 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOflib: Facilitating Operations with and on Optical Flow Fields in Python
Oct 14, 2022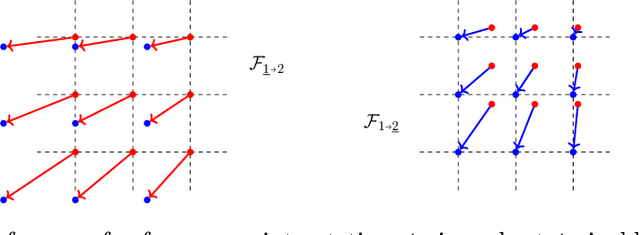


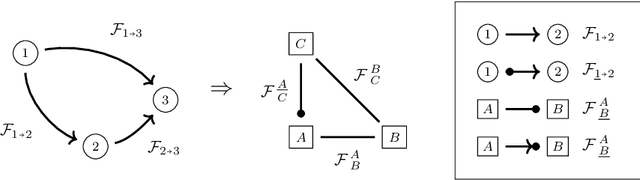
We present a robust theoretical framework for the characterisation and manipulation of optical flow, i.e 2D vector fields, in the context of their use in motion estimation algorithms and beyond. The definition of two frames of reference guides the mathematical derivation of flow field application, inversion, evaluation, and composition operations. This structured approach is then used as the foundation for an implementation in Python 3, with the fully differentiable PyTorch version oflibpytorch supporting back-propagation as required for deep learning. We verify the flow composition method empirically and provide a working example for its application to optical flow ground truth in synthetic training data creation. All code is publicly available.
Multi-scale and Cross-scale Contrastive Learning for Semantic Segmentation
Mar 25, 2022
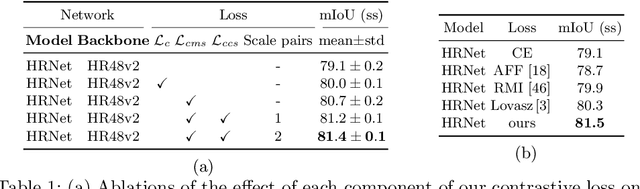


This work considers supervised contrastive learning for semantic segmentation. Our approach is model agnostic. We apply contrastive learning to enhance the discriminative power of the multi-scale features extracted by semantic segmentation networks. Our key methodological insight is to leverage samples from the feature spaces emanating from multiple stages of a model's encoder itself requiring neither data augmentation nor online memory banks to obtain a diverse set of samples. To allow for such an extension we introduce an efficient and effective sampling process, that enables applying contrastive losses over the encoder's features at multiple scales. Furthermore, by first mapping the encoder's multi-scale representations to a common feature space, we instantiate a novel form of supervised local-global constraint by introducing cross-scale contrastive learning linking high-resolution local features to low-resolution global features. Combined, our multi-scale and cross-scale contrastive losses boost performance of various models (DeepLabV3, HRNet, OCRNet, UPerNet) with both CNN and Transformer backbones, when evaluated on 4 diverse datasets from natural (Cityscapes, PascalContext, ADE20K) but also surgical (CaDIS) domains.
Effective semantic segmentation in Cataract Surgery: What matters most?
Aug 13, 2021

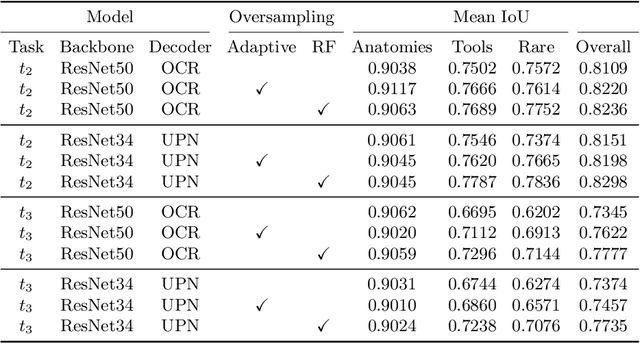
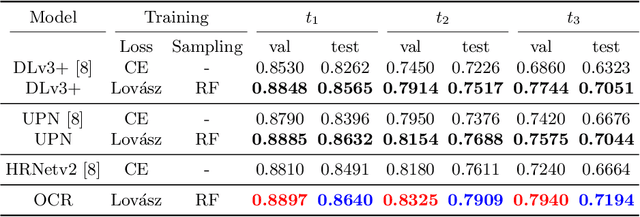
Our work proposes neural network design choices that set the state-of-the-art on a challenging public benchmark on cataract surgery, CaDIS. Our methodology achieves strong performance across three semantic segmentation tasks with increasingly granular surgical tool class sets by effectively handling class imbalance, an inherent challenge in any surgical video. We consider and evaluate two conceptually simple data oversampling methods as well as different loss functions. We show significant performance gains across network architectures and tasks especially on the rarest tool classes, thereby presenting an approach for achieving high performance when imbalanced granular datasets are considered. Our code and trained models are available at https://github.com/RViMLab/MICCAI2021_Cataract_semantic_segmentation and qualitative results on unseen surgical video can be found at https://youtu.be/twVIPUj1WZM.