 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Robotic Friction Learning via Symbolic Regression
May 19, 2025Accurately modeling the friction torque in robotic joints has long been challenging due to the request for a robust mathematical description. Traditional model-based approaches are often labor-intensive, requiring extensive experiments and expert knowledge, and they are difficult to adapt to new scenarios and dependencies. On the other hand, data-driven methods based on neural networks are easier to implement but often lack robustness, interpretability, and trustworthiness--key considerations for robotic hardware and safety-critical applications such as human-robot interaction. To address the limitations of both approaches, we propose the use of symbolic regression (SR) to estimate the friction torque. SR generates interpretable symbolic formulas similar to those produced by model-based methods while being flexible to accommodate various dynamic effects and dependencies. In this work, we apply SR algorithms to approximate the friction torque using collected data from a KUKA LWR-IV+ robot. Our results show that SR not only yields formulas with comparable complexity to model-based approaches but also achieves higher accuracy. Moreover, SR-derived formulas can be seamlessly extended to include load dependencies and other dynamic factors.
SAM-DA: Decoder Adapter for Efficient Medical Domain Adaptation
Jan 12, 2025



This paper addresses the domain adaptation challenge for semantic segmentation in medical imaging. Despite the impressive performance of recent foundational segmentation models like SAM on natural images, they struggle with medical domain images. Beyond this, recent approaches that perform end-to-end fine-tuning of models are simply not computationally tractable. To address this, we propose a novel SAM adapter approach that minimizes the number of trainable parameters while achieving comparable performances to full fine-tuning. The proposed SAM adapter is strategically placed in the mask decoder, offering excellent and broad generalization capabilities and improved segmentation across both fully supervised and test-time domain adaptation tasks. Extensive validation on four datasets showcases the adapter's efficacy, outperforming existing methods while training less than 1% of SAM's total parameters.
Masked Image Modelling for retinal OCT understanding
May 23, 2024



