 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual passengers for real car solutions: synthetic datasets
Paper and Code
May 13, 2022


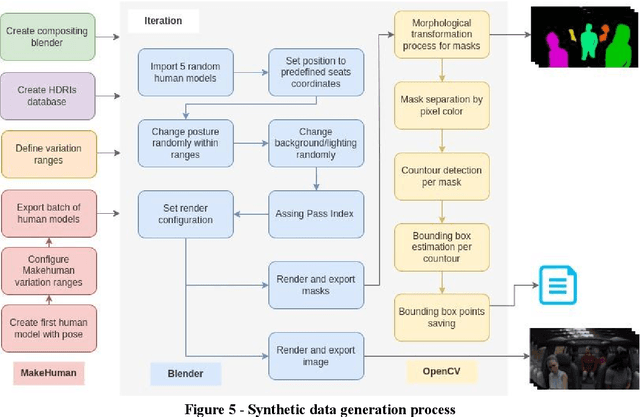
Strategies that include the generation of synthetic data are beginning to be viable as obtaining real data can be logistically complicated, very expensive or slow. Not only the capture of the data can lead to complications, but also its annotation. To achieve high-fidelity data for training intelligent systems, we have built a 3D scenario and set-up to resemble reality as closely as possible. With our approach, it is possible to configure and vary parameters to add randomness to the scene and, in this way, allow variation in data, which is so important in the construction of a dataset. Besides, the annotation task is already included in the data generation exercise, rather than being a post-capture task, which can save a lot of resources. We present the process and concept of synthetic data generation in an automotive context, specifically for driver and passenger monitoring purposes, as an alternative to real data capturing.