 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-scale and Cross-scale Contrastive Learning for Semantic Segmentation
Mar 25, 2022
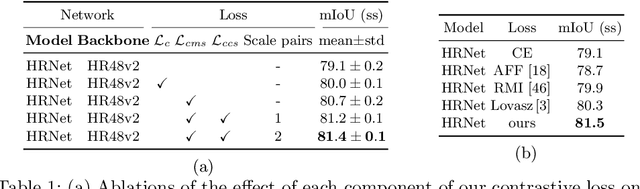


This work considers supervised contrastive learning for semantic segmentation. Our approach is model agnostic. We apply contrastive learning to enhance the discriminative power of the multi-scale features extracted by semantic segmentation networks. Our key methodological insight is to leverage samples from the feature spaces emanating from multiple stages of a model's encoder itself requiring neither data augmentation nor online memory banks to obtain a diverse set of samples. To allow for such an extension we introduce an efficient and effective sampling process, that enables applying contrastive losses over the encoder's features at multiple scales. Furthermore, by first mapping the encoder's multi-scale representations to a common feature space, we instantiate a novel form of supervised local-global constraint by introducing cross-scale contrastive learning linking high-resolution local features to low-resolution global features. Combined, our multi-scale and cross-scale contrastive losses boost performance of various models (DeepLabV3, HRNet, OCRNet, UPerNet) with both CNN and Transformer backbones, when evaluated on 4 diverse datasets from natural (Cityscapes, PascalContext, ADE20K) but also surgical (CaDIS) domains.