 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecover and Identify: A Generative Dual Model for Cross-Resolution Person Re-Identification
Aug 16, 2019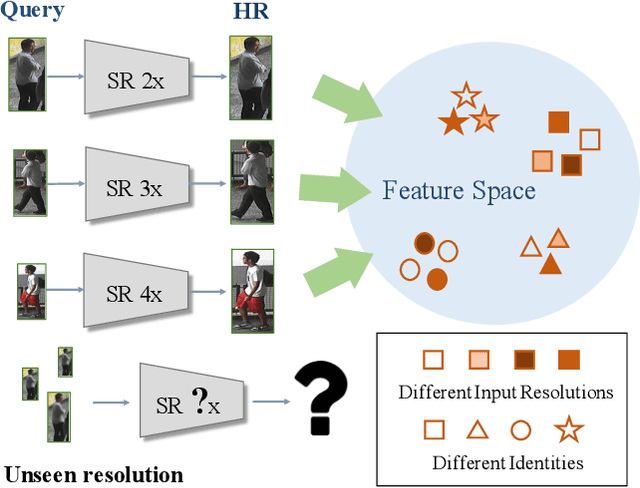
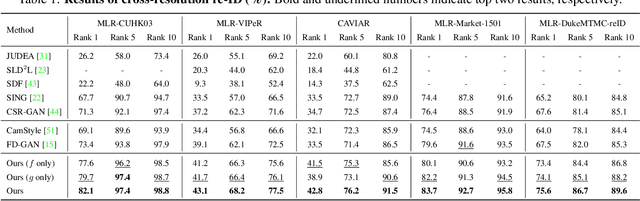
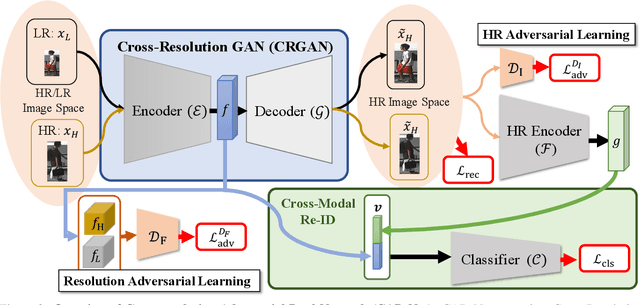

Person re-identification (re-ID) aims at matching images of the same identity across camera views. Due to varying distances between cameras and persons of interest, resolution mismatch can be expected, which would degrade person re-ID performance in real-world scenarios. To overcome this problem, we propose a novel generative adversarial network to address cross-resolution person re-ID, allowing query images with varying resolutions. By advancing adversarial learning techniques, our proposed model learns resolution-invariant image representations while being able to recover the missing details in low-resolution input images. The resulting features can be jointly applied for improving person re-ID performance due to preserving resolution invariance and recovering re-ID oriented discriminative details. Our experiments on five benchmark datasets confirm the effectiveness of our approach and its superiority over the state-of-the-art methods, especially when the input resolutions are unseen during training.