This work explores the effectiveness of masked image modelling for learning representations of retinal OCT images. To this end, we leverage Masked Autoencoders (MAE), a simple and scalable method for self-supervised learning, to obtain a powerful and general representation for OCT images by training on 700K OCT images from 41K patients collected under real world clinical settings. We also provide the first extensive evaluation for a model of OCT on a challenging battery of 6 downstream tasks. Our model achieves strong performance when fully finetuned but can also serve as a versatile frozen feature extractor for many tasks using lightweight adapters. Furthermore, we propose an extension of the MAE pretraining to fuse OCT with an auxiliary modality, namely, IR fundus images and learn a joint model for both. We demonstrate our approach improves performance on a multimodal downstream application. Our experiments utilize most publicly available OCT datasets, thus enabling future comparisons. Our code and model weights are publicly available https://github.com/TheoPis/MIM_OCT.
Cataract-1K: Cataract Surgery Dataset for Scene Segmentation, Phase Recognition, and Irregularity Detection
Dec 11, 2023In recent years, the landscape of computer-assisted interventions and post-operative surgical video analysis has been dramatically reshaped by deep-learning techniques, resulting in significant advancements in surgeons' skills, operation room management, and overall surgical outcomes. However, the progression of deep-learning-powered surgical technologies is profoundly reliant on large-scale datasets and annotations. Particularly, surgical scene understanding and phase recognition stand as pivotal pillars within the realm of computer-assisted surgery and post-operative assessment of cataract surgery videos. In this context, we present the largest cataract surgery video dataset that addresses diverse requisites for constructing computerized surgical workflow analysis and detecting post-operative irregularities in cataract surgery. We validate the quality of annotations by benchmarking the performance of several state-of-the-art neural network architectures for phase recognition and surgical scene segmentation. Besides, we initiate the research on domain adaptation for instrument segmentation in cataract surgery by evaluating cross-domain instrument segmentation performance in cataract surgery videos. The dataset and annotations will be publicly available upon acceptance of the paper.
DeepPyramid+: Medical Image Segmentation using Pyramid View Fusion and Deformable Pyramid Reception
Dec 06, 2023Semantic Segmentation plays a pivotal role in many applications related to medical image and video analysis. However, designing a neural network architecture for medical image and surgical video segmentation is challenging due to the diverse features of relevant classes, including heterogeneity, deformability, transparency, blunt boundaries, and various distortions. We propose a network architecture, DeepPyramid+, which addresses diverse challenges encountered in medical image and surgical video segmentation. The proposed DeepPyramid+ incorporates two major modules, namely "Pyramid View Fusion" (PVF) and "Deformable Pyramid Reception," (DPR), to address the outlined challenges. PVF replicates a deduction process within the neural network, aligning with the human visual system, thereby enhancing the representation of relative information at each pixel position. Complementarily, DPR introduces shape- and scale-adaptive feature extraction techniques using dilated deformable convolutions, enhancing accuracy and robustness in handling heterogeneous classes and deformable shapes. Extensive experiments conducted on diverse datasets, including endometriosis videos, MRI images, OCT scans, and cataract and laparoscopy videos, demonstrate the effectiveness of DeepPyramid+ in handling various challenges such as shape and scale variation, reflection, and blur degradation. DeepPyramid+ demonstrates significant improvements in segmentation performance, achieving up to a 3.65% increase in Dice coefficient for intra-domain segmentation and up to a 17% increase in Dice coefficient for cross-domain segmentation. DeepPyramid+ consistently outperforms state-of-the-art networks across diverse modalities considering different backbone networks, showcasing its versatility.
Learning-based adaption of robotic friction models
Oct 25, 2023
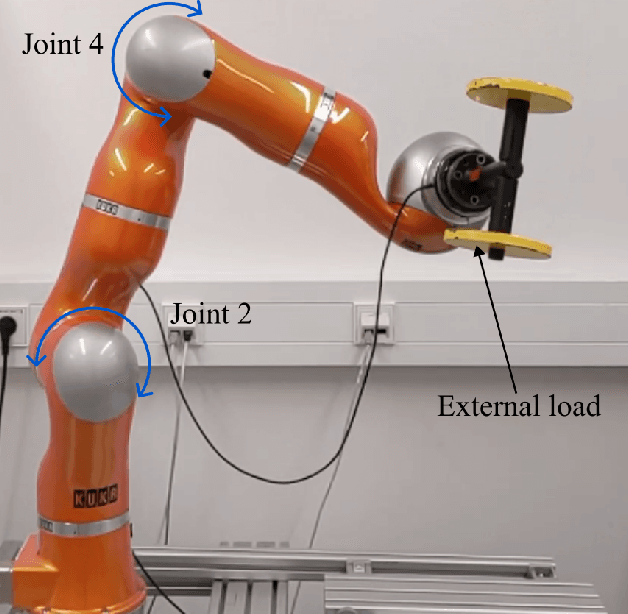
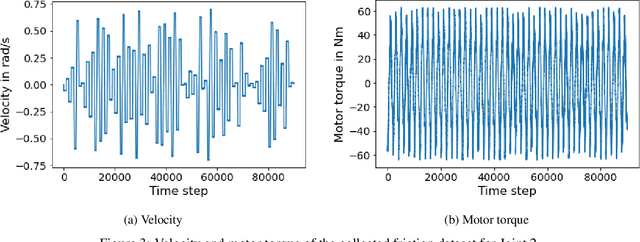
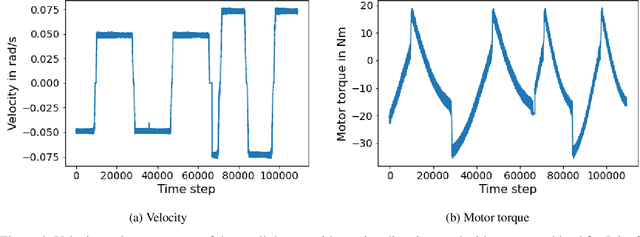
In the Fourth Industrial Revolution, wherein artificial intelligence and the automation of machines occupy a central role, the deployment of robots is indispensable. However, the manufacturing process using robots, especially in collaboration with humans, is highly intricate. In particular, modeling the friction torque in robotic joints is a longstanding problem due to the lack of a good mathematical description. This motivates the usage of data-driven methods in recent works. However, model-based and data-driven models often exhibit limitations in their ability to generalize beyond the specific dynamics they were trained on, as we demonstrate in this paper. To address this challenge, we introduce a novel approach based on residual learning, which aims to adapt an existing friction model to new dynamics using as little data as possible. We validate our approach by training a base neural network on a symmetric friction data set to learn an accurate relation between the velocity and the friction torque. Subsequently, to adapt to more complex asymmetric settings, we train a second network on a small dataset, focusing on predicting the residual of the initial network's output. By combining the output of both networks in a suitable manner, our proposed estimator outperforms the conventional model-based approach and the base neural network significantly. Furthermore, we evaluate our method on trajectories involving external loads and still observe a substantial improvement, approximately 60-70\%, over the conventional approach. Our method does not rely on data with external load during training, eliminating the need for external torque sensors. This demonstrates the generalization capability of our approach, even with a small amount of data-only 43 seconds of a robot movement-enabling adaptation to diverse scenarios based on prior knowledge about friction in different settings.
Domain Adaptation for Medical Image Segmentation using Transformation-Invariant Self-Training
Jul 31, 2023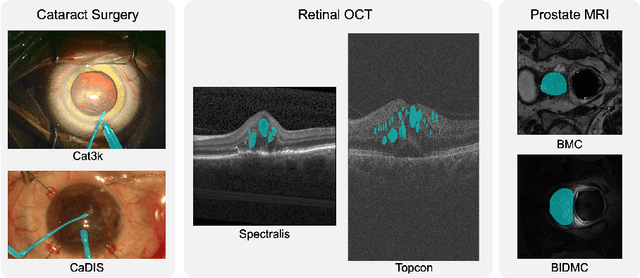

