 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Slices to Structures: Unsupervised 3D Reconstruction of Female Pelvic Anatomy from Freehand Transvaginal Ultrasound
Aug 20, 2025Volumetric ultrasound has the potential to significantly improve diagnostic accuracy and clinical decision-making, yet its widespread adoption remains limited by dependence on specialized hardware and restrictive acquisition protocols. In this work, we present a novel unsupervised framework for reconstructing 3D anatomical structures from freehand 2D transvaginal ultrasound (TVS) sweeps, without requiring external tracking or learned pose estimators. Our method adapts the principles of Gaussian Splatting to the domain of ultrasound, introducing a slice-aware, differentiable rasterizer tailored to the unique physics and geometry of ultrasound imaging. We model anatomy as a collection of anisotropic 3D Gaussians and optimize their parameters directly from image-level supervision, leveraging sensorless probe motion estimation and domain-specific geometric priors. The result is a compact, flexible, and memory-efficient volumetric representation that captures anatomical detail with high spatial fidelity. This work demonstrates that accurate 3D reconstruction from 2D ultrasound images can be achieved through purely computational means, offering a scalable alternative to conventional 3D systems and enabling new opportunities for AI-assisted analysis and diagnosis.
Targeted Visual Prompting for Medical Visual Question Answering
Aug 06, 2024



With growing interest in recent years, medical visual question answering (Med-VQA) has rapidly evolved, with multimodal large language models (MLLMs) emerging as an alternative to classical model architectures. Specifically, their ability to add visual information to the input of pre-trained LLMs brings new capabilities for image interpretation. However, simple visual errors cast doubt on the actual visual understanding abilities of these models. To address this, region-based questions have been proposed as a means to assess and enhance actual visual understanding through compositional evaluation. To combine these two perspectives, this paper introduces targeted visual prompting to equip MLLMs with region-based questioning capabilities. By presenting the model with both the isolated region and the region in its context in a customized visual prompt, we show the effectiveness of our method across multiple datasets while comparing it to several baseline models. Our code and data are available at https://github.com/sergiotasconmorales/locvqallm.
Localized Questions in Medical Visual Question Answering
Jul 03, 2023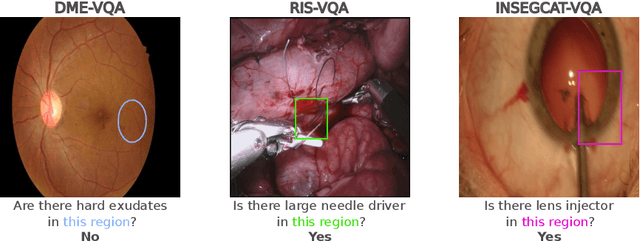
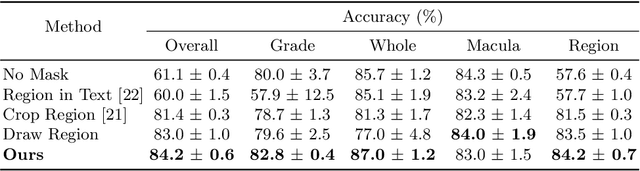
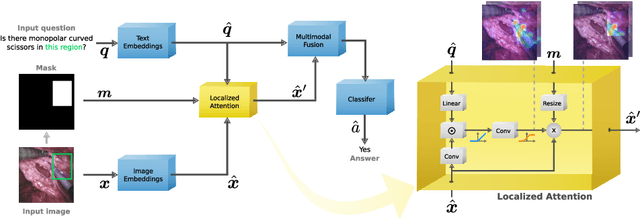
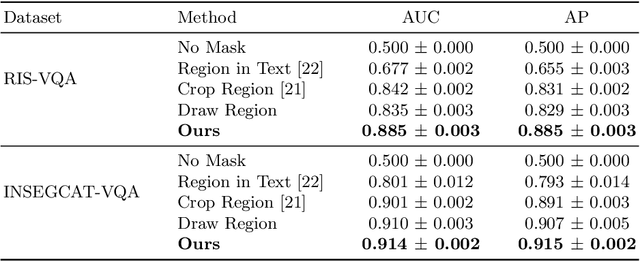
Visual Question Answering (VQA) models aim to answer natural language questions about given images. Due to its ability to ask questions that differ from those used when training the model, medical VQA has received substantial attention in recent years. However, existing medical VQA models typically focus on answering questions that refer to an entire image rather than where the relevant content may be located in the image. Consequently, VQA models are limited in their interpretability power and the possibility to probe the model about specific image regions. This paper proposes a novel approach for medical VQA that addresses this limitation by developing a model that can answer questions about image regions while considering the context necessary to answer the questions. Our experimental results demonstrate the effectiveness of our proposed model, outperforming existing methods on three datasets. Our code and data are available at https://github.com/sergiotasconmorales/locvqa.
Logical Implications for Visual Question Answering Consistency
Mar 16, 2023

