 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline 3D reconstruction and dense tracking in endoscopic videos
Sep 09, 2024



3D scene reconstruction from stereo endoscopic video data is crucial for advancing surgical interventions. In this work, we present an online framework for online, dense 3D scene reconstruction and tracking, aimed at enhancing surgical scene understanding and assisting interventions. Our method dynamically extends a canonical scene representation using Gaussian splatting, while modeling tissue deformations through a sparse set of control points. We introduce an efficient online fitting algorithm that optimizes the scene parameters, enabling consistent tracking and accurate reconstruction. Through experiments on the StereoMIS dataset, we demonstrate the effectiveness of our approach, outperforming state-of-the-art tracking methods and achieving comparable performance to offline reconstruction techniques. Our work enables various downstream applications thus contributing to advancing the capabilities of surgical assistance systems.
Learning How To Robustly Estimate Camera Pose in Endoscopic Videos
Apr 17, 2023Purpose: Surgical scene understanding plays a critical role in the technology stack of tomorrow's intervention-assisting systems in endoscopic surgeries. For this, tracking the endoscope pose is a key component, but remains challenging due to illumination conditions, deforming tissues and the breathing motion of organs. Method: We propose a solution for stereo endoscopes that estimates depth and optical flow to minimize two geometric losses for camera pose estimation. Most importantly, we introduce two learned adaptive per-pixel weight mappings that balance contributions according to the input image content. To do so, we train a Deep Declarative Network to take advantage of the expressiveness of deep-learning and the robustness of a novel geometric-based optimization approach. We validate our approach on the publicly available SCARED dataset and introduce a new in-vivo dataset, StereoMIS, which includes a wider spectrum of typically observed surgical settings. Results: Our method outperforms state-of-the-art methods on average and more importantly, in difficult scenarios where tissue deformations and breathing motion are visible. We observed that our proposed weight mappings attenuate the contribution of pixels on ambiguous regions of the images, such as deforming tissues. Conclusion: We demonstrate the effectiveness of our solution to robustly estimate the camera pose in challenging endoscopic surgical scenes. Our contributions can be used to improve related tasks like simultaneous localization and mapping (SLAM) or 3D reconstruction, therefore advancing surgical scene understanding in minimally-invasive surgery.
Fused Detection of Retinal Biomarkers in OCT Volumes
Jul 16, 2019
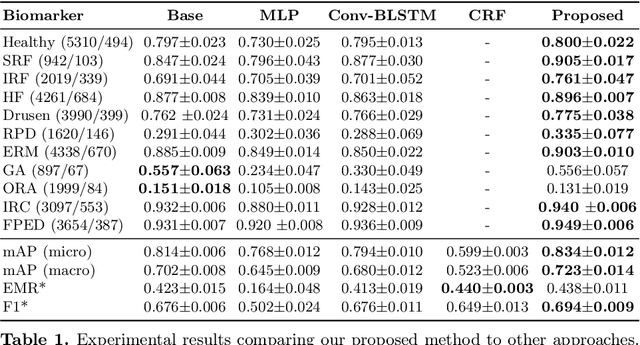


Optical Coherence Tomography (OCT) is the primary imaging modality for detecting pathological biomarkers associated to retinal diseases such as Age-Related Macular Degeneration. In practice, clinical diagnosis and treatment strategies are closely linked to biomarkers visible in OCT volumes and the ability to identify these plays an important role in the development of ophthalmic pharmaceutical products. In this context, we present a method that automatically predicts the presence of biomarkers in OCT cross-sections by incorporating information from the entire volume. We do so by adding a bidirectional LSTM to fuse the outputs of a Convolutional Neural Network that predicts individual biomarkers. We thus avoid the need to use pixel-wise annotations to train our method, and instead provide fine-grained biomarker information regardless. On a dataset of 416 volumes, we show that our approach imposes coherence between biomarker predictions across volume slices and our predictions are superior to several existing approaches.
