 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInferring geometry and material properties from Mueller matrices with machine learning
Aug 27, 2025Mueller matrices (MMs) encode information on geometry and material properties, but recovering both simultaneously is an ill-posed problem. We explore whether MMs contain sufficient information to infer surface geometry and material properties with machine learning. We use a dataset of spheres of various isotropic materials, with MMs captured over the full angular domain at five visible wavelengths (450-650 nm). We train machine learning models to predict material properties and surface normals using only these MMs as input. We demonstrate that, even when the material type is unknown, surface normals can be predicted and object geometry reconstructed. Moreover, MMs allow models to identify material types correctly. Further analyses show that diagonal elements are key for material characterization, and off-diagonal elements are decisive for normal estimation.
Non-Linear Outlier Synthesis for Out-of-Distribution Detection
Nov 20, 2024



The reliability of supervised classifiers is severely hampered by their limitations in dealing with unexpected inputs, leading to great interest in out-of-distribution (OOD) detection. Recently, OOD detectors trained on synthetic outliers, especially those generated by large diffusion models, have shown promising results in defining robust OOD decision boundaries. Building on this progress, we present NCIS, which enhances the quality of synthetic outliers by operating directly in the diffusion's model embedding space rather than combining disjoint models as in previous work and by modeling class-conditional manifolds with a conditional volume-preserving network for more expressive characterization of the training distribution. We demonstrate that these improvements yield new state-of-the-art OOD detection results on standard ImageNet100 and CIFAR100 benchmarks and provide insights into the importance of data pre-processing and other key design choices. We make our code available at \url{https://github.com/LarsDoorenbos/NCIS}.
Targeted Visual Prompting for Medical Visual Question Answering
Aug 06, 2024



With growing interest in recent years, medical visual question answering (Med-VQA) has rapidly evolved, with multimodal large language models (MLLMs) emerging as an alternative to classical model architectures. Specifically, their ability to add visual information to the input of pre-trained LLMs brings new capabilities for image interpretation. However, simple visual errors cast doubt on the actual visual understanding abilities of these models. To address this, region-based questions have been proposed as a means to assess and enhance actual visual understanding through compositional evaluation. To combine these two perspectives, this paper introduces targeted visual prompting to equip MLLMs with region-based questioning capabilities. By presenting the model with both the isolated region and the region in its context in a customized visual prompt, we show the effectiveness of our method across multiple datasets while comparing it to several baseline models. Our code and data are available at https://github.com/sergiotasconmorales/locvqallm.
Learning Non-Linear Invariants for Unsupervised Out-of-Distribution Detection
Jul 04, 2024



The inability of deep learning models to handle data drawn from unseen distributions has sparked much interest in unsupervised out-of-distribution (U-OOD) detection, as it is crucial for reliable deep learning models. Despite considerable attention, theoretically-motivated approaches are few and far between, with most methods building on top of some form of heuristic. Recently, U-OOD was formalized in the context of data invariants, allowing a clearer understanding of how to characterize U-OOD, and methods leveraging affine invariants have attained state-of-the-art results on large-scale benchmarks. Nevertheless, the restriction to affine invariants hinders the expressiveness of the approach. In this work, we broaden the affine invariants formulation to a more general case and propose a framework consisting of a normalizing flow-like architecture capable of learning non-linear invariants. Our novel approach achieves state-of-the-art results on an extensive U-OOD benchmark, and we demonstrate its further applicability to tabular data. Finally, we show our method has the same desirable properties as those based on affine invariants.
Galaxy spectroscopy without spectra: Galaxy properties from photometric images with conditional diffusion models
Jun 26, 2024



Modern spectroscopic surveys can only target a small fraction of the vast amount of photometrically cataloged sources in wide-field surveys. Here, we report the development of a generative AI method capable of predicting optical galaxy spectra from photometric broad-band images alone. This method draws from the latest advances in diffusion models in combination with contrastive networks. We pass multi-band galaxy images into the architecture to obtain optical spectra. From these, robust values for galaxy properties can be derived with any methods in the spectroscopic toolbox, such as standard population synthesis techniques and Lick indices. When trained and tested on 64x64-pixel images from the Sloan Digital Sky Survey, the global bimodality of star-forming and quiescent galaxies in photometric space is recovered, as well as a mass-metallicity relation of star-forming galaxies. The comparison between the observed and the artificially created spectra shows good agreement in overall metallicity, age, Dn4000, stellar velocity dispersion, and E(B-V) values. Photometric redshift estimates of our generative algorithm can compete with other current, specialized deep-learning techniques. Moreover, this work is the first attempt in the literature to infer velocity dispersion from photometric images. Additionally, we can predict the presence of an active galactic nucleus up to an accuracy of 82%. With our method, scientifically interesting galaxy properties, normally requiring spectroscopic inputs, can be obtained in future data sets from large-scale photometric surveys alone. The spectra prediction via AI can further assist in creating realistic mock catalogs.
Continual Unsupervised Out-of-Distribution Detection
Jun 04, 2024



