 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural-ANOVA: Model Decomposition for Interpretable Machine Learning
Aug 22, 2024
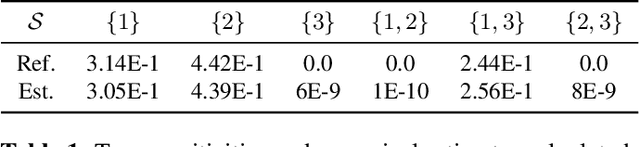
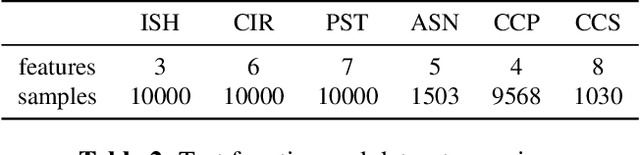
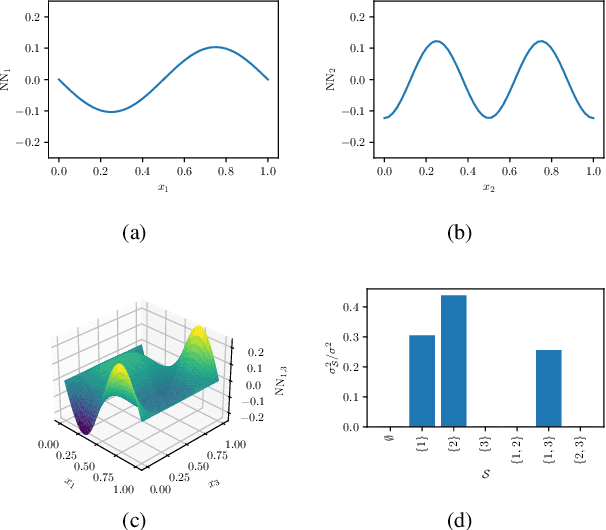
The analysis of variance (ANOVA) decomposition offers a systematic method to understand the interaction effects that contribute to a specific decision output. In this paper we introduce Neural-ANOVA, an approach to decompose neural networks into glassbox models using the ANOVA decomposition. Our approach formulates a learning problem, which enables rapid and closed-form evaluation of integrals over subspaces that appear in the calculation of the ANOVA decomposition. Finally, we conduct numerical experiments to illustrate the advantages of enhanced interpretability and model validation by a decomposition of the learned interaction effects.
Safe Policy Improvement Approaches and their Limitations
Aug 01, 2022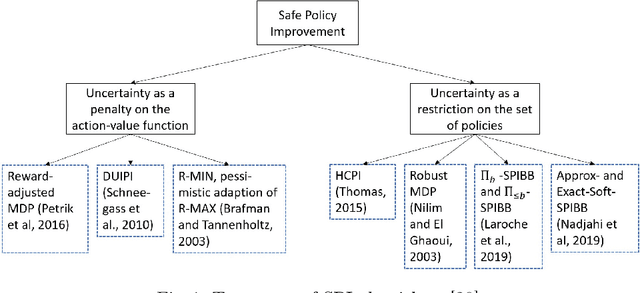

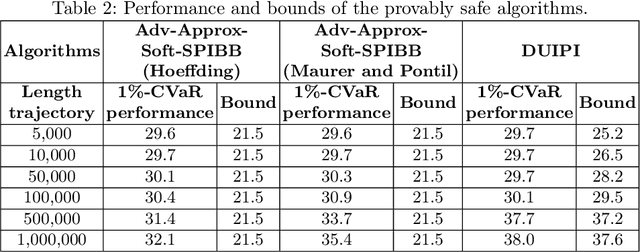
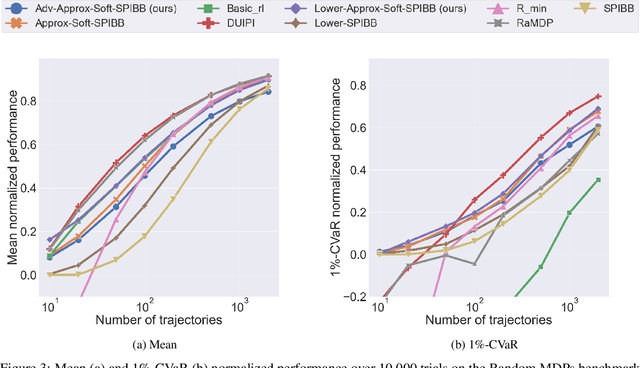
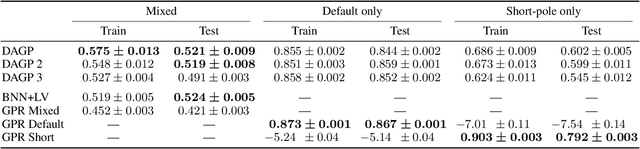
Safe Policy Improvement (SPI) is an important technique for offline reinforcement learning in safety critical applications as it improves the behavior policy with a high probability. We classify various SPI approaches from the literature into two groups, based on how they utilize the uncertainty of state-action pairs. Focusing on the Soft-SPIBB (Safe Policy Improvement with Soft Baseline