 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmented Reality and Human-Robot Collaboration Framework for Percutaneous Nephrolithotomy
Jan 09, 2024



During Percutaneous Nephrolithotomy (PCNL) operations, the surgeon is required to define the incision point on the patient's back, align the needle to a pre-planned path, and perform puncture operations afterward. The procedure is currently performed manually using ultrasound or fluoroscopy imaging for needle orientation, which, however, implies limited accuracy and low reproducibility. This work incorporates Augmented Reality (AR) visualization with an optical see-through head-mounted display (OST-HMD) and Human-Robot Collaboration (HRC) framework to empower the surgeon's task completion performance. In detail, Eye-to-Hand calibration, system registration, and hologram model registration are performed to realize visual guidance. A Cartesian impedance controller is used to guide the operator during the needle puncture task execution. Experiments are conducted to verify the system performance compared with conventional manual puncture procedures and a 2D monitor-based visualisation interface. The results showed that the proposed framework achieves the lowest median and standard deviation error across all the experimental groups, respectively. Furthermore, the NASA-TLX user evaluation results indicate that the proposed framework requires the lowest workload score for task completion compared to other experimental setups. The proposed framework exhibits significant potential for clinical application in the PCNL task, as it enhances the surgeon's perception capability, facilitates collision-free needle insertion path planning, and minimises errors in task completion.
Towards Safer Robot-Assisted Surgery: A Markerless Augmented Reality Framework
Sep 14, 2023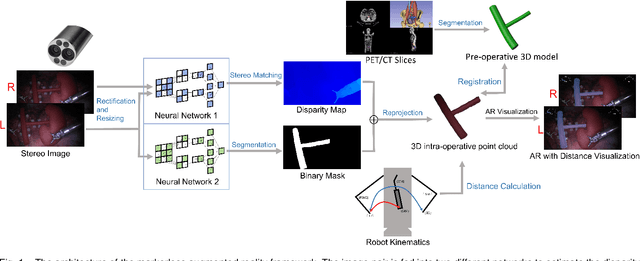

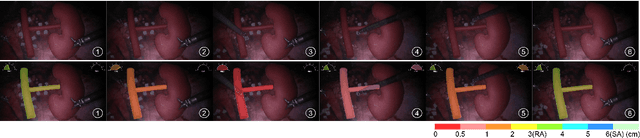
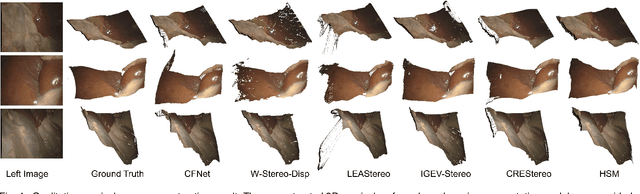
Robot-assisted surgery is rapidly developing in the medical field, and the integration of augmented reality shows the potential of improving the surgeons' operation performance by providing more visual information. In this paper, we proposed a markerless augmented reality framework to enhance safety by avoiding intra-operative bleeding which is a high risk caused by the collision between the surgical instruments and the blood vessel. Advanced stereo reconstruction and segmentation networks are compared to find out the best combination to reconstruct the intra-operative blood vessel in the 3D space for the registration of the pre-operative model, and the minimum distance detection between the instruments and the blood vessel is implemented. A robot-assisted lymphadenectomy is simulated on the da Vinci Research Kit in a dry lab, and ten human subjects performed this operation to explore the usability of the proposed framework. The result shows that the augmented reality framework can help the users to avoid the dangerous collision between the instruments and the blood vessel while not introducing an extra load. It provides a flexible framework that integrates augmented reality into the medical robot platform to enhance safety during the operation.
SAF-IS: a Spatial Annotation Free Framework for Instance Segmentation of Surgical Tools
Sep 04, 2023