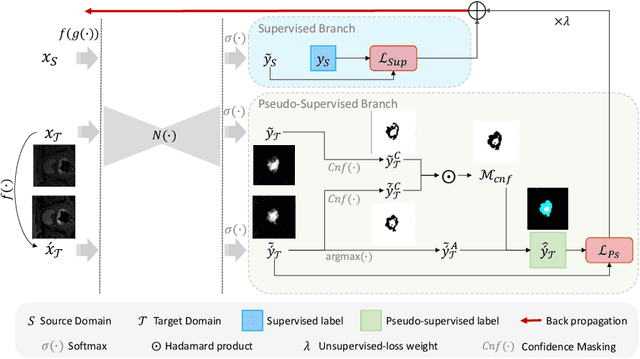

Models capable of leveraging unlabelled data are crucial in overcoming large distribution gaps between the acquired datasets across different imaging devices and configurations. In this regard, self-training techniques based on pseudo-labeling have been shown to be highly effective for semi-supervised domain adaptation. However, the unreliability of pseudo labels can hinder the capability of self-training techniques to induce abstract representation from the unlabeled target dataset, especially in the case of large distribution gaps. Since the neural network performance should be invariant to image transformations, we look to this fact to identify uncertain pseudo labels. Indeed, we argue that transformation invariant detections can provide more reasonable approximations of ground truth. Accordingly, we propose a semi-supervised learning strategy for domain adaptation termed transformation-invariant self-training (TI-ST). The proposed method assesses pixel-wise pseudo-labels' reliability and filters out unreliable detections during self-training. We perform comprehensive evaluations for domain adaptation using three different modalities of medical images, two different network architectures, and several alternative state-of-the-art domain adaptation methods. Experimental results confirm the superiority of our proposed method in mitigating the lack of target domain annotation and boosting segmentation performance in the target domain.
Full or Weak annotations? An adaptive strategy for budget-constrained annotation campaigns
Mar 21, 2023