Learning Resolution-Invariant Deep Representations for Person Re-Identification
Jul 25, 2019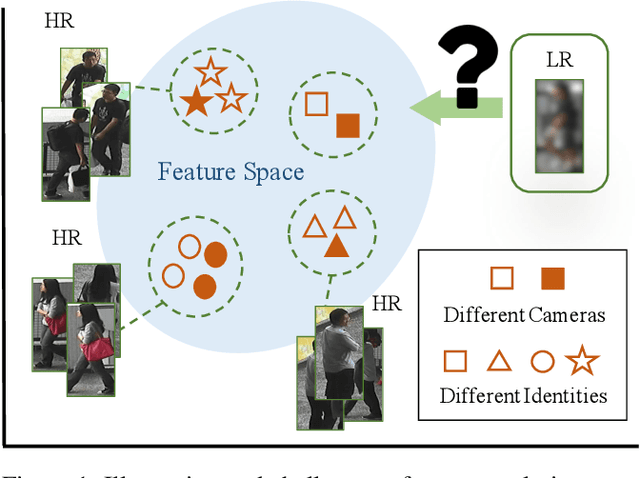
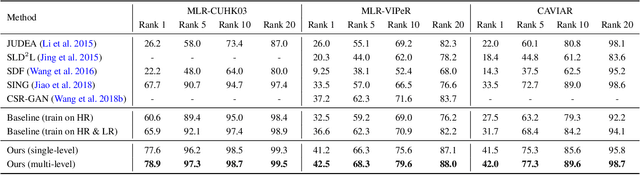
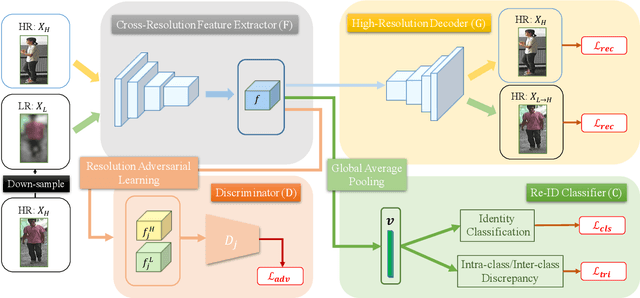
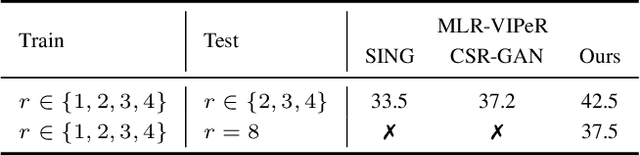
Person re-identification (re-ID) solves the task of matching images across cameras and is among the research topics in vision community. Since query images in real-world scenarios might suffer from resolution loss, how to solve the resolution mismatch problem during person re-ID becomes a practical problem. Instead of applying separate image super-resolution models, we propose a novel network architecture of Resolution Adaptation and re-Identification Network (RAIN) to solve cross-resolution person re-ID. Advancing the strategy of adversarial learning, we aim at extracting resolution-invariant representations for re-ID, while the proposed model is learned in an end-to-end training fashion. Our experiments confirm that the use of our model can recognize low-resolution query images, even if the resolution is not seen during training. Moreover, the extension of our model for semi-supervised re-ID further confirms the scalability of our proposed method for real-world scenarios and applications.
Toward Scale-Invariance and Position-Sensitive Region Proposal Networks
Jul 25, 2018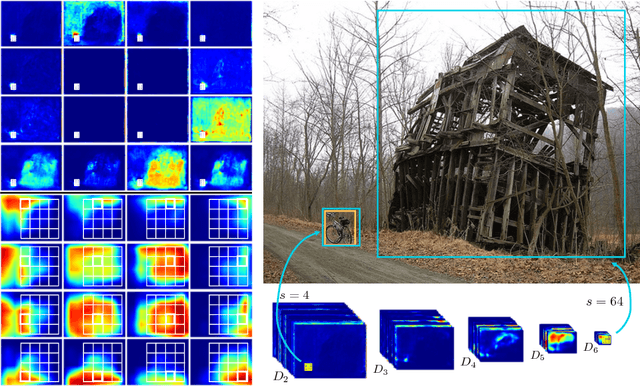
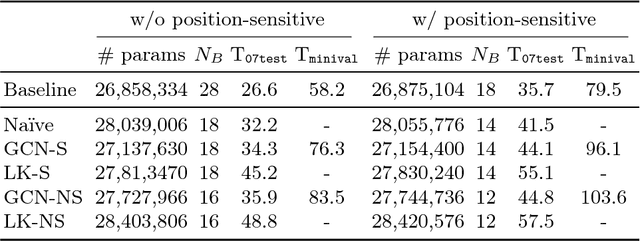

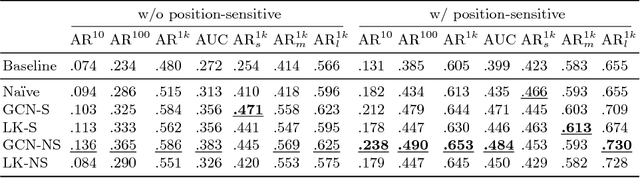
Accurately localising object proposals is an important precondition for high detection rate for the state-of-the-art object detection frameworks. The accuracy of an object detection method has been shown highly related to the average recall (AR) of the proposals. In this work, we propose an advanced object proposal network in favour of translation-invariance for objectness classification, translation-variance for bounding box regression, large effective receptive fields for capturing global context and scale-invariance for dealing with a range of object sizes from extremely small to large. The design of the network architecture aims to be simple while being effective and with real time performance. Without bells and whistles the proposed object proposal network significantly improves the AR at 1,000 proposals by $35\%$ and $45\%$ on PASCAL VOC and COCO dataset respectively and has a fast inference time of 44.8 ms for input image size of $640^{2}$. Empirical studies have also shown that the proposed method is class-agnostic to be generalised for general object proposal.