Instance segmentation of surgical instruments is a long-standing research problem, crucial for the development of many applications for computer-assisted surgery. This problem is commonly tackled via fully-supervised training of deep learning models, requiring expensive pixel-level annotations to train. In this work, we develop a framework for instance segmentation not relying on spatial annotations for training. Instead, our solution only requires binary tool masks, obtainable using recent unsupervised approaches, and binary tool presence labels, freely obtainable in robot-assisted surgery. Based on the binary mask information, our solution learns to extract individual tool instances from single frames, and to encode each instance into a compact vector representation, capturing its semantic features. Such representations guide the automatic selection of a tiny number of instances (8 only in our experiments), displayed to a human operator for tool-type labelling. The gathered information is finally used to match each training instance with a binary tool presence label, providing an effective supervision signal to train a tool instance classifier. We validate our framework on the EndoVis 2017 and 2018 segmentation datasets. We provide results using binary masks obtained either by manual annotation or as predictions of an unsupervised binary segmentation model. The latter solution yields an instance segmentation approach completely free from spatial annotations, outperforming several state-of-the-art fully-supervised segmentation approaches.
Autonomous Intraluminal Navigation of a Soft Robot using Deep-Learning-based Visual Servoing
Jul 01, 2022

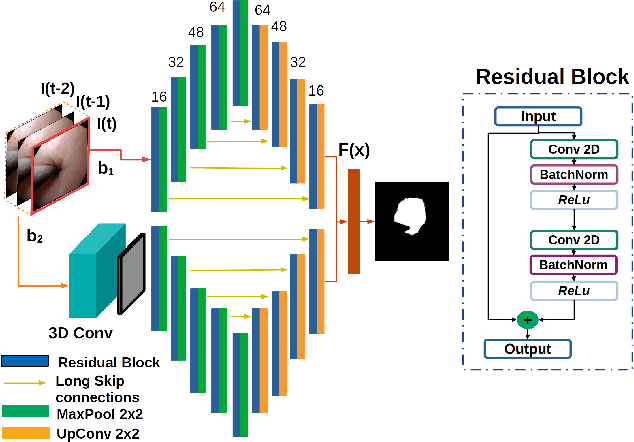
Navigation inside luminal organs is an arduous task that requires non-intuitive coordination between the movement of the operator's hand and the information obtained from the endoscopic video. The development of tools to automate certain tasks could alleviate the physical and mental load of doctors during interventions, allowing them to focus on diagnosis and decision-making tasks. In this paper, we present a synergic solution for intraluminal navigation consisting of a 3D printed endoscopic soft robot that can move safely inside luminal structures. Visual servoing, based on Convolutional Neural Networks (CNNs) is used to achieve the autonomous navigation task. The CNN is trained with phantoms and in-vivo data to segment the lumen, and a model-less approach is presented to control the movement in constrained environments. The proposed robot is validated in anatomical phantoms in different path configurations. We analyze the movement of the robot using different metrics such as task completion time, smoothness, error in the steady-state, and mean and maximum error. We show that our method is suitable to navigate safely in hollow environments and conditions which are different than the ones the network was originally trained on.
FUN-SIS: a Fully UNsupervised approach for Surgical Instrument Segmentation
Feb 16, 2022
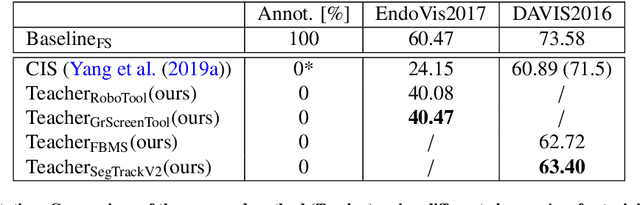

