 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAM-Fed: SAM-Guided Federated Semi-Supervised Learning for Medical Image Segmentation
Nov 18, 2025Medical image segmentation is clinically important, yet data privacy and the cost of expert annotation limit the availability of labeled data. Federated semi-supervised learning (FSSL) offers a solution but faces two challenges: pseudo-label reliability depends on the strength of local models, and client devices often require compact or heterogeneous architectures due to limited computational resources. These constraints reduce the quality and stability of pseudo-labels, while large models, though more accurate, cannot be trained or used for routine inference on client devices. We propose SAM-Fed, a federated semi-supervised framework that leverages a high-capacity segmentation foundation model to guide lightweight clients during training. SAM-Fed combines dual knowledge distillation with an adaptive agreement mechanism to refine pixel-level supervision. Experiments on skin lesion and polyp segmentation across homogeneous and heterogeneous settings show that SAM-Fed consistently outperforms state-of-the-art FSSL methods.
Inferring geometry and material properties from Mueller matrices with machine learning
Aug 27, 2025Mueller matrices (MMs) encode information on geometry and material properties, but recovering both simultaneously is an ill-posed problem. We explore whether MMs contain sufficient information to infer surface geometry and material properties with machine learning. We use a dataset of spheres of various isotropic materials, with MMs captured over the full angular domain at five visible wavelengths (450-650 nm). We train machine learning models to predict material properties and surface normals using only these MMs as input. We demonstrate that, even when the material type is unknown, surface normals can be predicted and object geometry reconstructed. Moreover, MMs allow models to identify material types correctly. Further analyses show that diagonal elements are key for material characterization, and off-diagonal elements are decisive for normal estimation.
GynSurg: A Comprehensive Gynecology Laparoscopic Surgery Dataset
Jun 12, 2025Recent advances in deep learning have transformed computer-assisted intervention and surgical video analysis, driving improvements not only in surgical training, intraoperative decision support, and patient outcomes, but also in postoperative documentation and surgical discovery. Central to these developments is the availability of large, high-quality annotated datasets. In gynecologic laparoscopy, surgical scene understanding and action recognition are fundamental for building intelligent systems that assist surgeons during operations and provide deeper analysis after surgery. However, existing datasets are often limited by small scale, narrow task focus, or insufficiently detailed annotations, limiting their utility for comprehensive, end-to-end workflow analysis. To address these limitations, we introduce GynSurg, the largest and most diverse multi-task dataset for gynecologic laparoscopic surgery to date. GynSurg provides rich annotations across multiple tasks, supporting applications in action recognition, semantic segmentation, surgical documentation, and discovery of novel procedural insights. We demonstrate the dataset quality and versatility by benchmarking state-of-the-art models under a standardized training protocol. To accelerate progress in the field, we publicly release the GynSurg dataset and its annotations
WetCat: Automating Skill Assessment in Wetlab Cataract Surgery Videos