Deep Multi Label Classification in Affine Subspaces
Jul 10, 2019


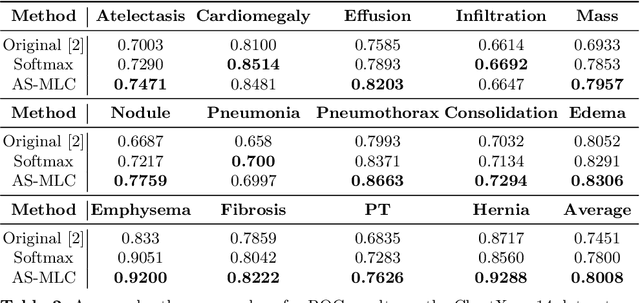
Multi-label classification (MLC) problems are becoming increasingly popular in the context of medical imaging. This has in part been driven by the fact that acquiring annotations for MLC is far less burdensome than for semantic segmentation and yet provides more expressiveness than multi-class classification. However, to train MLCs, most methods have resorted to similar objective functions as with traditional multi-class classification settings. We show in this work that such approaches are not optimal and instead propose a novel deep MLC classification method in affine subspace. At its core, the method attempts to pull features of class-labels towards different affine subspaces while maximizing the distance between them. We evaluate the method using two MLC medical imaging datasets and show a large performance increase compared to previous multi-label frameworks. This method can be seen as a plug-in replacement loss function and is trainable in an end-to-end fashion.
2017 Robotic Instrument Segmentation Challenge
Feb 21, 2019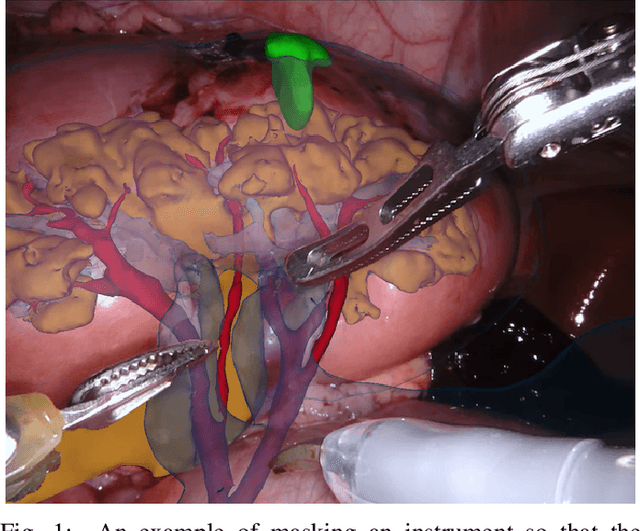
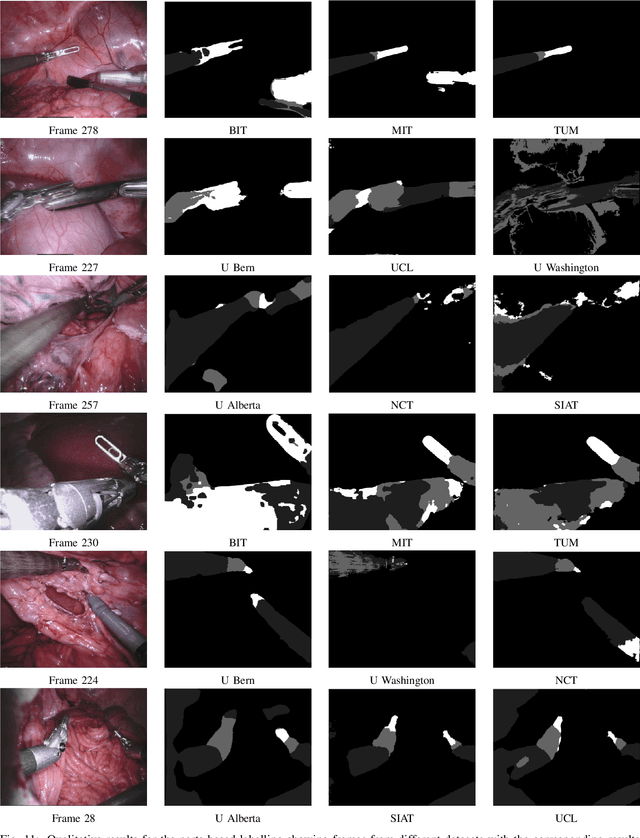

In mainstream computer vision and machine learning, public datasets such as ImageNet, COCO and KITTI have helped drive enormous improvements by enabling researchers to understand the strengths and limitations of different algorithms via performance comparison. However, this type of approach has had limited translation to problems in robotic assisted surgery as this field has never established the same level of common datasets and benchmarking methods. In 2015 a sub-challenge was introduced at the EndoVis workshop where a set of robotic images were provided with automatically generated annotations from robot forward kinematics. However, there were issues with this dataset due to the limited background variation, lack of complex motion and inaccuracies in the annotation. In this work we present the results of the 2017 challenge on robotic instrument segmentation which involved 10 teams participating in binary, parts and type based segmentation of articulated da Vinci robotic instruments.
