 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Response to Neoadjuvant Chemotherapy in Ovarian Cancer from CT Baseline Using Multi-Loss Deep Learning
May 14, 2026Ovarian cancer is the most lethal gynecologic malignancy: around 60% of patients are diagnosed at an advanced stage, with an associated 5-year survival rate of about 30%. Early identification of non-responders to neoadjuvant chemotherapy remains a key unmet need, as it could prevent ineffective therapy and avoid delays in optimal surgical management. This work proposes a non-invasive deep learning framework to predict neoadjuvant chemotherapy response from pre-treatment contrast-enhanced CT by leveraging automatically derived 3D lesion masks. The approach encodes axial slices with a partially fine-tuned pretrained image encoder and aggregates slice-level representations into a volumetric embedding through an attention-based module. Training combines classification loss with supervised contrastive regularization and hard-negative mining to improve separation between ambiguous responders and non-responders. The method was developed on a retrospective single-center cohort from the European Institute of Oncology (Milan, IT), including 280 eligible patients (147 responder, 133 non-responder). On the test cohort, the model achieved a ROC-AUC of 0.73 (95% CI: 0.58-0.86) and an F1-score of 0.70 (95% CI: 0.56-0.82). Overall, these results suggest that the proposed architecture learns clinically relevant predictive patterns and provides a robust foundation for an imaging-based stratification tool.
Vision Transformers for Preoperative CT-Based Prediction of Histopathologic Chemotherapy Response Score in High-Grade Serous Ovarian Carcinoma
Apr 10, 2026Purpose. High-grade serous ovarian carcinoma (HGSOC) is characterized by pronounced biological and spatial heterogeneity and is frequently diagnosed at an advanced stage. Neoadjuvant chemotherapy (NACT) followed by delayed primary surgery is commonly employed in patients unsuitable for primary cytoreduction. The Chemotherapy Response Score (CRS) is a validated histopathological biomarker of response to NACT, but it is only available postoperatively. In this study, we investigate whether pre-treatment computed tomography (CT) imaging and clinical data can be used to predict CRS as an investigational decision-support adjunct to inform multidisciplinary team (MDT) discussions regarding expected treatment response. Methods. We proposed a 2.5D multimodal deep learning framework that processes lesion-dense omental slices using a pre-trained Vision Transformer encoder and integrates the resulting visual representations with clinical variables through an intermediate fusion module to predict CRS. Results. Our multimodal model, integrating imaging and clinical data, achieved a ROC-AUC of 0.95 alongside 95% accuracy and 80% precision on the internal test cohort (IEO, n=41 patients). On the external test set (OV04, n=70 patients), it achieved a ROC-AUC of 0.68, alongside 67% accuracy and 75% precision. Conclusion. These preliminary results demonstrate the feasibility of transformer-based deep learning for preoperative prediction of CRS in HGSOC using routine clinical data and CT imaging. As an investigational, pre-treatment decision-support tool, this approach may assist MDT discussions by providing early, non-invasive estimates of treatment response.
Adapting Foundation Models for Annotation-Efficient Adnexal Mass Segmentation in Cine Images
Apr 09, 2026Adnexal mass evaluation via ultrasound is a challenging clinical task, often hindered by subjective interpretation and significant inter-observer variability. While automated segmentation is a foundational step for quantitative risk assessment, traditional fully supervised convolutional architectures frequently require large amounts of pixel-level annotations and struggle with domain shifts common in medical imaging. In this work, we propose a label-efficient segmentation framework that leverages the robust semantic priors of a pretrained DINOv3 foundational vision transformer backbone. By integrating this backbone with a Dense Prediction Transformer (DPT)-style decoder, our model hierarchically reassembles multi-scale features to combine global semantic representations with fine-grained spatial details. Evaluated on a clinical dataset of 7,777 annotated frames from 112 patients, our method achieves state-of-the-art performance compared to established fully supervised baselines, including U-Net, U-Net++, DeepLabV3, and MAnet. Specifically, we obtain a Dice score of 0.945 and improved boundary adherence, reducing the 95th-percentile Hausdorff Distance by 11.4% relative to the strongest convolutional baseline. Furthermore, we conduct an extensive efficiency analysis demonstrating that our DINOv3-based approach retains significantly higher performance under data starvation regimes, maintaining strong results even when trained on only 25% of the data. These results suggest that leveraging large-scale self-supervised foundations provides a promising and data-efficient solution for medical image segmentation in data-constrained clinical environments. Project Repository: https://github.com/FrancescaFati/MESA
Off-Axis Compliant RCM Joint with Near-Isotropic Stiffness and Minimal Parasitic Error
Mar 30, 2026This paper presents an off-axis, monolithic compliant Remote Center of Motion (RCM) joint for neuroendoscopic manipulation, combining near-isotropic stiffness with minimal parasitic motion. Based on the Tetra II concept, the end-effector is placed outside the tetrahedral flexure to improve line of sight, facilitate sterilization, and allow rapid tool release. Design proceeds in two stages: mobility panels are sized with a compliance-based isotropy objective, then constraining panels are synthesized through finite-element feasibility exploration to trade stiffness isotropy against RCM drift. The joint is modeled with beam elements and validated via detailed finite-element analyses, including fatigue-bounded stress constraints. A PA12 prototype is fabricated by selective laser sintering and characterized on a benchtop: a 2 N radial load is applied at the end-effector while a 6-DOF electromagnetic sensor records pose. The selected configuration produces a stiffness-ellipse principal axis ratio (PAR) of 1.37 and a parasitic-to-useful rotation ratio (PRR) of 0.63%. Under a 4.5° commanded rotation, the predicted RCM drift remains sub-millimetric (0.015-0.172 mm). Fatigue analysis predicts a usable rotational workspace of 12.1°-34.4° depending on direction. Experiments reproduce the simulated directional stiffness trend with typical deviations of 6-30%, demonstrating a compact, fabrication-ready RCM module for constrained surgical access.