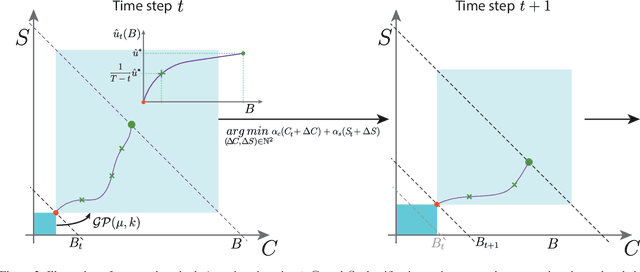

Annotating new datasets for machine learning tasks is tedious, time-consuming, and costly. For segmentation applications, the burden is particularly high as manual delineations of relevant image content are often extremely expensive or can only be done by experts with domain-specific knowledge. Thanks to developments in transfer learning and training with weak supervision, segmentation models can now also greatly benefit from annotations of different kinds. However, for any new domain application looking to use weak supervision, the dataset builder still needs to define a strategy to distribute full segmentation and other weak annotations. Doing so is challenging, however, as it is a priori unknown how to distribute an annotation budget for a given new dataset. To this end, we propose a novel approach to determine annotation strategies for segmentation datasets, whereby estimating what proportion of segmentation and classification annotations should be collected given a fixed budget. To do so, our method sequentially determines proportions of segmentation and classification annotations to collect for budget-fractions by modeling the expected improvement of the final segmentation model. We show in our experiments that our approach yields annotations that perform very close to the optimal for a number of different annotation budgets and datasets.
CataNet: Predicting remaining cataract surgery duration
Jun 21, 2021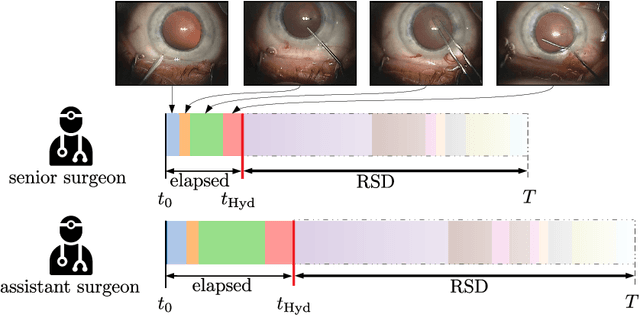
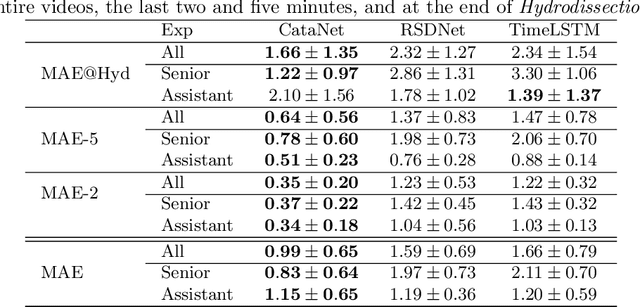
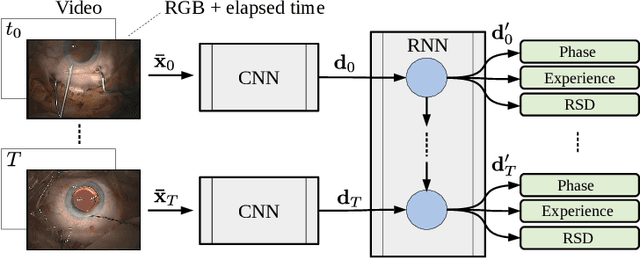

Cataract surgery is a sight saving surgery that is performed over 10 million times each year around the world. With such a large demand, the ability to organize surgical wards and operating rooms efficiently is critical to delivery this therapy in routine clinical care. In this context, estimating the remaining surgical duration (RSD) during procedures is one way to help streamline patient throughput and workflows. To this end, we propose CataNet, a method for cataract surgeries that predicts in real time the RSD jointly with two influential elements: the surgeon's experience, and the current phase of the surgery. We compare CataNet to state-of-the-art RSD estimation methods, showing that it outperforms them even when phase and experience are not considered. We investigate this improvement and show that a significant contributor is the way we integrate the elapsed time into CataNet's feature extractor.
Fused Detection of Retinal Biomarkers in OCT Volumes
Jul 16, 2019
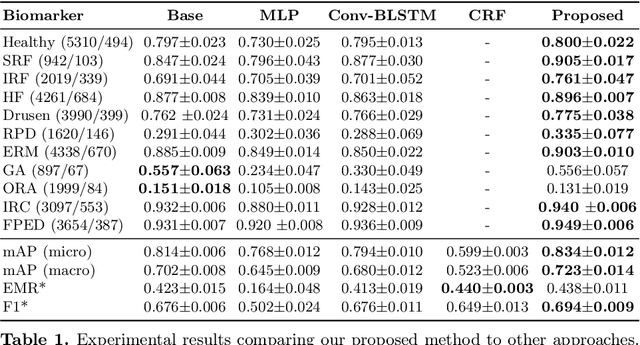


Optical Coherence Tomography (OCT) is the primary imaging modality for detecting pathological biomarkers associated to retinal diseases such as Age-Related Macular Degeneration. In practice, clinical diagnosis and treatment strategies are closely linked to biomarkers visible in OCT volumes and the ability to identify these plays an important role in the development of ophthalmic pharmaceutical products. In this context, we present a method that automatically predicts the presence of biomarkers in OCT cross-sections by incorporating information from the entire volume. We do so by adding a bidirectional LSTM to fuse the outputs of a Convolutional Neural Network that predicts individual biomarkers. We thus avoid the need to use pixel-wise annotations to train our method, and instead provide fine-grained biomarker information regardless. On a dataset of 416 volumes, we show that our approach imposes coherence between biomarker predictions across volume slices and our predictions are superior to several existing approaches.