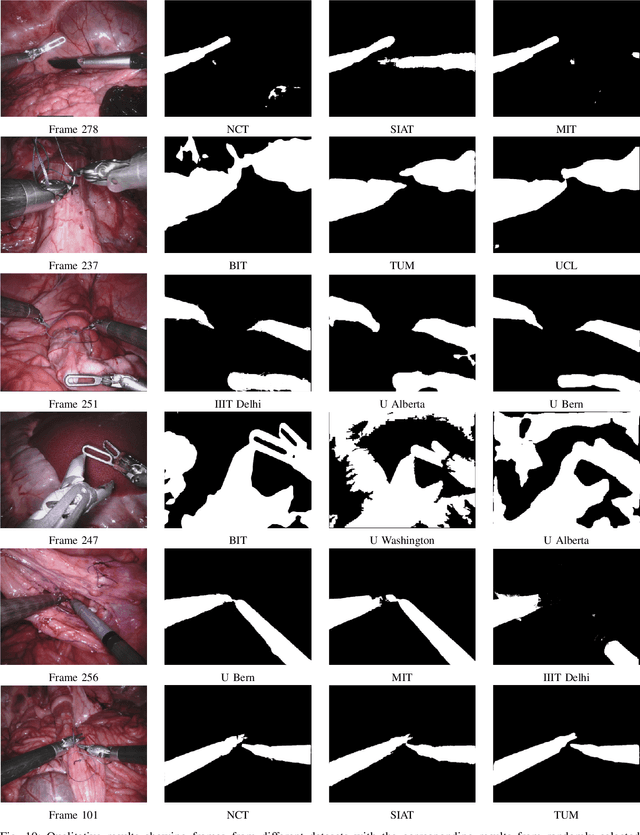
Comparative evaluation of instrument segmentation and tracking methods in minimally invasive surgery
May 07, 2018
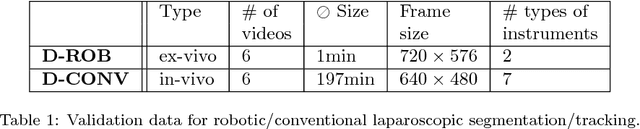

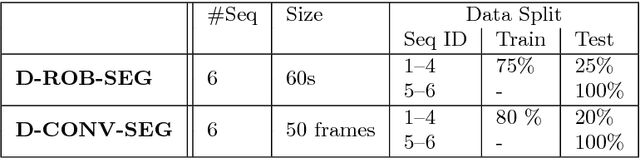
Intraoperative segmentation and tracking of minimally invasive instruments is a prerequisite for computer- and robotic-assisted surgery. Since additional hardware like tracking systems or the robot encoders are cumbersome and lack accuracy, surgical vision is evolving as promising techniques to segment and track the instruments using only the endoscopic images. However, what is missing so far are common image data sets for consistent evaluation and benchmarking of algorithms against each other. The paper presents a comparative validation study of different vision-based methods for instrument segmentation and tracking in the context of robotic as well as conventional laparoscopic surgery. The contribution of the paper is twofold: we introduce a comprehensive validation data set that was provided to the study participants and present the results of the comparative validation study. Based on the results of the validation study, we arrive at the conclusion that modern deep learning approaches outperform other methods in instrument segmentation tasks, but the results are still not perfect. Furthermore, we show that merging results from different methods actually significantly increases accuracy in comparison to the best stand-alone method. On the other hand, the results of the instrument tracking task show that this is still an open challenge, especially during challenging scenarios in conventional laparoscopic surgery.