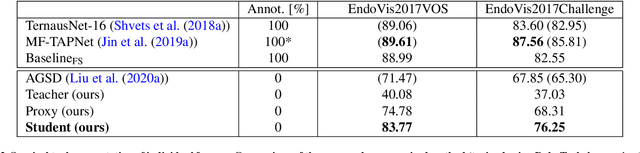
Automatic surgical instrument segmentation of endoscopic images is a crucial building block of many computer-assistance applications for minimally invasive surgery. So far, state-of-the-art approaches completely rely on the availability of a ground-truth supervision signal, obtained via manual annotation, thus expensive to collect at large scale. In this paper, we present FUN-SIS, a Fully-UNsupervised approach for binary Surgical Instrument Segmentation. FUN-SIS trains a per-frame segmentation model on completely unlabelled endoscopic videos, by solely relying on implicit motion information and instrument shape-priors. We define shape-priors as realistic segmentation masks of the instruments, not necessarily coming from the same dataset/domain as the videos. The shape-priors can be collected in various and convenient ways, such as recycling existing annotations from other datasets. We leverage them as part of a novel generative-adversarial approach, allowing to perform unsupervised instrument segmentation of optical-flow images during training. We then use the obtained instrument masks as pseudo-labels in order to train a per-frame segmentation model; to this aim, we develop a learning-from-noisy-labels architecture, designed to extract a clean supervision signal from these pseudo-labels, leveraging their peculiar noise properties. We validate the proposed contributions on three surgical datasets, including the MICCAI 2017 EndoVis Robotic Instrument Segmentation Challenge dataset. The obtained fully-unsupervised results for surgical instrument segmentation are almost on par with the ones of fully-supervised state-of-the-art approaches. This suggests the tremendous potential of the proposed method to leverage the great amount of unlabelled data produced in the context of minimally invasive surgery.
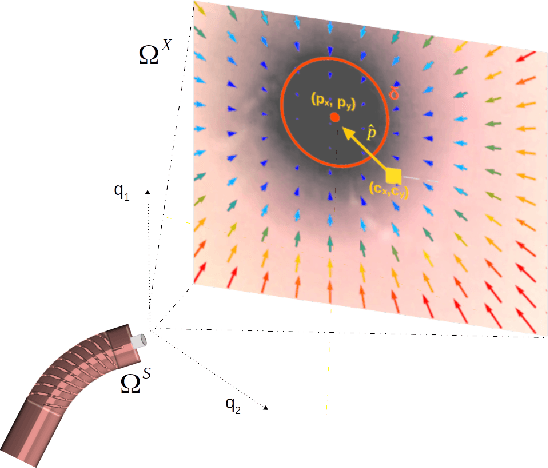
A Kinematic Bottleneck Approach For Pose Regression of Flexible Surgical Instruments directly from Images
Feb 28, 2021
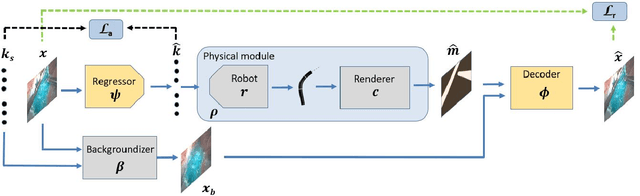

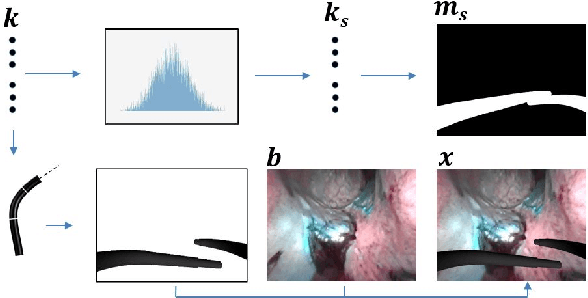
3-D pose estimation of instruments is a crucial step towards automatic scene understanding in robotic minimally invasive surgery. Although robotic systems can potentially directly provide joint values, this information is not commonly exploited inside the operating room, due to its possible unreliability, limited access and the time-consuming calibration required, especially for continuum robots. For this reason, standard approaches for 3-D pose estimation involve the use of external tracking systems. Recently, image-based methods have emerged as promising, non-invasive alternatives. While many image-based approaches in the literature have shown accurate results, they generally require either a complex iterative optimization for each processed image, making them unsuitable for real-time applications, or a large number of manually-annotated images for efficient learning. In this paper we propose a self-supervised image-based method, exploiting, at training time only, the imprecise kinematic information provided by the robot. In order to avoid introducing time-consuming manual annotations, the problem is formulated as an auto-encoder, smartly bottlenecked by the presence of a physical model of the robotic instruments and surgical camera, forcing a separation between image background and kinematic content. Validation of the method was performed on semi-synthetic, phantom and in-vivo datasets, obtained using a flexible robotized endoscope, showing promising results for real-time image-based 3-D pose estimation of surgical instruments.