Comparative evaluation of instrument segmentation and tracking methods in minimally invasive surgery
May 07, 2018
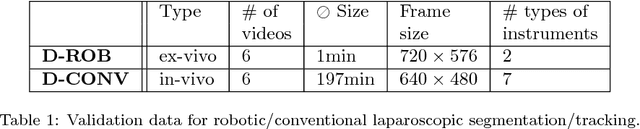

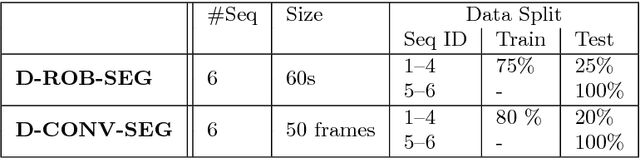
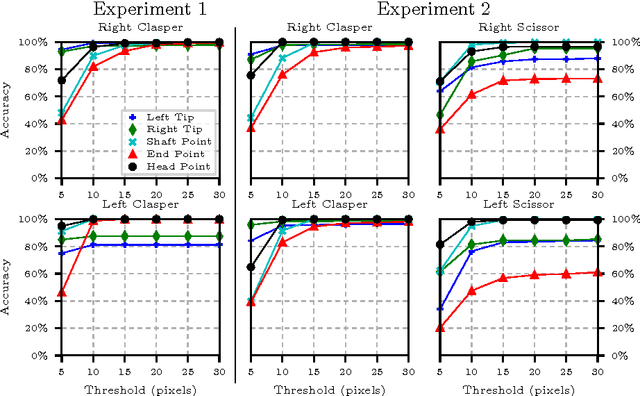
Intraoperative segmentation and tracking of minimally invasive instruments is a prerequisite for computer- and robotic-assisted surgery. Since additional hardware like tracking systems or the robot encoders are cumbersome and lack accuracy, surgical vision is evolving as promising techniques to segment and track the instruments using only the endoscopic images. However, what is missing so far are common image data sets for consistent evaluation and benchmarking of algorithms against each other. The paper presents a comparative validation study of different vision-based methods for instrument segmentation and tracking in the context of robotic as well as conventional laparoscopic surgery. The contribution of the paper is twofold: we introduce a comprehensive validation data set that was provided to the study participants and present the results of the comparative validation study. Based on the results of the validation study, we arrive at the conclusion that modern deep learning approaches outperform other methods in instrument segmentation tasks, but the results are still not perfect. Furthermore, we show that merging results from different methods actually significantly increases accuracy in comparison to the best stand-alone method. On the other hand, the results of the instrument tracking task show that this is still an open challenge, especially during challenging scenarios in conventional laparoscopic surgery.
