 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Learning with Context Sampling and One-vs-Rest Entropy for Semantic Segmentation
Dec 09, 2024



Multi-class semantic segmentation remains a cornerstone challenge in computer vision. Yet, dataset creation remains excessively demanding in time and effort, especially for specialized domains. Active Learning (AL) mitigates this challenge by selecting data points for annotation strategically. However, existing patch-based AL methods often overlook boundary pixels critical information, essential for accurate segmentation. We present OREAL, a novel patch-based AL method designed for multi-class semantic segmentation. OREAL enhances boundary detection by employing maximum aggregation of pixel-wise uncertainty scores. Additionally, we introduce one-vs-rest entropy, a novel uncertainty score function that computes class-wise uncertainties while achieving implicit class balancing during dataset creation. Comprehensive experiments across diverse datasets and model architectures validate our hypothesis.
Correlation-aware active learning for surgery video segmentation
Nov 15, 2023



Semantic segmentation is a complex task that relies heavily on large amounts of annotated image data. However, annotating such data can be time-consuming and resource-intensive, especially in the medical domain. Active Learning (AL) is a popular approach that can help to reduce this burden by iteratively selecting images for annotation to improve the model performance. In the case of video data, it is important to consider the model uncertainty and the temporal nature of the sequences when selecting images for annotation. This work proposes a novel AL strategy for surgery video segmentation, \COALSamp{}, COrrelation-aWare Active Learning. Our approach involves projecting images into a latent space that has been fine-tuned using contrastive learning and then selecting a fixed number of representative images from local clusters of video frames. We demonstrate the effectiveness of this approach on two video datasets of surgical instruments and three real-world video datasets. The datasets and code will be made publicly available upon receiving necessary approvals.
Beyond the Pixel-Wise Loss for Topology-Aware Delineation
Dec 06, 2017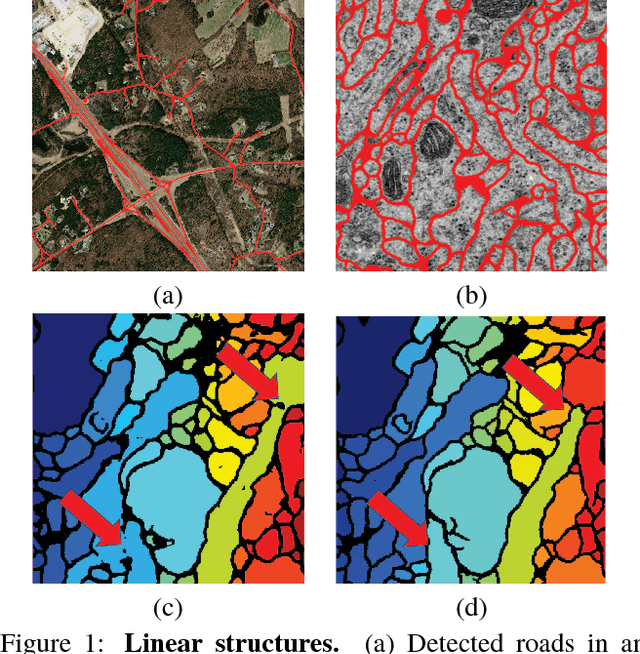

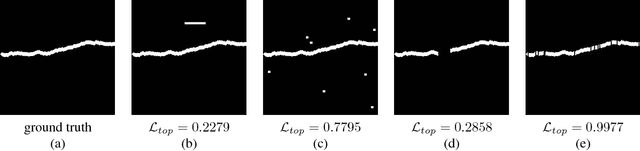

Delineation of curvilinear structures is an important problem in Computer Vision with multiple practical applications. With the advent of Deep Learning, many current approaches on automatic delineation have focused on finding more powerful deep architectures, but have continued using the habitual pixel-wise losses such as binary cross-entropy. In this paper we claim that pixel-wise losses alone are unsuitable for this problem because of their inability to reflect the topological impact of mistakes in the final prediction. We propose a new loss term that is aware of the higher-order topological features of linear structures. We also introduce a refinement pipeline that iteratively applies the same model over the previous delineation to refine the predictions at each step while keeping the number of parameters and the complexity of the model constant. When combined with the standard pixel-wise loss, both our new loss term and our iterative refinement boost the quality of the predicted delineations, in some cases almost doubling the accuracy as compared to the same classifier trained with the binary cross-entropy alone. We show that our approach outperforms state-of-the-art methods on a wide range of data, from microscopy to aerial images.