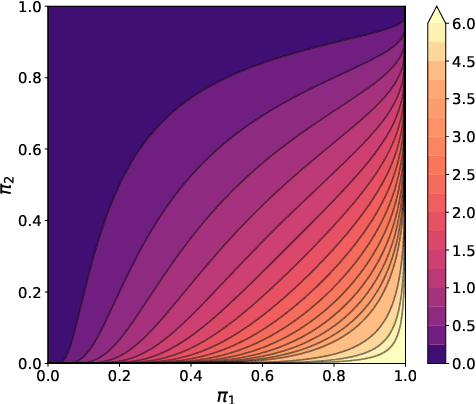

Despite considerable recent progress in Visual Question Answering (VQA) models, inconsistent or contradictory answers continue to cast doubt on their true reasoning capabilities. However, most proposed methods use indirect strategies or strong assumptions on pairs of questions and answers to enforce model consistency. Instead, we propose a novel strategy intended to improve model performance by directly reducing logical inconsistencies. To do this, we introduce a new consistency loss term that can be used by a wide range of the VQA models and which relies on knowing the logical relation between pairs of questions and answers. While such information is typically not available in VQA datasets, we propose to infer these logical relations using a dedicated language model and use these in our proposed consistency loss function. We conduct extensive experiments on the VQA Introspect and DME datasets and show that our method brings improvements to state-of-the-art VQA models, while being robust across different architectures and settings.
Consistency-preserving Visual Question Answering in Medical Imaging
Jun 27, 2022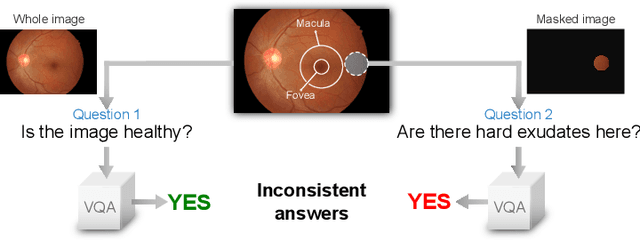
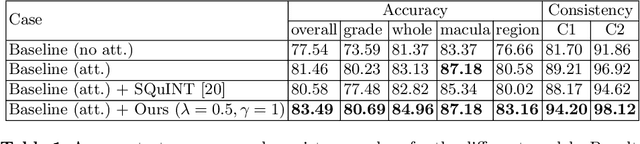
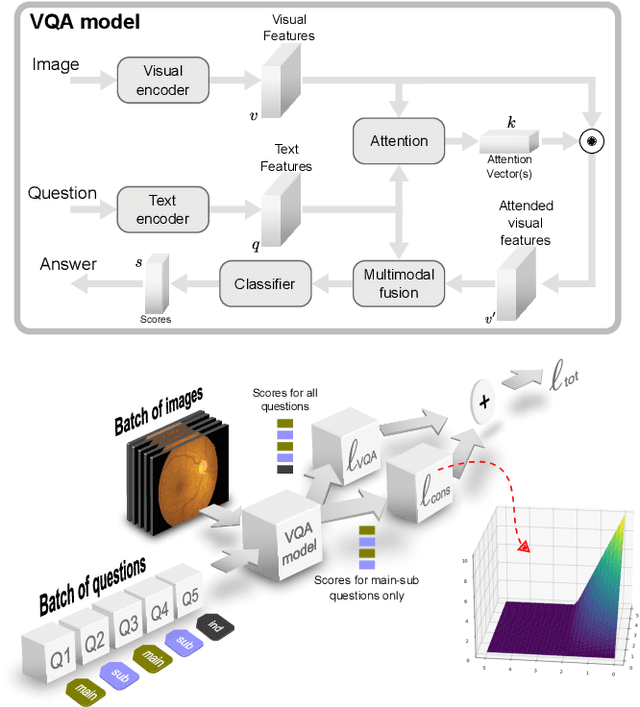
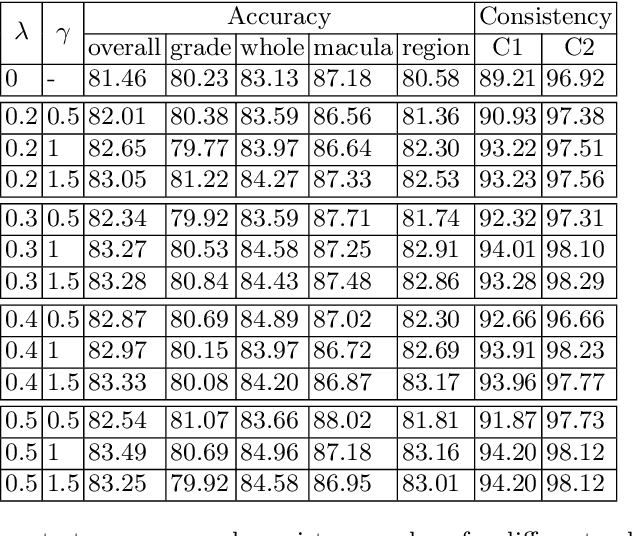
Visual Question Answering (VQA) models take an image and a natural-language question as input and infer the answer to the question. Recently, VQA systems in medical imaging have gained popularity thanks to potential advantages such as patient engagement and second opinions for clinicians. While most research efforts have been focused on improving architectures and overcoming data-related limitations, answer consistency has been overlooked even though it plays a critical role in establishing trustworthy models. In this work, we propose a novel loss function and corresponding training procedure that allows the inclusion of relations between questions into the training process. Specifically, we consider the case where implications between perception and reasoning questions are known a-priori. To show the benefits of our approach, we evaluate it on the clinically relevant task of Diabetic Macular Edema (DME) staging from fundus imaging. Our experiments show that our method outperforms state-of-the-art baselines, not only by improving model consistency, but also in terms of overall model accuracy. Our code and data are available at https://github.com/sergiotasconmorales/consistency_vqa.