 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Image Modelling for retinal OCT understanding
May 23, 2024



This work explores the effectiveness of masked image modelling for learning representations of retinal OCT images. To this end, we leverage Masked Autoencoders (MAE), a simple and scalable method for self-supervised learning, to obtain a powerful and general representation for OCT images by training on 700K OCT images from 41K patients collected under real world clinical settings. We also provide the first extensive evaluation for a model of OCT on a challenging battery of 6 downstream tasks. Our model achieves strong performance when fully finetuned but can also serve as a versatile frozen feature extractor for many tasks using lightweight adapters. Furthermore, we propose an extension of the MAE pretraining to fuse OCT with an auxiliary modality, namely, IR fundus images and learn a joint model for both. We demonstrate our approach improves performance on a multimodal downstream application. Our experiments utilize most publicly available OCT datasets, thus enabling future comparisons. Our code and model weights are publicly available https://github.com/TheoPis/MIM_OCT.
Stochastic Segmentation with Conditional Categorical Diffusion Models
Mar 17, 2023Semantic segmentation has made significant progress in recent years thanks to deep neural networks, but the common objective of generating a single segmentation output that accurately matches the image's content may not be suitable for safety-critical domains such as medical diagnostics and autonomous driving. Instead, multiple possible correct segmentation maps may be required to reflect the true distribution of annotation maps. In this context, stochastic semantic segmentation methods must learn to predict conditional distributions of labels given the image, but this is challenging due to the typically multimodal distributions, high-dimensional output spaces, and limited annotation data. To address these challenges, we propose a conditional categorical diffusion model (CCDM) for semantic segmentation based on Denoising Diffusion Probabilistic Models. Our model is conditioned to the input image, enabling it to generate multiple segmentation label maps that account for the aleatoric uncertainty arising from divergent ground truth annotations. Our experimental results show that CCDM achieves state-of-the-art performance on LIDC, a stochastic semantic segmentation dataset, and outperforms established baselines on the classical segmentation dataset Cityscapes.
Multi-scale and Cross-scale Contrastive Learning for Semantic Segmentation
Mar 25, 2022
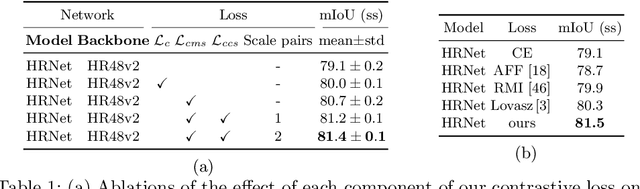