Bootstrapping) algorithms, we show that their claim of being provably safe does not hold. Based on this finding, we develop adaptations, the Adv-Soft-SPIBB algorithms, and show that they are provably safe. A heuristic adaptation, Lower-Approx-Soft-SPIBB, yields the best performance among all SPIBB algorithms in extensive experiments on two benchmarks. We also check the safety guarantees of the provably safe algorithms and show that huge amounts of data are necessary such that the safety bounds become useful in practice.
Safe Policy Improvement Approaches on Discrete Markov Decision Processes
Jan 28, 2022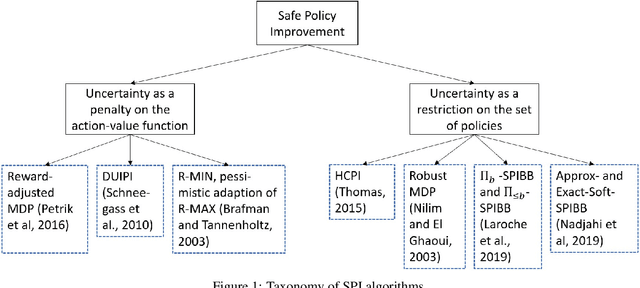


Safe Policy Improvement (SPI) aims at provable guarantees that a learned policy is at least approximately as good as a given baseline policy. Building on SPI with Soft Baseline Bootstrapping (Soft-SPIBB) by Nadjahi et al., we identify theoretical issues in their approach, provide a corrected theory, and derive a new algorithm that is provably safe on finite Markov Decision Processes (MDP). Additionally, we provide a heuristic algorithm that exhibits the best performance among many state of the art SPI algorithms on two different benchmarks. Furthermore, we introduce a taxonomy of SPI algorithms and empirically show an interesting property of two classes of SPI algorithms: while the mean performance of algorithms that incorporate the uncertainty as a penalty on the action-value is higher, actively restricting the set of policies more consistently produces good policies and is, thus, safer.
