 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Policy Improvement Approaches on Discrete Markov Decision Processes
Paper and Code
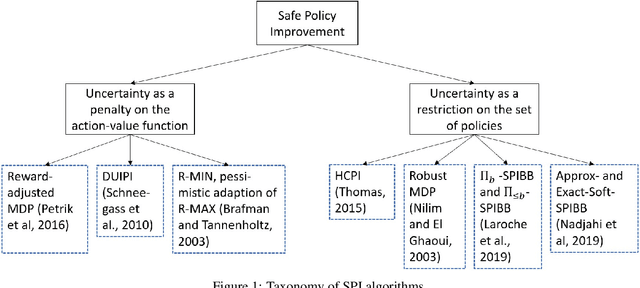


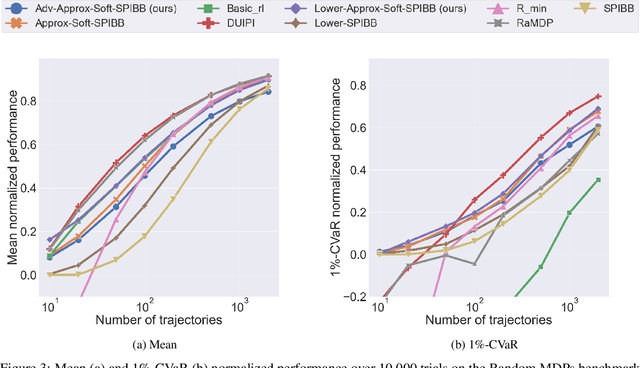
Safe Policy Improvement (SPI) aims at provable guarantees that a learned policy is at least approximately as good as a given baseline policy. Building on SPI with Soft Baseline Bootstrapping (Soft-SPIBB) by Nadjahi et al., we identify theoretical issues in their approach, provide a corrected theory, and derive a new algorithm that is provably safe on finite Markov Decision Processes (MDP). Additionally, we provide a heuristic algorithm that exhibits the best performance among many state of the art SPI algorithms on two different benchmarks. Furthermore, we introduce a taxonomy of SPI algorithms and empirically show an interesting property of two classes of SPI algorithms: while the mean performance of algorithms that incorporate the uncertainty as a penalty on the action-value is higher, actively restricting the set of policies more consistently produces good policies and is, thus, safer.