This work considers supervised contrastive learning for semantic segmentation. Our approach is model agnostic. We apply contrastive learning to enhance the discriminative power of the multi-scale features extracted by semantic segmentation networks. Our key methodological insight is to leverage samples from the feature spaces emanating from multiple stages of a model's encoder itself requiring neither data augmentation nor online memory banks to obtain a diverse set of samples. To allow for such an extension we introduce an efficient and effective sampling process, that enables applying contrastive losses over the encoder's features at multiple scales. Furthermore, by first mapping the encoder's multi-scale representations to a common feature space, we instantiate a novel form of supervised local-global constraint by introducing cross-scale contrastive learning linking high-resolution local features to low-resolution global features. Combined, our multi-scale and cross-scale contrastive losses boost performance of various models (DeepLabV3, HRNet, OCRNet, UPerNet) with both CNN and Transformer backbones, when evaluated on 4 diverse datasets from natural (Cityscapes, PascalContext, ADE20K) but also surgical (CaDIS) domains.
2020 CATARACTS Semantic Segmentation Challenge
Oct 21, 2021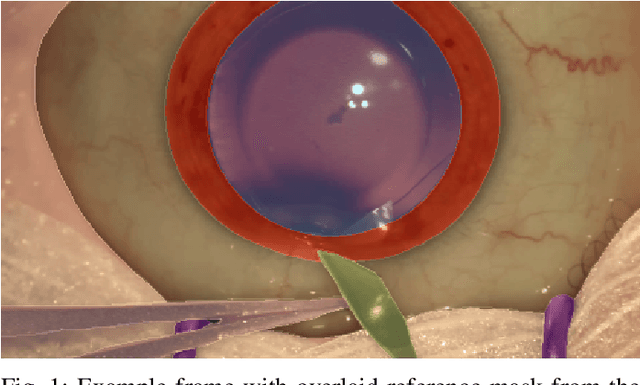
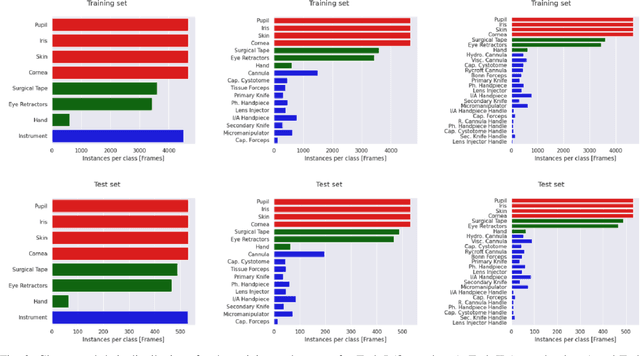
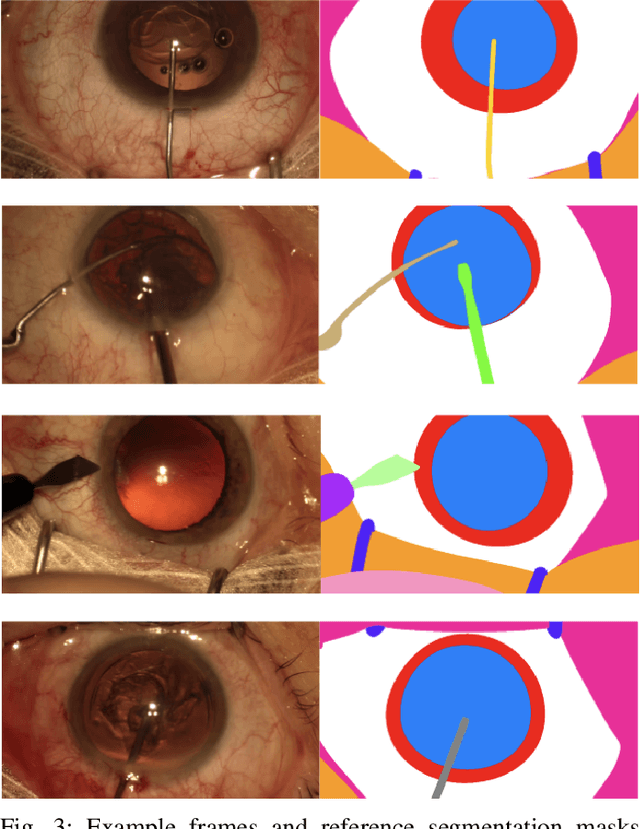
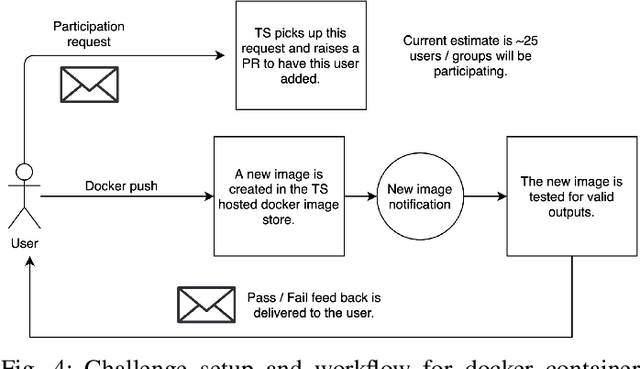
Surgical scene segmentation is essential for anatomy and instrument localization which can be further used to assess tissue-instrument interactions during a surgical procedure. In 2017, the Challenge on Automatic Tool Annotation for cataRACT Surgery (CATARACTS) released 50 cataract surgery videos accompanied by instrument usage annotations. These annotations included frame-level instrument presence information. In 2020, we released pixel-wise semantic annotations for anatomy and instruments for 4670 images sampled from 25 videos of the CATARACTS training set. The 2020 CATARACTS Semantic Segmentation Challenge, which was a sub-challenge of the 2020 MICCAI Endoscopic Vision (EndoVis) Challenge, presented three sub-tasks to assess participating solutions on anatomical structure and instrument segmentation. Their performance was assessed on a hidden test set of 531 images from 10 videos of the CATARACTS test set.
Effective semantic segmentation in Cataract Surgery: What matters most?
Aug 13, 2021

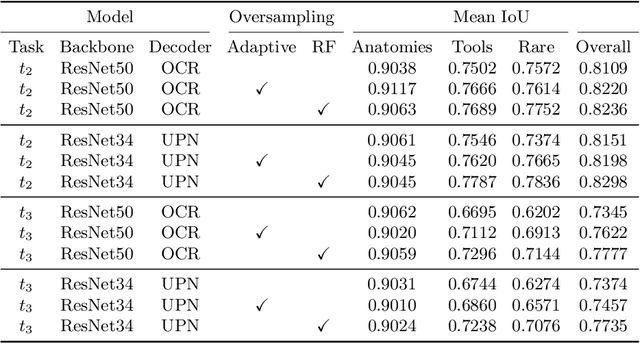
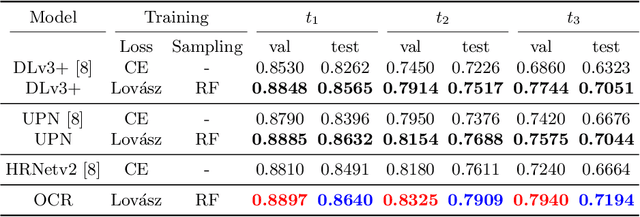
Our work proposes neural network design choices that set the state-of-the-art on a challenging public benchmark on cataract surgery, CaDIS. Our methodology achieves strong performance across three semantic segmentation tasks with increasingly granular surgical tool class sets by effectively handling class imbalance, an inherent challenge in any surgical video. We consider and evaluate two conceptually simple data oversampling methods as well as different loss functions. We show significant performance gains across network architectures and tasks especially on the rarest tool classes, thereby presenting an approach for achieving high performance when imbalanced granular datasets are considered. Our code and trained models are available at https://github.com/RViMLab/MICCAI2021_Cataract_semantic_segmentation and qualitative results on unseen surgical video can be found at https://youtu.be/twVIPUj1WZM.