Jun 10, 2025To meet the growing demand for systematic surgical training, wetlab environments have become indispensable platforms for hands-on practice in ophthalmology. Yet, traditional wetlab training depends heavily on manual performance evaluations, which are labor-intensive, time-consuming, and often subject to variability. Recent advances in computer vision offer promising avenues for automated skill assessment, enhancing both the efficiency and objectivity of surgical education. Despite notable progress in ophthalmic surgical datasets, existing resources predominantly focus on real surgeries or isolated tasks, falling short of supporting comprehensive skill evaluation in controlled wetlab settings. To address these limitations, we introduce WetCat, the first dataset of wetlab cataract surgery videos specifically curated for automated skill assessment. WetCat comprises high-resolution recordings of surgeries performed by trainees on artificial eyes, featuring comprehensive phase annotations and semantic segmentations of key anatomical structures. These annotations are meticulously designed to facilitate skill assessment during the critical capsulorhexis and phacoemulsification phases, adhering to standardized surgical skill assessment frameworks. By focusing on these essential phases, WetCat enables the development of interpretable, AI-driven evaluation tools aligned with established clinical metrics. This dataset lays a strong foundation for advancing objective, scalable surgical education and sets a new benchmark for automated workflow analysis and skill assessment in ophthalmology training. The dataset and annotations are publicly available in Synapse https://www.synapse.org/Synapse:syn66401174/files.
Feedback-Driven Pseudo-Label Reliability Assessment: Redefining Thresholding for Semi-Supervised Semantic Segmentation
May 12, 2025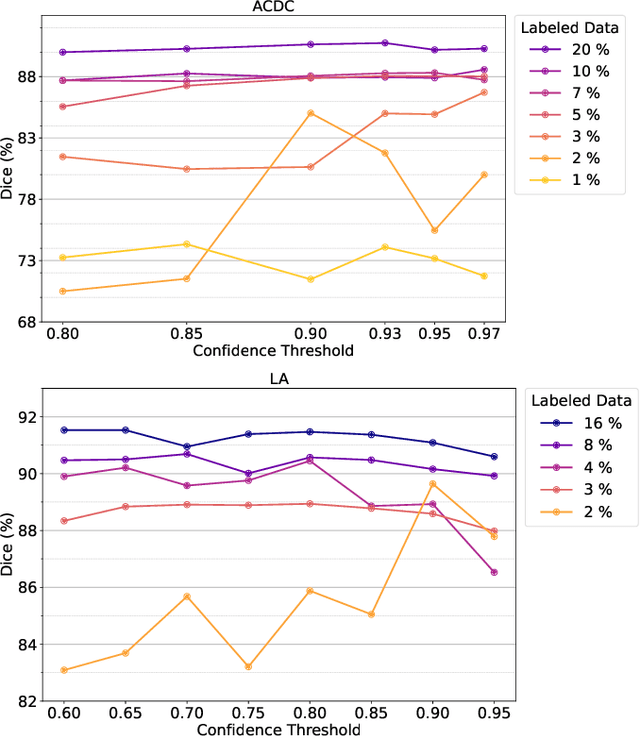
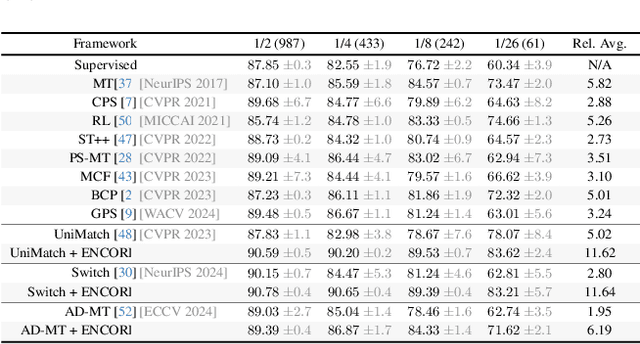
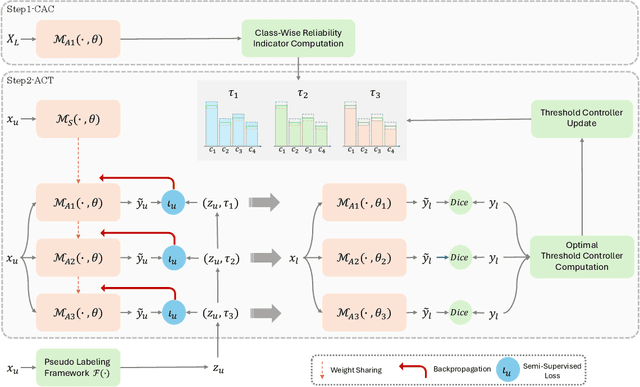
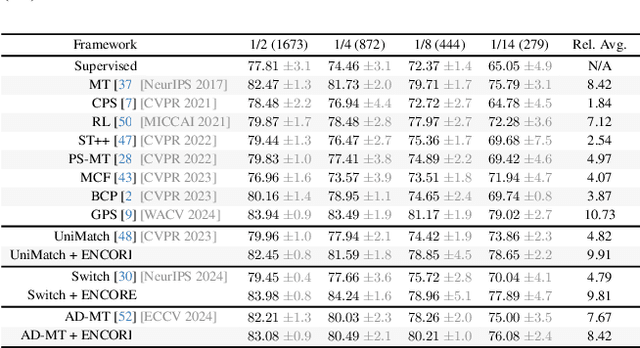
Semi-supervised learning leverages unlabeled data to enhance model performance, addressing the limitations of fully supervised approaches. Among its strategies, pseudo-supervision has proven highly effective, typically relying on one or multiple teacher networks to refine pseudo-labels before training a student network. A common practice in pseudo-supervision is filtering pseudo-labels based on pre-defined confidence thresholds or entropy. However, selecting optimal thresholds requires large labeled datasets, which are often scarce in real-world semi-supervised scenarios. To overcome this challenge, we propose Ensemble-of-Confidence Reinforcement (ENCORE), a dynamic feedback-driven thresholding strategy for pseudo-label selection. Instead of relying on static confidence thresholds, ENCORE estimates class-wise true-positive confidence within the unlabeled dataset and continuously adjusts thresholds based on the model's response to different levels of pseudo-label filtering. This feedback-driven mechanism ensures the retention of informative pseudo-labels while filtering unreliable ones, enhancing model training without manual threshold tuning. Our method seamlessly integrates into existing pseudo-supervision frameworks and significantly improves segmentation performance, particularly in data-scarce conditions. Extensive experiments demonstrate that integrating ENCORE with existing pseudo-supervision frameworks enhances performance across multiple datasets and network architectures, validating its effectiveness in semi-supervised learning.
Dual Invariance Self-training for Reliable Semi-supervised Surgical Phase Recognition
Jan 29, 2025



