 29, 2025This paper presents a robust, occlusion-aware driver monitoring system (DMS) utilizing the Driver Monitoring Dataset (DMD). The system performs driver identification, gaze estimation by regions, and face occlusion detection under varying lighting conditions, including challenging low-light scenarios. Aligned with EuroNCAP recommendations, the inclusion of occlusion detection enhances situational awareness and system trustworthiness by indicating when the system's performance may be degraded. The system employs separate algorithms trained on RGB and infrared (IR) images to ensure reliable functioning. We detail the development and integration of these algorithms into a cohesive pipeline, addressing the challenges of working with different sensors and real-car implementation. Evaluation on the DMD and in real-world scenarios demonstrates the effectiveness of the proposed system, highlighting the superior performance of RGB-based models and the pioneering contribution of robust occlusion detection in DMS.
Exploration of VLMs for Driver Monitoring Systems Applications
Mar 15, 2025



In recent years, we have witnessed significant progress in emerging deep learning models, particularly Large Language Models (LLMs) and Vision-Language Models (VLMs). These models have demonstrated promising results, indicating a new era of Artificial Intelligence (AI) that surpasses previous methodologies. Their extensive knowledge and zero-shot capabilities suggest a paradigm shift in developing deep learning solutions, moving from data capturing and algorithm training to just writing appropriate prompts. While the application of these technologies has been explored across various industries, including automotive, there is a notable gap in the scientific literature regarding their use in Driver Monitoring Systems (DMS). This paper presents our initial approach to implementing VLMs in this domain, utilising the Driver Monitoring Dataset to evaluate their performance and discussing their advantages and challenges when implemented in real-world scenarios.
Analysis of Classifier Training on Synthetic Data for Cross-Domain Datasets
Oct 30, 2024A major challenges of deep learning (DL) is the necessity to collect huge amounts of training data. Often, the lack of a sufficiently large dataset discourages the use of DL in certain applications. Typically, acquiring the required amounts of data costs considerable time, material and effort. To mitigate this problem, the use of synthetic images combined with real data is a popular approach, widely adopted in the scientific community to effectively train various detectors. In this study, we examined the potential of synthetic data-based training in the field of intelligent transportation systems. Our focus is on camera-based traffic sign recognition applications for advanced driver assistance systems and autonomous driving. The proposed augmentation pipeline of synthetic datasets includes novel augmentation processes such as structured shadows and gaussian specular highlights. A well-known DL model was trained with different datasets to compare the performance of synthetic and real image-based trained models. Additionally, a new, detailed method to objectively compare these models is proposed. Synthetic images are generated using a semi-supervised errors-guide method which is also described. Our experiments showed that a synthetic image-based approach outperforms in most cases real image-based training when applied to cross-domain test datasets (+10% precision for GTSRB dataset) and consequently, the generalization of the model is improved decreasing the cost of acquiring images.
* 10 pages
Dynamic Risk Assessment Methodology with an LDM-based System for Parking Scenarios
Apr 05, 2024This paper describes the methodology for building a dynamic risk assessment for ADAS (Advanced Driving Assistance Systems) algorithms in parking scenarios, fusing exterior and interior perception for a better understanding of the scene and a more comprehensive risk estimation. This includes the definition of a dynamic risk methodology that depends on the situation from inside and outside the vehicle, the creation of a multi-sensor dataset of risk assessment for ADAS benchmarking purposes, and a Local Dynamic Map (LDM) that fuses data from the exterior and interior of the car to build an LDM-based Dynamic Risk Assessment System (DRAS).
Automatic UAV-based Airport Pavement Inspection Using Mixed Real and Virtual Scenarios
Jan 11, 2024Runway and taxiway pavements are exposed to high stress during their projected lifetime, which inevitably leads to a decrease in their condition over time. To make sure airport pavement condition ensure uninterrupted and resilient operations, it is of utmost importance to monitor their condition and conduct regular inspections. UAV-based inspection is recently gaining importance due to its wide range monitoring capabilities and reduced cost. In this work, we propose a vision-based approach to automatically identify pavement distress using images captured by UAVs. The proposed method is based on Deep Learning (DL) to segment defects in the image. The DL architecture leverages the low computational capacities of embedded systems in UAVs by using an optimised implementation of EfficientNet feature extraction and Feature Pyramid Network segmentation. To deal with the lack of annotated data for training we have developed a synthetic dataset generation methodology to extend available distress datasets. We demonstrate that the use of a mixed dataset composed of synthetic and real training images yields better results when testing the training models in real application scenarios.