Interpretable Dynamics Models for Data-Efficient Reinforcement Learning
Jul 10, 2019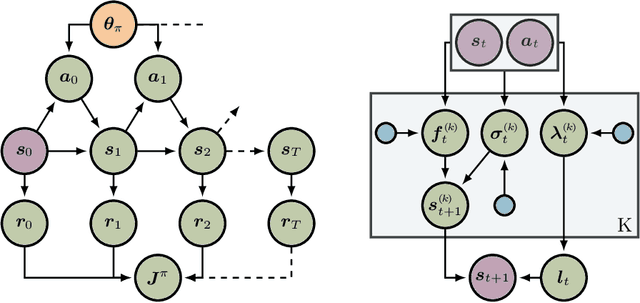
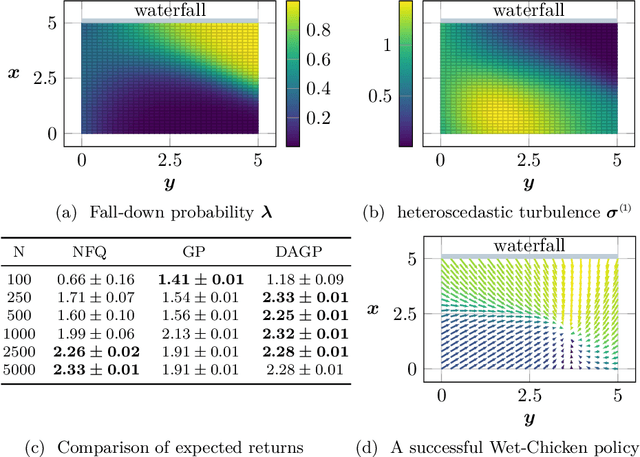
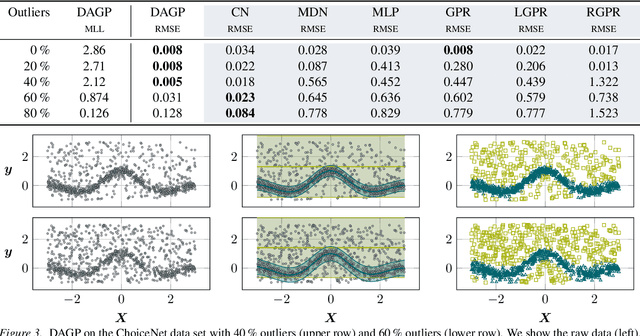
In this paper, we present a Bayesian view on model-based reinforcement learning. We use expert knowledge to impose structure on the transition model and present an efficient learning scheme based on variational inference. This scheme is applied to a heteroskedastic and bimodal benchmark problem on which we compare our results to NFQ and show how our approach yields human-interpretable insight about the underlying dynamics while also increasing data-efficiency.
Multimodal Deep Gaussian Processes
Oct 16, 2018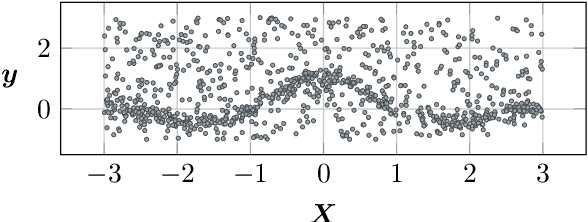
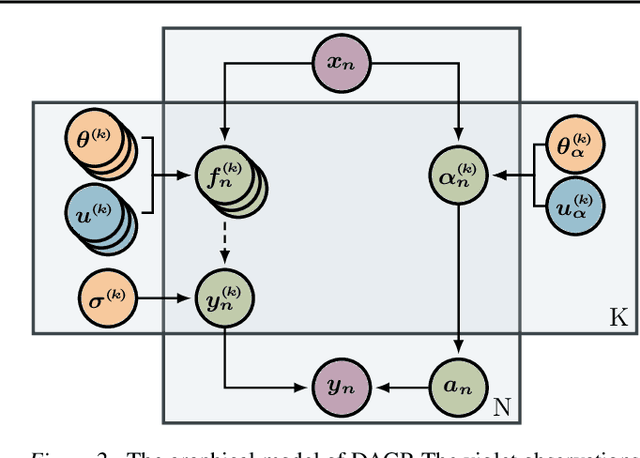
We propose a novel Bayesian approach to modelling multimodal data generated by multiple independent processes, simultaneously solving the data association and induced supervised learning problems. Underpinning our approach is the use of Gaussian process priors which encode structure both on the functions and the associations themselves. The association of samples and functions are determined by taking both inputs and outputs into account while also obtaining a posterior belief about the relevance of the global components throughout the input space. We present an efficient learning scheme based on doubly stochastic variational inference and discuss how it can be applied to deep Gaussian process priors. We show results for an artificial data set, a noise separation problem, and a multimodal regression problem based on the cart-pole benchmark.