Accurate surgical phase recognition is crucial for advancing computer-assisted interventions, yet the scarcity of labeled data hinders training reliable deep learning models. Semi-supervised learning (SSL), particularly with pseudo-labeling, shows promise over fully supervised methods but often lacks reliable pseudo-label assessment mechanisms. To address this gap, we propose a novel SSL framework, Dual Invariance Self-Training (DIST), that incorporates both Temporal and Transformation Invariance to enhance surgical phase recognition. Our two-step self-training process dynamically selects reliable pseudo-labels, ensuring robust pseudo-supervision. Our approach mitigates the risk of noisy pseudo-labels, steering decision boundaries toward true data distribution and improving generalization to unseen data. Evaluations on Cataract and Cholec80 datasets show our method outperforms state-of-the-art SSL approaches, consistently surpassing both supervised and SSL baselines across various network architectures.
SAM-DA: Decoder Adapter for Efficient Medical Domain Adaptation
Jan 12, 2025



This paper addresses the domain adaptation challenge for semantic segmentation in medical imaging. Despite the impressive performance of recent foundational segmentation models like SAM on natural images, they struggle with medical domain images. Beyond this, recent approaches that perform end-to-end fine-tuning of models are simply not computationally tractable. To address this, we propose a novel SAM adapter approach that minimizes the number of trainable parameters while achieving comparable performances to full fine-tuning. The proposed SAM adapter is strategically placed in the mask decoder, offering excellent and broad generalization capabilities and improved segmentation across both fully supervised and test-time domain adaptation tasks. Extensive validation on four datasets showcases the adapter's efficacy, outperforming existing methods while training less than 1% of SAM's total parameters.
Active Learning with Context Sampling and One-vs-Rest Entropy for Semantic Segmentation
Dec 09, 2024



Multi-class semantic segmentation remains a cornerstone challenge in computer vision. Yet, dataset creation remains excessively demanding in time and effort, especially for specialized domains. Active Learning (AL) mitigates this challenge by selecting data points for annotation strategically. However, existing patch-based AL methods often overlook boundary pixels critical information, essential for accurate segmentation. We present OREAL, a novel patch-based AL method designed for multi-class semantic segmentation. OREAL enhances boundary detection by employing maximum aggregation of pixel-wise uncertainty scores. Additionally, we introduce one-vs-rest entropy, a novel uncertainty score function that computes class-wise uncertainties while achieving implicit class balancing during dataset creation. Comprehensive experiments across diverse datasets and model architectures validate our hypothesis.
Non-Linear Outlier Synthesis for Out-of-Distribution Detection
Nov 20, 2024



The reliability of supervised classifiers is severely hampered by their limitations in dealing with unexpected inputs, leading to great interest in out-of-distribution (OOD) detection. Recently, OOD detectors trained on synthetic outliers, especially those generated by large diffusion models, have shown promising results in defining robust OOD decision boundaries. Building on this progress, we present NCIS, which enhances the quality of synthetic outliers by operating directly in the diffusion's model embedding space rather than combining disjoint models as in previous work and by modeling class-conditional manifolds with a conditional volume-preserving network for more expressive characterization of the training distribution. We demonstrate that these improvements yield new state-of-the-art OOD detection results on standard ImageNet100 and CIFAR100 benchmarks and provide insights into the importance of data pre-processing and other key design choices. We make our code available at \url{https://github.com/LarsDoorenbos/NCIS}.
Online 3D reconstruction and dense tracking in endoscopic videos
Sep 09, 2024



3D scene reconstruction from stereo endoscopic video data is crucial for advancing surgical interventions. In this work, we present an online framework for online, dense 3D scene reconstruction and tracking, aimed at enhancing surgical scene understanding and assisting interventions. Our method dynamically extends a canonical scene representation using Gaussian splatting, while modeling tissue deformations through a sparse set of control points. We introduce an efficient online fitting algorithm that optimizes the scene parameters, enabling consistent tracking and accurate reconstruction. Through experiments on the StereoMIS dataset, we demonstrate the effectiveness of our approach, outperforming state-of-the-art tracking methods and achieving comparable performance to offline reconstruction techniques. Our work enables various downstream applications thus contributing to advancing the capabilities of surgical assistance systems.