TemporalDoRA: Temporal PEFT for Robust Surgical Video Question Answering
Mar 10, 2026Surgical Video Question Answering (VideoQA) requires accurate temporal grounding while remaining robust to natural variation in how clinicians phrase questions, where linguistic bias can arise. Standard Parameter Efficient Fine Tuning (PEFT) methods adapt pretrained projections without explicitly modeling frame-to-frame interactions within the adaptation pathway, limiting their ability to exploit sparse temporal evidence. We introduce TemporalDoRA, a video-specific PEFT formulation that extends Weight-Decomposed Low-Rank Adaptation by (i) inserting lightweight temporal Multi-Head Attention (MHA) inside the low-rank bottleneck of the vision encoder and (ii) selectively applying weight decomposition only to the trainable low-rank branch rather than the full adapted weight. This design enables temporally-aware updates while preserving a frozen backbone and stable scaling. By mixing information across frames within the adaptation subspace, TemporalDoRA steers updates toward temporally consistent visual cues and improves robustness with minimal parameter overhead. To benchmark this setting, we present REAL-Colon-VQA, a colonoscopy VideoQA dataset with 6,424 clip--question pairs, including paired rephrased Out-of-Template questions to evaluate sensitivity to linguistic variation. TemporalDoRA improves Out-of-Template performance, and ablation studies confirm that temporal mixing inside the low-rank branch is the primary driver of these gains. We also validate on EndoVis18-VQA adapted to short clips and observe consistent improvements on the Out-of-Template split. Code and dataset available at~\href{https://anonymous.4open.science/r/TemporalDoRA-BFC8/}{Anonymous GitHub}.
RealSynCol: a high-fidelity synthetic colon dataset for 3D reconstruction applications
Feb 09, 2026Deep learning has the potential to improve colonoscopy by enabling 3D reconstruction of the colon, providing a comprehensive view of mucosal surfaces and lesions, and facilitating the identification of unexplored areas. However, the development of robust methods is limited by the scarcity of large-scale ground truth data. We propose RealSynCol, a highly realistic synthetic dataset designed to replicate the endoscopic environment. Colon geometries extracted from 10 CT scans were imported into a virtual environment that closely mimics intraoperative conditions and rendered with realistic vascular textures. The resulting dataset comprises 28\,130 frames, paired with ground truth depth maps, optical flow, 3D meshes, and camera trajectories. A benchmark study was conducted to evaluate the available synthetic colon datasets for the tasks of depth and pose estimation. Results demonstrate that the high realism and variability of RealSynCol significantly enhance generalization performance on clinical images, proving it to be a powerful tool for developing deep learning algorithms to support endoscopic diagnosis.