Bayesian Alignments of Warped Multi-Output Gaussian Processes
May 23, 2018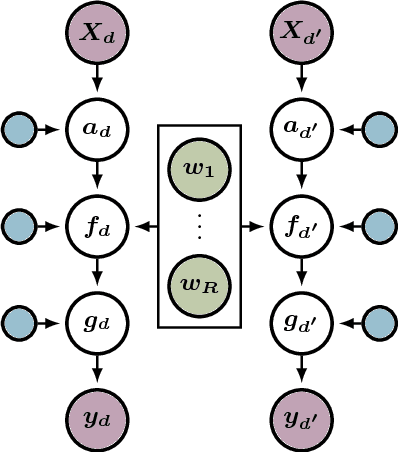
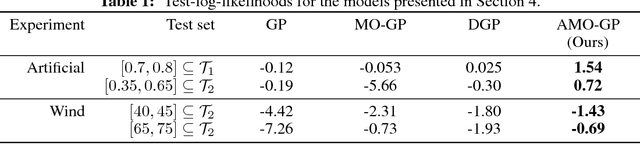
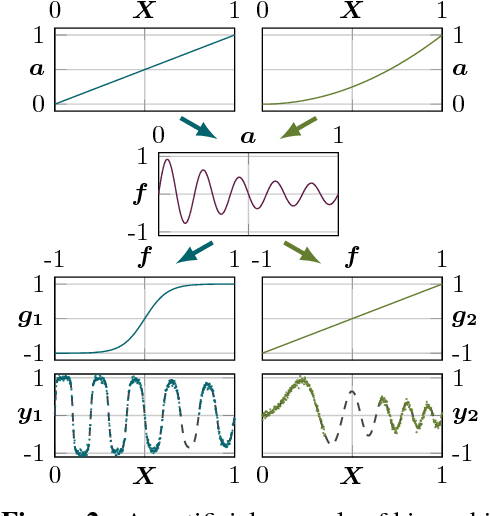
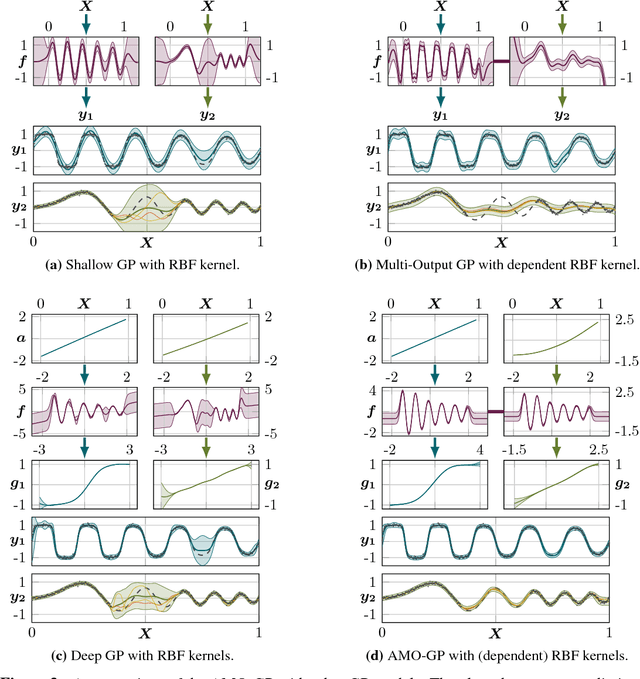
We propose a novel Bayesian approach to modelling nonlinear alignments of time series based on latent shared information. We apply the method to the real-world problem of finding common structure in the sensor data of wind turbines introduced by the underlying latent and turbulent wind field. The proposed model allows for both arbitrary alignments of the inputs and non-parametric output warpings to transform the observations. This gives rise to multiple deep Gaussian process models connected via latent generating processes. We present an efficient variational approximation based on nested variational compression and show how the model can be used to extract shared information between dependent time series, recovering an interpretable functional decomposition of the learning problem. We show results for an artificial data set and real-world data of two wind turbines.