* 12 pages, 6 figures, published in proceedings of 15th International Conference on Machine Vision (ICMV)
LiDAR-based curb detection for ground truth annotation in automated driving validation
Dec 01, 2023



Curb detection is essential for environmental awareness in Automated Driving (AD), as it typically limits drivable and non-drivable areas. Annotated data are necessary for developing and validating an AD function. However, the number of public datasets with annotated point cloud curbs is scarce. This paper presents a method for detecting 3D curbs in a sequence of point clouds captured from a LiDAR sensor, which consists of two main steps. First, our approach detects the curbs at each scan using a segmentation deep neural network. Then, a sequence-level processing step estimates the 3D curbs in the reconstructed point cloud using the odometry of the vehicle. From these 3D points of the curb, we obtain polylines structured following ASAM OpenLABEL standard. These detections can be used as pre-annotations in labelling pipelines to efficiently generate curb-related ground truth data. We validate our approach through an experiment in which different human annotators were required to annotate curbs in a group of LiDAR-based sequences with and without our automatically generated pre-annotations. The results show that the manual annotation time is reduced by 50.99% thanks to our detections, keeping the data quality level.
Virtual passengers for real car solutions: synthetic datasets
May 13, 2022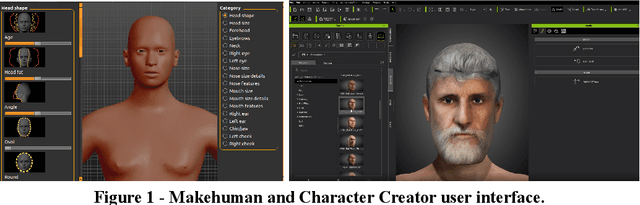


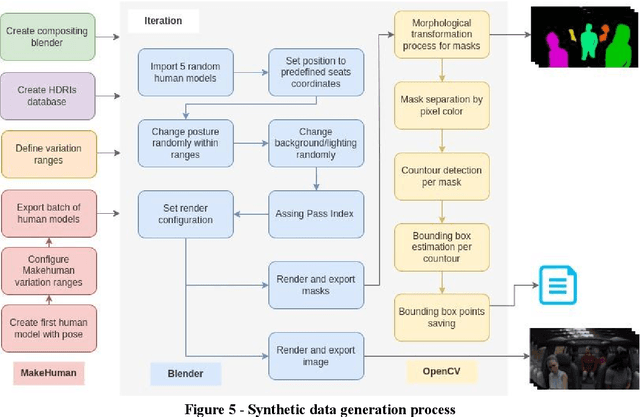
Strategies that include the generation of synthetic data are beginning to be viable as obtaining real data can be logistically complicated, very expensive or slow. Not only the capture of the data can lead to complications, but also its annotation. To achieve high-fidelity data for training intelligent systems, we have built a 3D scenario and set-up to resemble reality as closely as possible. With our approach, it is possible to configure and vary parameters to add randomness to the scene and, in this way, allow variation in data, which is so important in the construction of a dataset. Besides, the annotation task is already included in the data generation exercise, rather than being a post-capture task, which can save a lot of resources. We present the process and concept of synthetic data generation in an automotive context, specifically for driver and passenger monitoring purposes, as an alternative to real data capturing.