Deep learning models excel when the data distribution during training aligns with testing data. Yet, their performance diminishes when faced with out-of-distribution (OOD) samples, leading to great interest in the field of OOD detection. Current approaches typically assume that OOD samples originate from an unconcentrated distribution complementary to the training distribution. While this assumption is appropriate in the traditional unsupervised OOD (U-OOD) setting, it proves inadequate when considering the place of deployment of the underlying deep learning model. To better reflect this real-world scenario, we introduce the novel setting of continual U-OOD detection. To tackle this new setting, we propose a method that starts from a U-OOD detector, which is agnostic to the OOD distribution, and slowly updates during deployment to account for the actual OOD distribution. Our method uses a new U-OOD scoring function that combines the Mahalanobis distance with a nearest-neighbor approach. Furthermore, we design a confidence-scaled few-shot OOD detector that outperforms previous methods. We show our method greatly improves upon strong baselines from related fields.
Masked Image Modelling for retinal OCT understanding
May 23, 2024



This work explores the effectiveness of masked image modelling for learning representations of retinal OCT images. To this end, we leverage Masked Autoencoders (MAE), a simple and scalable method for self-supervised learning, to obtain a powerful and general representation for OCT images by training on 700K OCT images from 41K patients collected under real world clinical settings. We also provide the first extensive evaluation for a model of OCT on a challenging battery of 6 downstream tasks. Our model achieves strong performance when fully finetuned but can also serve as a versatile frozen feature extractor for many tasks using lightweight adapters. Furthermore, we propose an extension of the MAE pretraining to fuse OCT with an auxiliary modality, namely, IR fundus images and learn a joint model for both. We demonstrate our approach improves performance on a multimodal downstream application. Our experiments utilize most publicly available OCT datasets, thus enabling future comparisons. Our code and model weights are publicly available https://github.com/TheoPis/MIM_OCT.
Hyperbolic Random Forests
Aug 25, 2023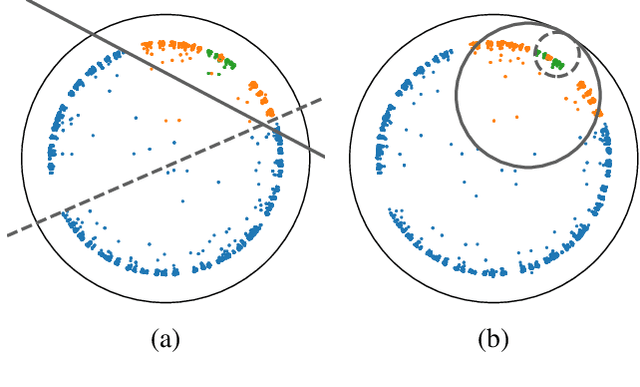
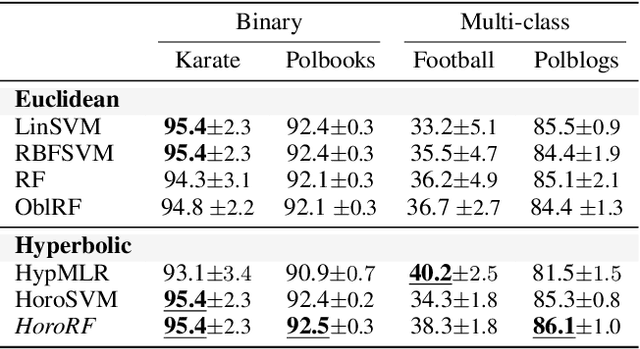
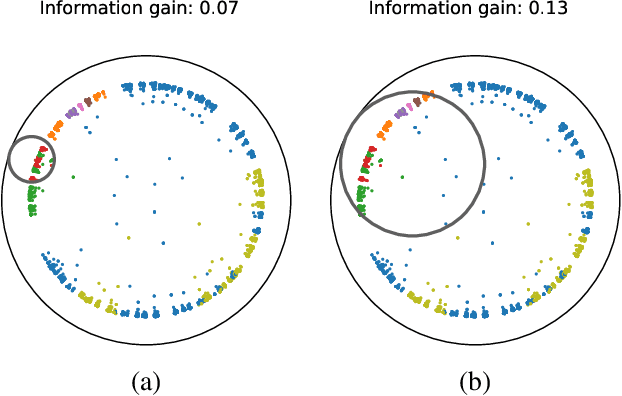
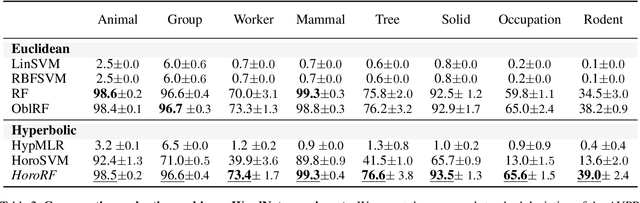
Hyperbolic space is becoming a popular choice for representing data due to the hierarchical structure - whether implicit or explicit - of many real-world datasets. Along with it comes a need for algorithms capable of solving fundamental tasks, such as classification, in hyperbolic space. Recently, multiple papers have investigated hyperbolic alternatives to hyperplane-based classifiers, such as logistic regression and SVMs. While effective, these approaches struggle with more complex hierarchical data. We, therefore, propose to generalize the well-known random forests to hyperbolic space. We do this by redefining the notion of a split using horospheres. Since finding the globally optimal split is computationally intractable, we find candidate horospheres through a large-margin classifier. To make hyperbolic random forests work on multi-class data and imbalanced experiments, we furthermore outline a new method for combining classes based on their lowest common ancestor and a class-balanced version of the large-margin loss. Experiments on standard and new benchmarks show that our approach outperforms both conventional random forest algorithms and recent hyperbolic classifiers.