Simultaneous Recognition and Pose Estimation of Instruments in Minimally Invasive Surgery
Oct 18, 2017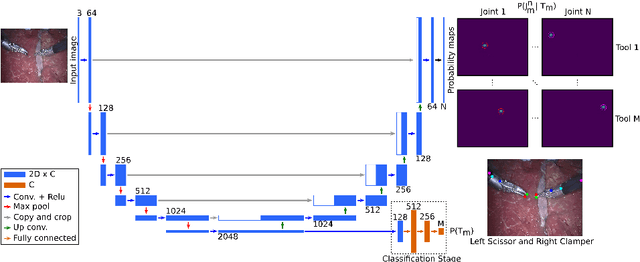
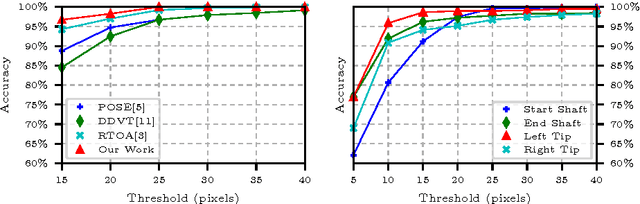
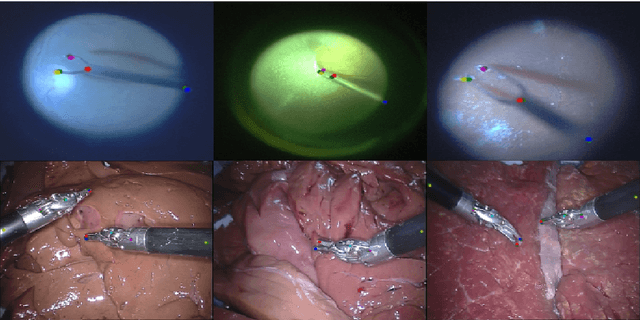
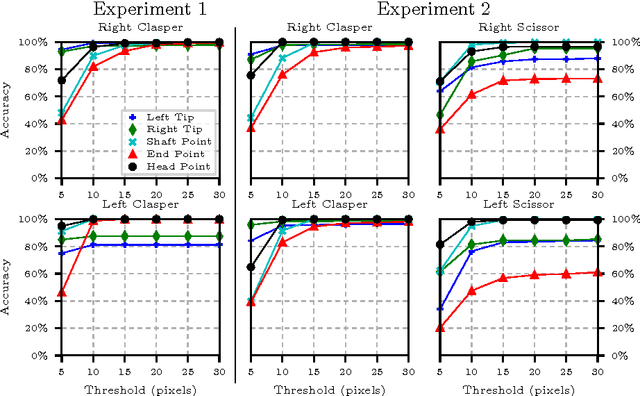
Detection of surgical instruments plays a key role in ensuring patient safety in minimally invasive surgery. In this paper, we present a novel method for 2D vision-based recognition and pose estimation of surgical instruments that generalizes to different surgical applications. At its core, we propose a novel scene model in order to simultaneously recognize multiple instruments as well as their parts. We use a Convolutional Neural Network architecture to embody our model and show that the cross-entropy loss is well suited to optimize its parameters which can be trained in an end-to-end fashion. An additional advantage of our approach is that instrument detection at test time is achieved while avoiding the need for scale-dependent sliding window evaluation. This allows our approach to be relatively parameter free at test time and shows good performance for both instrument detection and tracking. We show that our approach surpasses state-of-the-art results on in-vivo retinal microsurgery image data, as well as ex-vivo laparoscopic sequences.