RTMaps-based Local Dynamic Map for multi-ADAS data fusion
May 13, 2022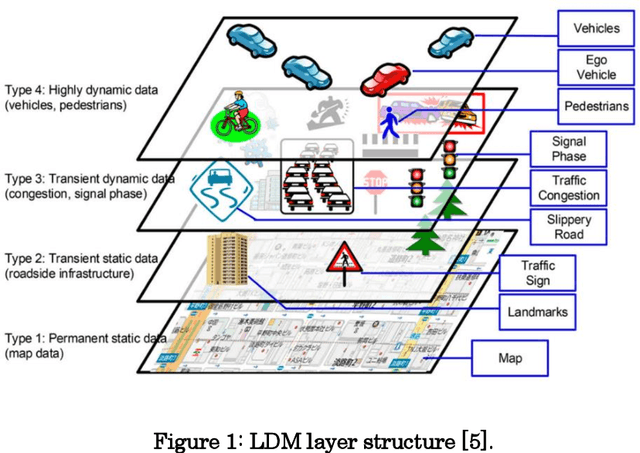
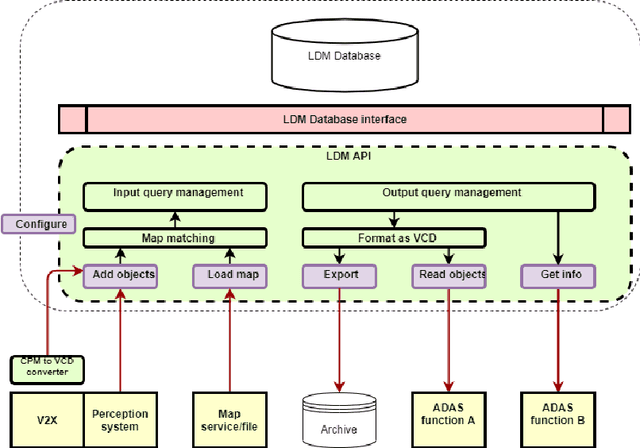
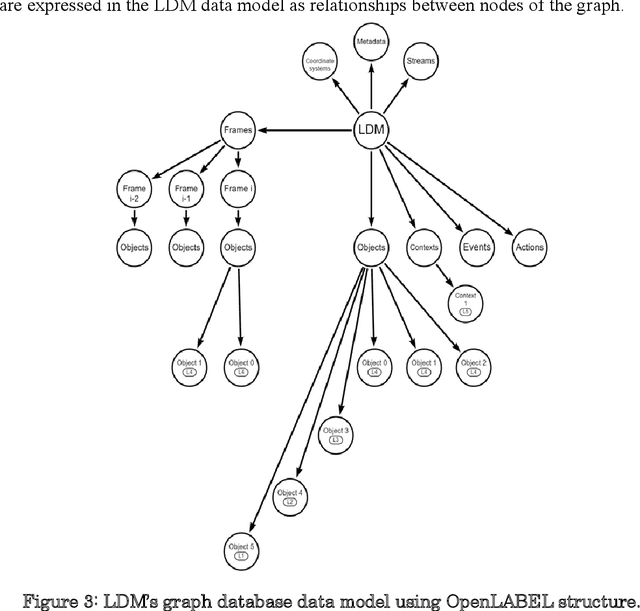
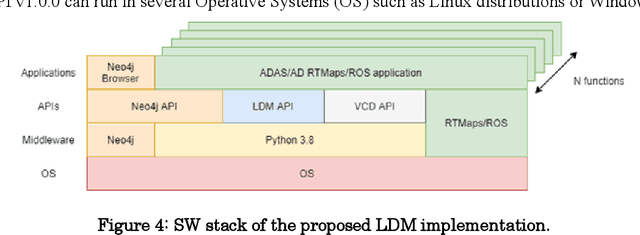
Work on Local Dynamic Maps (LDM) implementation is still in its early stages, as the LDM standards only define how information shall be structured in databases, while the mechanism to fuse or link information across different layers is left undefined. A working LDM component, as a real-time database inside the vehicle is an attractive solution to multi-ADAS systems, which may feed a real-time LDM database that serves as a central point of information inside the vehicle, exposing fused and structured information to other components (e.g., decision-making systems). In this paper we describe our approach implementing a real-time LDM component using the RTMaps middleware, as a database deployed in a vehicle, but also at road-side units (RSU), making use of the three pillars that guide a successful fusion strategy: utilisation of standards (with conversions between domains), middlewares to unify multiple ADAS sources, and linkage of data via semantic concepts.
5G Features and Standards for Vehicle Data Exploitation
Apr 13, 2022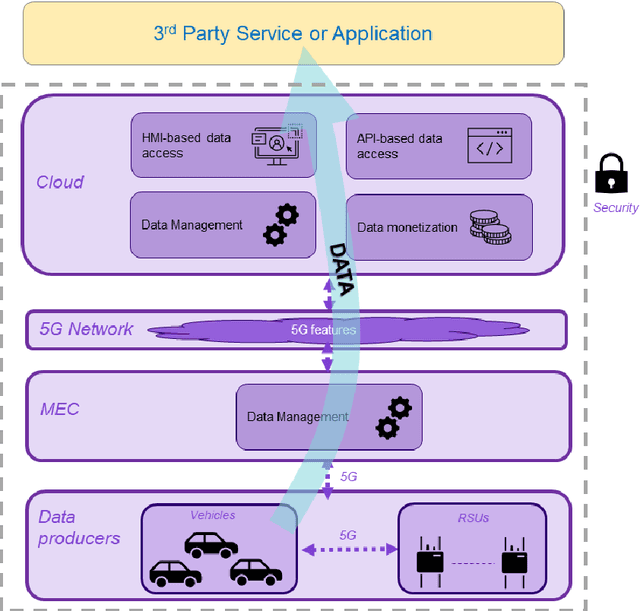



Cars capture and generate huge volumes of data in real-time about the driving dynamics, the environment, and the driver and passengers' activities. Due to the proliferation of cooperative, connected and automated mobility (CCAM), the value of data from vehicles is getting strategic, not just for the automotive industry, but also for many diverse stakeholders including small and medium-sized enterprises (SMEs) and start-ups. 5G can enable car-captured data to feed innovative applications and services deployed in the cloud ensuring lower latency and higher throughput than previous cellular technologies. This paper identifies and discusses the relevance of the main 5G features that can contribute to a scalable, flexible, reliable and secure data pipeline, pointing to the standards and technical reports that specify their implementation.