Localized Questions in Medical Visual Question Answering
Jul 03, 2023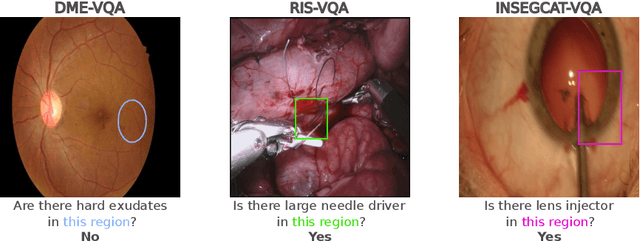
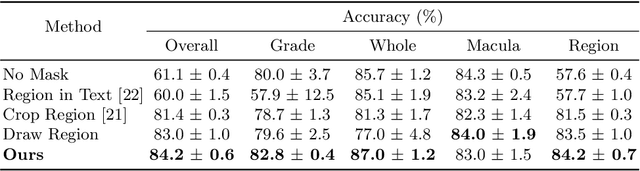
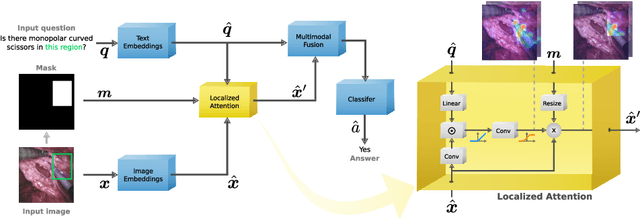
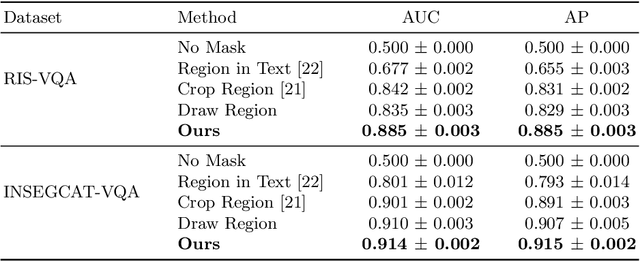
Visual Question Answering (VQA) models aim to answer natural language questions about given images. Due to its ability to ask questions that differ from those used when training the model, medical VQA has received substantial attention in recent years. However, existing medical VQA models typically focus on answering questions that refer to an entire image rather than where the relevant content may be located in the image. Consequently, VQA models are limited in their interpretability power and the possibility to probe the model about specific image regions. This paper proposes a novel approach for medical VQA that addresses this limitation by developing a model that can answer questions about image regions while considering the context necessary to answer the questions. Our experimental results demonstrate the effectiveness of our proposed model, outperforming existing methods on three datasets. Our code and data are available at https://github.com/sergiotasconmorales/locvqa.
Unsupervised out-of-distribution detection for safer robotically guided retinal microsurgery
May 03, 2023Purpose: A fundamental problem in designing safe machine learning systems is identifying when samples presented to a deployed model differ from those observed at training time. Detecting so-called out-of-distribution (OoD) samples is crucial in safety-critical applications such as robotically guided retinal microsurgery, where distances between the instrument and the retina are derived from sequences of 1D images that are acquired by an instrument-integrated optical coherence tomography (iiOCT) probe. Methods: This work investigates the feasibility of using an OoD detector to identify when images from the iiOCT probe are inappropriate for subsequent machine learning-based distance estimation. We show how a simple OoD detector based on the Mahalanobis distance can successfully reject corrupted samples coming from real-world ex vivo porcine eyes. Results: Our results demonstrate that the proposed approach can successfully detect OoD samples and help maintain the performance of the downstream task within reasonable levels. MahaAD outperformed a supervised approach trained on the same kind of corruptions and achieved the best performance in detecting OoD cases from a collection of iiOCT samples with real-world corruptions. Conclusion: The results indicate that detecting corrupted iiOCT data through OoD detection is feasible and does not need prior knowledge of possible corruptions. Consequently, MahaAD could aid in ensuring patient safety during robotically guided microsurgery by preventing deployed prediction models from estimating distances that put the patient at risk.