 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymbolic recovery of PDEs from measurement data
Feb 17, 2026Models based on partial differential equations (PDEs) are powerful for describing a wide range of complex relationships in the natural sciences. Accurately identifying the PDE model, which represents the underlying physical law, is essential for a proper understanding of the problem. This reconstruction typically relies on indirect and noisy measurements of the system's state and, without specifically tailored methods, rarely yields symbolic expressions, thereby hindering interpretability. In this work, we address this issue by considering existing neural network architectures based on rational functions for the symbolic representation of physical laws. These networks leverage the approximation power of rational functions while also benefiting from their flexibility in representing arithmetic operations. Our main contribution is an identifiability result, showing that, in the limit of noiseless, complete measurements, such symbolic networks can uniquely reconstruct the simplest physical law within the PDE model. Specifically, reconstructed laws remain expressible within the symbolic network architecture, with regularization-minimizing parameterizations promoting interpretability and sparsity in case of $L^1$-regularization. In addition, we provide regularity results for symbolic networks. Empirical validation using the ParFam architecture supports these theoretical findings, providing evidence for the practical reconstructibility of physical laws.
When is a System Discoverable from Data? Discovery Requires Chaos
Nov 12, 2025The deep learning revolution has spurred a rise in advances of using AI in sciences. Within physical sciences the main focus has been on discovery of dynamical systems from observational data. Yet the reliability of learned surrogates and symbolic models is often undermined by the fundamental problem of non-uniqueness. The resulting models may fit the available data perfectly, but lack genuine predictive power. This raises the question: under what conditions can the systems governing equations be uniquely identified from a finite set of observations? We show, counter-intuitively, that chaos, typically associated with unpredictability, is crucial for ensuring a system is discoverable in the space of continuous or analytic functions. The prevalence of chaotic systems in benchmark datasets may have inadvertently obscured this fundamental limitation. More concretely, we show that systems chaotic on their entire domain are discoverable from a single trajectory within the space of continuous functions, and systems chaotic on a strange attractor are analytically discoverable under a geometric condition on the attractor. As a consequence, we demonstrate for the first time that the classical Lorenz system is analytically discoverable. Moreover, we establish that analytic discoverability is impossible in the presence of first integrals, common in real-world systems. These findings help explain the success of data-driven methods in inherently chaotic domains like weather forecasting, while revealing a significant challenge for engineering applications like digital twins, where stable, predictable behavior is desired. For these non-chaotic systems, we find that while trajectory data alone is insufficient, certain prior physical knowledge can help ensure discoverability. These findings warrant a critical re-evaluation of the fundamental assumptions underpinning purely data-driven discovery.
Improved probabilistic regression using diffusion models
Oct 06, 2025Probabilistic regression models the entire predictive distribution of a response variable, offering richer insights than classical point estimates and directly allowing for uncertainty quantification. While diffusion-based generative models have shown remarkable success in generating complex, high-dimensional data, their usage in general regression tasks often lacks uncertainty-related evaluation and remains limited to domain-specific applications. We propose a novel diffusion-based framework for probabilistic regression that learns predictive distributions in a nonparametric way. More specifically, we propose to model the full distribution of the diffusion noise, enabling adaptation to diverse tasks and enhanced uncertainty quantification. We investigate different noise parameterizations, analyze their trade-offs, and evaluate our framework across a broad range of regression tasks, covering low- and high-dimensional settings. For several experiments, our approach shows superior performance against existing baselines, while delivering calibrated uncertainty estimates, demonstrating its versatility as a tool for probabilistic prediction.
Interpretable Robotic Friction Learning via Symbolic Regression
May 19, 2025Accurately modeling the friction torque in robotic joints has long been challenging due to the request for a robust mathematical description. Traditional model-based approaches are often labor-intensive, requiring extensive experiments and expert knowledge, and they are difficult to adapt to new scenarios and dependencies. On the other hand, data-driven methods based on neural networks are easier to implement but often lack robustness, interpretability, and trustworthiness--key considerations for robotic hardware and safety-critical applications such as human-robot interaction. To address the limitations of both approaches, we propose the use of symbolic regression (SR) to estimate the friction torque. SR generates interpretable symbolic formulas similar to those produced by model-based methods while being flexible to accommodate various dynamic effects and dependencies. In this work, we apply SR algorithms to approximate the friction torque using collected data from a KUKA LWR-IV+ robot. Our results show that SR not only yields formulas with comparable complexity to model-based approaches but also achieves higher accuracy. Moreover, SR-derived formulas can be seamlessly extended to include load dependencies and other dynamic factors.
Graph Neural Networks for Enhancing Ensemble Forecasts of Extreme Rainfall
Apr 07, 2025Climate change is increasing the occurrence of extreme precipitation events, threatening infrastructure, agriculture, and public safety. Ensemble prediction systems provide probabilistic forecasts but exhibit biases and difficulties in capturing extreme weather. While post-processing techniques aim to enhance forecast accuracy, they rarely focus on precipitation, which exhibits complex spatial dependencies and tail behavior. Our novel framework leverages graph neural networks to post-process ensemble forecasts, specifically modeling the extremes of the underlying distribution. This allows to capture spatial dependencies and improves forecast accuracy for extreme events, thus leading to more reliable forecasts and mitigating risks of extreme precipitation and flooding.
