 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAM-DA: Decoder Adapter for Efficient Medical Domain Adaptation
Jan 12, 2025



This paper addresses the domain adaptation challenge for semantic segmentation in medical imaging. Despite the impressive performance of recent foundational segmentation models like SAM on natural images, they struggle with medical domain images. Beyond this, recent approaches that perform end-to-end fine-tuning of models are simply not computationally tractable. To address this, we propose a novel SAM adapter approach that minimizes the number of trainable parameters while achieving comparable performances to full fine-tuning. The proposed SAM adapter is strategically placed in the mask decoder, offering excellent and broad generalization capabilities and improved segmentation across both fully supervised and test-time domain adaptation tasks. Extensive validation on four datasets showcases the adapter's efficacy, outperforming existing methods while training less than 1% of SAM's total parameters.
Full or Weak annotations? An adaptive strategy for budget-constrained annotation campaigns
Mar 21, 2023

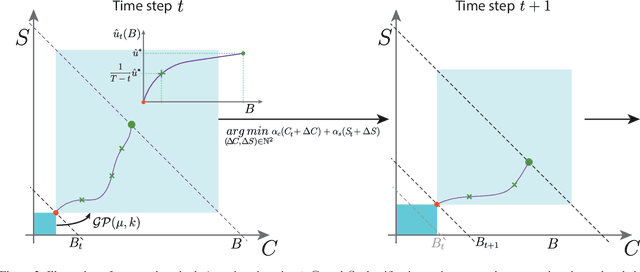

Annotating new datasets for machine learning tasks is tedious, time-consuming, and costly. For segmentation applications, the burden is particularly high as manual delineations of relevant image content are often extremely expensive or can only be done by experts with domain-specific knowledge. Thanks to developments in transfer learning and training with weak supervision, segmentation models can now also greatly benefit from annotations of different kinds. However, for any new domain application looking to use weak supervision, the dataset builder still needs to define a strategy to distribute full segmentation and other weak annotations. Doing so is challenging, however, as it is a priori unknown how to distribute an annotation budget for a given new dataset. To this end, we propose a novel approach to determine annotation strategies for segmentation datasets, whereby estimating what proportion of segmentation and classification annotations should be collected given a fixed budget. To do so, our method sequentially determines proportions of segmentation and classification annotations to collect for budget-fractions by modeling the expected improvement of the final segmentation model. We show in our experiments that our approach yields annotations that perform very close to the optimal for a number of different annotation budgets and datasets.