Adaptation and Re-Identification Network: An Unsupervised Deep Transfer Learning Approach to Person Re-Identification
Apr 25, 2018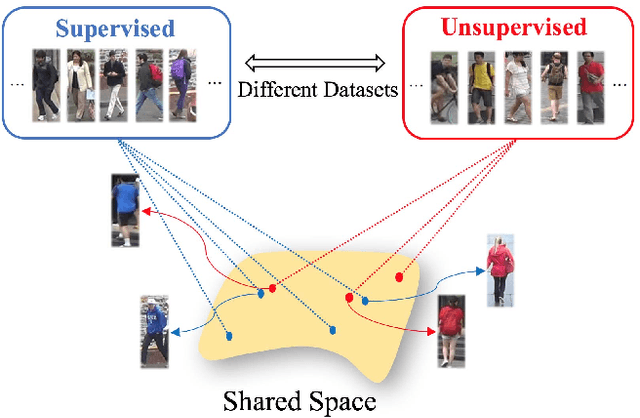

Person re-identification (Re-ID) aims at recognizing the same person from images taken across different cameras. To address this task, one typically requires a large amount labeled data for training an effective Re-ID model, which might not be practical for real-world applications. To alleviate this limitation, we choose to exploit a sufficient amount of pre-existing labeled data from a different (auxiliary) dataset. By jointly considering such an auxiliary dataset and the dataset of interest (but without label information), our proposed adaptation and re-identification network (ARN) performs unsupervised domain adaptation, which leverages information across datasets and derives domain-invariant features for Re-ID purposes. In our experiments, we verify that our network performs favorably against state-of-the-art unsupervised Re-ID approaches, and even outperforms a number of baseline Re-ID methods which require fully supervised data for training.
Automated pick-up of suturing needles for robotic surgical assistance
Apr 09, 2018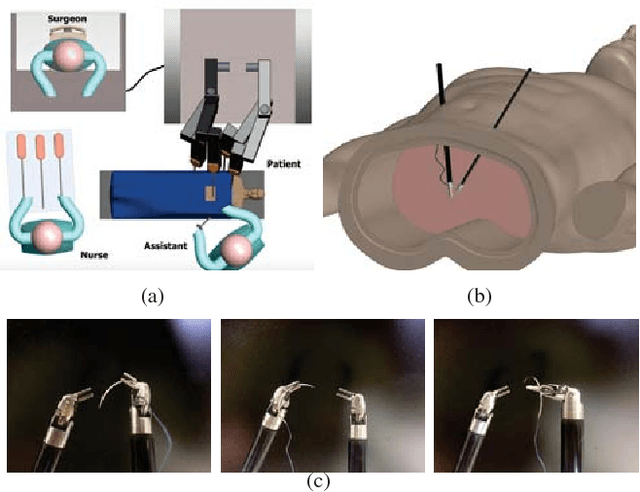
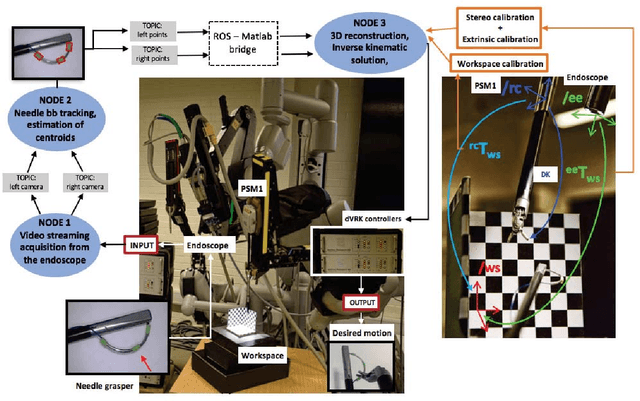
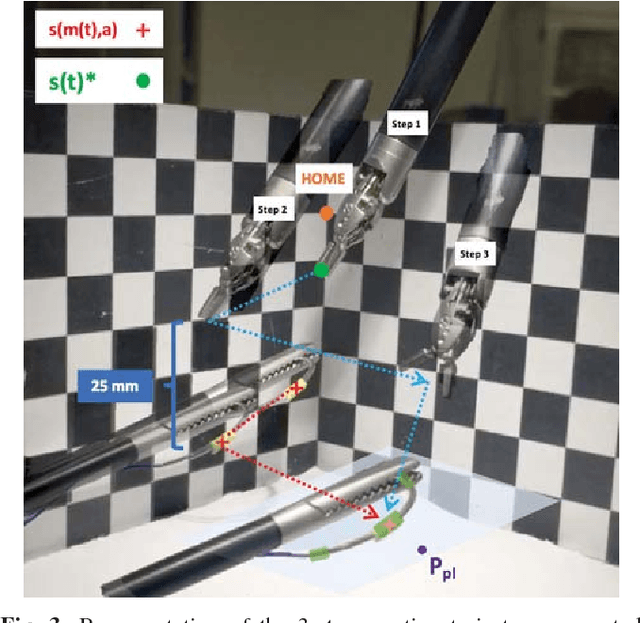

Robot-assisted laparoscopic prostatectomy (RALP) is a treatment for prostate cancer that involves complete or nerve sparing removal prostate tissue that contains cancer. After removal the bladder neck is successively sutured directly with the urethra. The procedure is called urethrovesical anastomosis and is one of the most dexterity demanding tasks during RALP. Two suturing instruments and a pair of needles are used in combination to perform a running stitch during urethrovesical anastomosis. While robotic instruments provide enhanced dexterity to perform the anastomosis, it is still highly challenging and difficult to learn. In this paper, we presents a vision-guided