Probabilistic neural operators for functional uncertainty quantification
Feb 18, 2025Neural operators aim to approximate the solution operator of a system of differential equations purely from data. They have shown immense success in modeling complex dynamical systems across various domains. However, the occurrence of uncertainties inherent in both model and data has so far rarely been taken into account\textemdash{}a critical limitation in complex, chaotic systems such as weather forecasting. In this paper, we introduce the probabilistic neural operator (PNO), a framework for learning probability distributions over the output function space of neural operators. PNO extends neural operators with generative modeling based on strictly proper scoring rules, integrating uncertainty information directly into the training process. We provide a theoretical justification for the approach and demonstrate improved performance in quantifying uncertainty across different domains and with respect to different baselines. Furthermore, PNO requires minimal adjustment to existing architectures, shows improved performance for most probabilistic prediction tasks, and leads to well-calibrated predictive distributions and adequate uncertainty representations even for long dynamical trajectories. Implementing our approach into large-scale models for physical applications can lead to improvements in corresponding uncertainty quantification and extreme event identification, ultimately leading to a deeper understanding of the prediction of such surrogate models.
Robust identifiability for symbolic recovery of differential equations
Oct 13, 2024
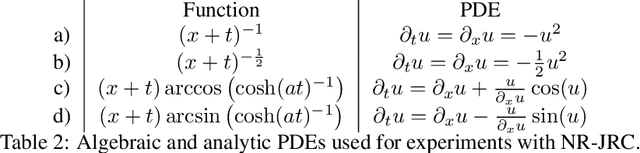

Recent advancements in machine learning have transformed the discovery of physical laws, moving from manual derivation to data-driven methods that simultaneously learn both the structure and parameters of governing equations. This shift introduces new challenges regarding the validity of the discovered equations, particularly concerning their uniqueness and, hence, identifiability. While the issue of non-uniqueness has been well-studied in the context of parameter estimation, it remains underexplored for algorithms that recover both structure and parameters simultaneously. Early studies have primarily focused on idealized scenarios with perfect, noise-free data. In contrast, this paper investigates how noise influences the uniqueness and identifiability of physical laws governed by partial differential equations (PDEs). We develop a comprehensive mathematical framework to analyze the uniqueness of PDEs in the presence of noise and introduce new algorithms that account for noise, providing thresholds to assess uniqueness and identifying situations where excessive noise hinders reliable conclusions. Numerical experiments demonstrate the effectiveness of these algorithms in detecting uniqueness despite the presence of noise.
Learning-based adaption of robotic friction models
Oct 25, 2023
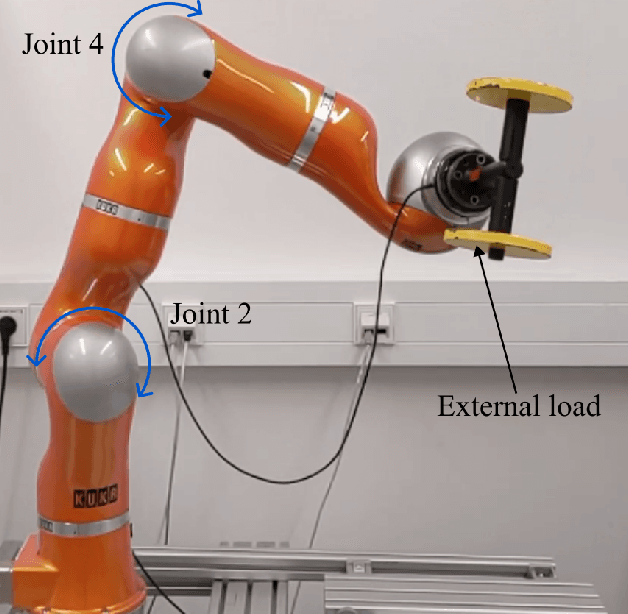
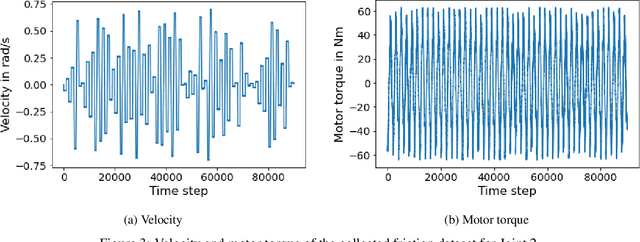
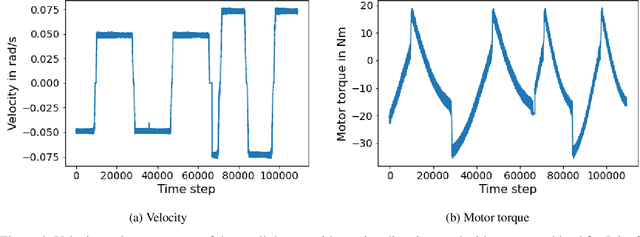
In the Fourth Industrial Revolution, wherein artificial intelligence and the automation of machines occupy a central role, the deployment of robots is indispensable. However, the manufacturing process using robots, especially in collaboration with humans, is highly intricate. In particular, modeling the friction torque in robotic joints is a longstanding problem due to the lack of a good mathematical description. This motivates the usage of data-driven methods in recent works. However, model-based and data-driven models often exhibit limitations in their ability to generalize beyond the specific dynamics they were trained on, as we demonstrate in this paper. To address this challenge, we introduce a novel approach based on residual learning, which aims to adapt an existing friction model to new dynamics using as little data as