UnReflectAnything: RGB-Only Highlight Removal by Rendering Synthetic Specular Supervision
Dec 11, 2025Specular highlights distort appearance, obscure texture, and hinder geometric reasoning in both natural and surgical imagery. We present UnReflectAnything, an RGB-only framework that removes highlights from a single image by predicting a highlight map together with a reflection-free diffuse reconstruction. The model uses a frozen vision transformer encoder to extract multi-scale features, a lightweight head to localize specular regions, and a token-level inpainting module that restores corrupted feature patches before producing the final diffuse image. To overcome the lack of paired supervision, we introduce a Virtual Highlight Synthesis pipeline that renders physically plausible specularities using monocular geometry, Fresnel-aware shading, and randomized lighting which enables training on arbitrary RGB images with correct geometric structure. UnReflectAnything generalizes across natural and surgical domains where non-Lambertian surfaces and non-uniform lighting create severe highlights and it achieves competitive performance with state-of-the-art results on several benchmarks. Project Page: https://alberto-rota.github.io/UnReflectAnything/
Self-Supervised Contrastive Embedding Adaptation for Endoscopic Image Matching
Dec 11, 2025
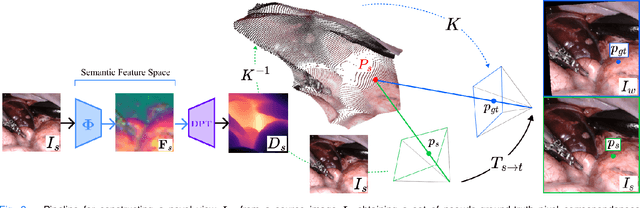


Accurate spatial understanding is essential for image-guided surgery, augmented reality integration and context awareness. In minimally invasive procedures, where visual input is the sole intraoperative modality, establishing precise pixel-level correspondences between endoscopic frames is critical for 3D reconstruction, camera tracking, and scene interpretation. However, the surgical domain presents distinct challenges: weak perspective cues, non-Lambertian tissue reflections, and complex, deformable anatomy degrade the performance of conventional computer vision techniques. While Deep Learning models have shown strong performance in natural scenes, their features are not inherently suited for fine-grained matching in surgical images and require targeted adaptation to meet the demands of this domain. This research presents a novel Deep Learning pipeline for establishing feature correspondences in endoscopic image pairs, alongside a self-supervised optimization framework for model training. The proposed methodology leverages a novel-view synthesis pipeline to generate ground-truth inlier correspondences, subsequently utilized for mining triplets within a contrastive learning paradigm. Through this self-supervised approach, we augment the DINOv2 backbone with an additional Transformer layer, specifically optimized to produce embeddings that facilitate direct matching through cosine similarity thresholding. Experimental evaluation demonstrates that our pipeline surpasses state-of-the-art methodologies on the SCARED datasets improved matching precision and lower epipolar error compared to the related work. The proposed framework constitutes a valuable contribution toward enabling more accurate high-level computer vision applications in surgical endoscopy.
Physiological Measures of the Mental Workload in Users of a Lower Limb Exosuit: A Comparison of Subjective and Objective Metrics
Nov 14, 2025Lower-limb exosuits are particularly relevant for individuals with some degree of mobility impairment, such as post-stroke patients or older adults with reduced movement capabilities. This study aims to investigate the mental workload (MWL) assessment of XoSoft, a lower-limb soft exoskeleton, using and comparing subjective and objective physiological metrics. The NASA-TLX questionnaire, the average percentage change in pupil size (APCPS), and the Baevsky stress index (SI) are compared. The experiments were conducted on 18 healthy subjects while walking and involved mathematical tasks to create a double-task condition. The results show a complex interaction between task difficulty, exoskeleton activation, and pupillary dynamics, suggesting that the subject might reach a saturated condition under a high mental load. Besides, the data indicate that pupil diameter may be an objective mental workload indicator that correlates with subjective NASA-TLX questionnaires. The discordant indications from the stress index suggest how different metrics of the ocular and cardiac levels respond differently to various stimuli and dynamics. Research has also revealed ocular asymmetry, with the right eye more sensitive to cognitive load.
Impact of a Lower Limb Exosuit Anchor Points on Energetics and Biomechanics
Jul 31, 2025Anchor point placement is a crucial yet often overlooked aspect of exosuit design since it determines how forces interact with the human body. This work analyzes the impact of different anchor point positions on gait kinematics, muscular activation and energetic consumption. A total of six experiments were conducted with 11 subjects wearing the XoSoft exosuit, which assists hip flexion in five configurations. Subjects were instrumented with an IMU-based motion tracking system, EMG sensors, and a mask to measure metabolic consumption. The results show that positioning the knee anchor point on the posterior side while keeping the hip anchor on the anterior part can reduce muscle activation in the hip flexors by up to 10.21\% and metabolic expenditure by up to 18.45\%. Even if the only assisted joint was the hip, all the configurations introduced changes also in the knee and ankle kinematics. Overall, no single configuration was optimal across all subjects, suggesting that a personalized approach is necessary to transmit the assistance forces optimally. These findings emphasize that anchor point position does indeed have a significant impact on exoskeleton effectiveness and efficiency. However, these optimal positions are subject-specific to the exosuit design, and there is a strong need for future work to tailor musculoskeletal models to individual characteristics and validate these results in clinical populations.
* 12 pages, 10 figures