needle grasping method for automatically grasping the needle that has been inserted into the patient prior to anastomosis. We aim to automatically grasp the suturing needle in a position that avoids hand-offs and immediately enables the start of suturing. The full grasping process can be broken down into: a needle detection algorithm; an approach phase where the surgical tool moves closer to the needle based on visual feedback; and a grasping phase through path planning based on observed surgical practice. Our experimental results show examples of successful autonomous grasping that has the potential to simplify and decrease the operational time in RALP by assisting a small component of urethrovesical anastomosis.
Simultaneous Recognition and Pose Estimation of Instruments in Minimally Invasive Surgery
Oct 18, 2017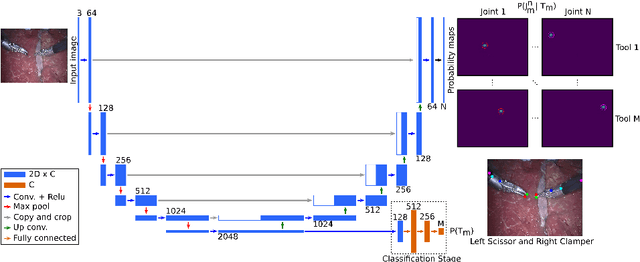
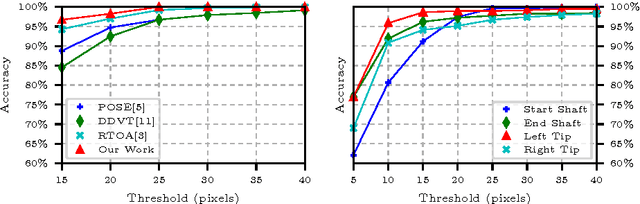
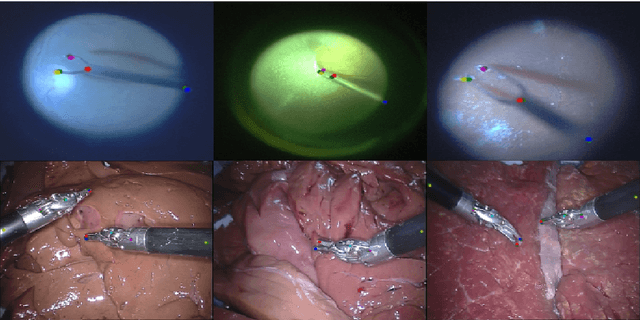
Detection of surgical instruments plays a key role in ensuring patient safety in minimally invasive surgery. In this paper, we present a novel method for 2D vision-based recognition and pose estimation of surgical instruments that generalizes to different surgical applications. At its core, we propose a novel scene model in order to simultaneously recognize multiple instruments as well as their parts. We use a Convolutional Neural Network architecture to embody our model and show that the cross-entropy loss is well suited to optimize its parameters which can be trained in an end-to-end fashion. An additional advantage of our approach is that instrument detection at test time is achieved while avoiding the need for scale-dependent sliding window evaluation. This allows our approach to be relatively parameter free at test time and shows good performance for both instrument detection and tracking. We show that our approach surpasses state-of-the-art results on in-vivo retinal microsurgery image data, as well as ex-vivo laparoscopic sequences.