possible. We validate our approach by training a base neural network on a symmetric friction data set to learn an accurate relation between the velocity and the friction torque. Subsequently, to adapt to more complex asymmetric settings, we train a second network on a small dataset, focusing on predicting the residual of the initial network's output. By combining the output of both networks in a suitable manner, our proposed estimator outperforms the conventional model-based approach and the base neural network significantly. Furthermore, we evaluate our method on trajectories involving external loads and still observe a substantial improvement, approximately 60-70\%, over the conventional approach. Our method does not rely on data with external load during training, eliminating the need for external torque sensors. This demonstrates the generalization capability of our approach, even with a small amount of data-only 43 seconds of a robot movement-enabling adaptation to diverse scenarios based on prior knowledge about friction in different settings.
ParFam -- Symbolic Regression Based on Continuous Global Optimization
Oct 10, 2023



The problem of symbolic regression (SR) arises in many different applications, such as identifying physical laws or deriving mathematical equations describing the behavior of financial markets from given data. Various methods exist to address the problem of SR, often based on genetic programming. However, these methods are usually quite complicated and require a lot of hyperparameter tuning and computational resources. In this paper, we present our new method ParFam that utilizes parametric families of suitable symbolic functions to translate the discrete symbolic regression problem into a continuous one, resulting in a more straightforward setup compared to current state-of-the-art methods. In combination with a powerful global optimizer, this approach results in an effective method to tackle the problem of SR. Furthermore, it can be easily extended to more advanced algorithms, e.g., by adding a deep neural network to find good-fitting parametric families. We prove the performance of ParFam with extensive numerical experiments based on the common SR benchmark suit SRBench, showing that we achieve state-of-the-art results. Our code and results can be found at https://github.com/Philipp238/parfam .
Well-definedness of Physical Law Learning: The Uniqueness Problem
Oct 19, 2022
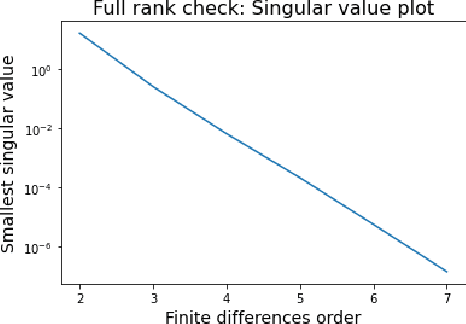
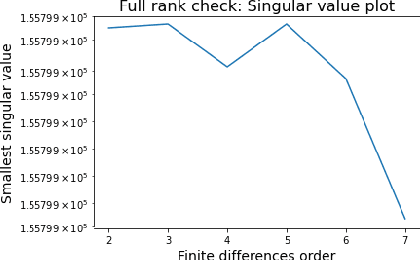
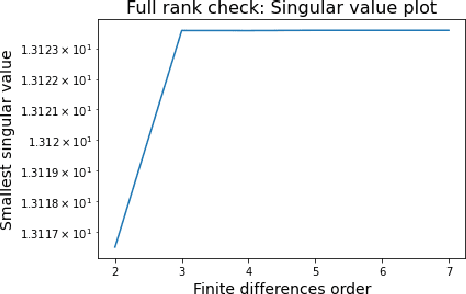
Physical law learning is the ambiguous attempt at automating the derivation of governing equations with the use of machine learning techniques. The current literature focuses however solely on the development of methods to achieve this goal, and a theoretical foundation is at present missing. This paper shall thus serve as a first step to build a comprehensive theoretical framework for learning physical laws, aiming to provide reliability to according algorithms. One key problem consists in the fact that the governing equations might not be uniquely determined by the given data. We will study this problem in the common situation of having a physical law be described by an ordinary or partial differential equation. For various different classes of differential equations, we provide both necessary and sufficient conditions for a function from a given function class to uniquely determine the differential equation which is governing the phenomenon. We then use our results to devise numerical algorithms to determine whether a function solves a differential equation uniquely. Finally, we provide extensive numerical experiments showing that our algorithms in combination with common approaches for learning physical laws indeed allow to guarantee that a unique governing differential equation is learnt, without assuming any knowledge about the function, thereby ensuring reliability.