Patch-based adaptive weighting with segmentation and scale (PAWSS) for visual tracking
Aug 03, 2017



Tracking-by-detection algorithms are widely used for visual tracking, where the problem is treated as a classification task where an object model is updated over time using online learning techniques. In challenging conditions where an object undergoes deformation or scale variations, the update step is prone to include background information in the model appearance or to lack the ability to estimate the scale change, which degrades the performance of the classifier. In this paper, we incorporate a Patch-based Adaptive Weighting with Segmentation and Scale (PAWSS) tracking framework that tackles both the scale and background problems. A simple but effective colour-based segmentation model is used to suppress background information and multi-scale samples are extracted to enrich the training pool, which allows the tracker to handle both incremental and abrupt scale variations between frames. Experimentally, we evaluate our approach on the online tracking benchmark (OTB) dataset and Visual Object Tracking (VOT) challenge datasets. The results show that our approach outperforms recent state-of-the-art trackers, and it especially improves the successful rate score on the OTB dataset, while on the VOT datasets, PAWSS ranks among the top trackers while operating at real-time frame rates.
Fast Estimation of Haemoglobin Concentration in Tissue Via Wavelet Decomposition
Jun 22, 2017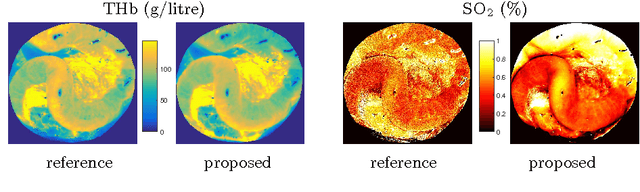
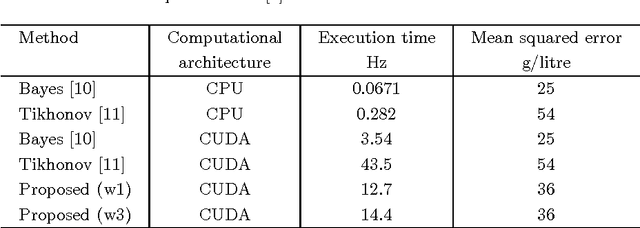
Tissue oxygenation and perfusion can be an indicator for organ viability during minimally invasive surgery, for example allowing real-time assessment of tissue perfusion and oxygen saturation. Multispectral imaging is an optical modality that can inspect tissue perfusion in wide field images without contact. In this paper, we present a novel, fast method for using RGB images for MSI, which while limiting the spectral resolution of the modality allows normal laparoscopic systems to be used. We exploit the discrete Haar decomposition to separate individual video frames into low pass and directional coefficients and we utilise a different multispectral estimation technique on each. The increase in speed is achieved by using fast Tikhonov regularisation on the directional coefficients and more accurate Bayesian estimation on the low pass component. The pipeline is implemented using a graphics processing unit (GPU) architecture and achieves a frame rate of approximately 15Hz. We validate the method on animal models and on human data captured using a da Vinci stereo laparoscope.