 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Cell Counting through MLOps: A Structured Approach for Automated Cell Analysis
Apr 28, 2025Machine Learning (ML) models offer significant potential for advancing cell counting applications in neuroscience, medical research, pharmaceutical development, and environmental monitoring. However, implementing these models effectively requires robust operational frameworks. This paper introduces Cell Counting Machine Learning Operations (CC-MLOps), a comprehensive framework that streamlines the integration of ML in cell counting workflows. CC-MLOps encompasses data access and preprocessing, model training, monitoring, explainability features, and sustainability considerations. Through a practical use case, we demonstrate how MLOps principles can enhance model reliability, reduce human error, and enable scalable Cell Counting solutions. This work provides actionable guidance for researchers and laboratory professionals seeking to implement machine learning (ML)- powered cell counting systems.
A Federated Learning Framework for Stenosis Detection
Oct 30, 2023This study explores the use of Federated Learning (FL) for stenosis detection in coronary angiography images (CA). Two heterogeneous datasets from two institutions were considered: Dataset 1 includes 1219 images from 200 patients, which we acquired at the Ospedale Riuniti of Ancona (Italy); Dataset 2 includes 7492 sequential images from 90 patients from a previous study available in the literature. Stenosis detection was performed by using a Faster R-CNN model. In our FL framework, only the weights of the model backbone were shared among the two client institutions, using Federated Averaging (FedAvg) for weight aggregation. We assessed the performance of stenosis detection using Precision (P rec), Recall (Rec), and F1 score (F1). Our results showed that the FL framework does not substantially affects clients 2 performance, which already achieved good performance with local training; for client 1, instead, FL framework increases the performance with respect to local model of +3.76%, +17.21% and +10.80%, respectively, reaching P rec = 73.56, Rec = 67.01 and F1 = 70.13. With such results, we showed that FL may enable multicentric studies relevant to automatic stenosis detection in CA by addressing data heterogeneity from various institutions, while preserving patient privacy.
A store-and-forward cloud-based telemonitoring system for automatic assessing dysarthria evolution in neurological diseases from video-recording analysis
Sep 16, 2023Background and objectives: Patients suffering from neurological diseases may develop dysarthria, a motor speech disorder affecting the execution of speech. Close and quantitative monitoring of dysarthria evolution is crucial for enabling clinicians to promptly implement patient management strategies and maximizing effectiveness and efficiency of communication functions in term of restoring, compensating or adjusting. In the clinical assessment of orofacial structures and functions, at rest condition or during speech and non-speech movements, a qualitative evaluation is usually performed, throughout visual observation. Methods: To overcome limitations posed by qualitative assessments, this work presents a store-and-forward self-service telemonitoring system that integrates, within its cloud architecture, a convolutional neural network (CNN) for analyzing video recordings acquired by individuals with dysarthria. This architecture, called facial landmark Mask RCNN, aims at locating facial landmarks as a prior for assessing the orofacial functions related to speech and examining dysarthria evolution in neurological diseases. Results: When tested on the Toronto NeuroFace dataset, a publicly available annotated dataset of video recordings from patients with amyotrophic lateral sclerosis (ALS) and stroke, the proposed CNN achieved a normalized mean error equal to 1.79 on localizing the facial landmarks. We also tested our system in a real-life scenario on 11 bulbar-onset ALS subjects, obtaining promising outcomes in terms of facial landmark position estimation. Discussion and conclusions: This preliminary study represents a relevant step towards the use of remote tools to support clinicians in monitoring the evolution of dysarthria.
Deep learning-based approaches for human motion decoding in smart walkers for rehabilitation
Jan 13, 2023



Gait disabilities are among the most frequent worldwide. Their treatment relies on rehabilitation therapies, in which smart walkers are being introduced to empower the user's recovery and autonomy, while reducing the clinicians effort. For that, these should be able to decode human motion and needs, as early as possible. Current walkers decode motion intention using information of wearable or embedded sensors, namely inertial units, force and hall sensors, and lasers, whose main limitations imply an expensive solution or hinder the perception of human movement. Smart walkers commonly lack a seamless human-robot interaction, which intuitively understands human motions. A contactless approach is proposed in this work, addressing human motion decoding as an early action recognition/detection problematic, using RGB-D cameras. We studied different deep learning-based algorithms, organised in three different approaches, to process lower body RGB-D video sequences, recorded from an embedded camera of a smart walker, and classify them into 4 classes (stop, walk, turn right/left). A custom dataset involving 15 healthy participants walking with the device was acquired and prepared, resulting in 28800 balanced RGB-D frames, to train and evaluate the deep networks. The best results were attained by a convolutional neural network with a channel attention mechanism, reaching accuracy values of 99.61% and above 93%, for offline early detection/recognition and trial simulations, respectively. Following the hypothesis that human lower body features encode prominent information, fostering a more robust prediction towards real-time applications, the algorithm focus was also evaluated using Dice metric, leading to values slightly higher than 30%. Promising results were attained for early action detection as a human motion decoding strategy, with enhancements in the focus of the proposed architectures.
Learning-Based Keypoint Registration for Fetoscopic Mosaicking
Jul 26, 2022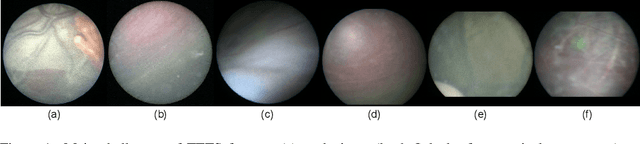
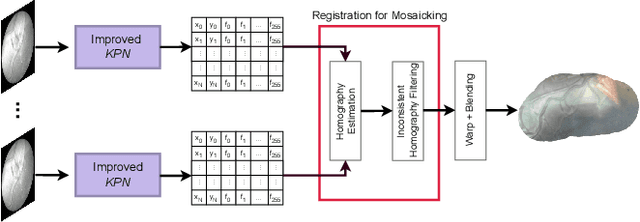

In Twin-to-Twin Transfusion Syndrome (TTTS), abnormal vascular anastomoses in the monochorionic placenta can produce uneven blood flow between the two fetuses. In the current practice, TTTS is treated surgically by closing abnormal anastomoses using laser ablation. This surgery is minimally invasive and relies on fetoscopy. Limited field of view makes anastomosis identification a challenging task for the surgeon. To tackle this challenge, we propose a learning-based framework for in-vivo fetoscopy frame registration for field-of-view expansion. The novelties of this framework relies on a learning-based keypoint proposal network and an encoding strategy to filter (i) irrelevant keypoints based on fetoscopic image segmentation and (ii) inconsistent homographies. We validate of our framework on a dataset of 6 intraoperative sequences from 6 TTTS surgeries from 6 different women against the most recent state of the art algorithm, which relies on the segmentation of placenta vessels. The proposed framework achieves higher performance compared to the state of the art, paving the way for robust mosaicking to provide surgeons with context awareness during TTTS surgery.
Autonomous Intraluminal Navigation of a Soft Robot using Deep-Learning-based Visual Servoing
Jul 01, 2022

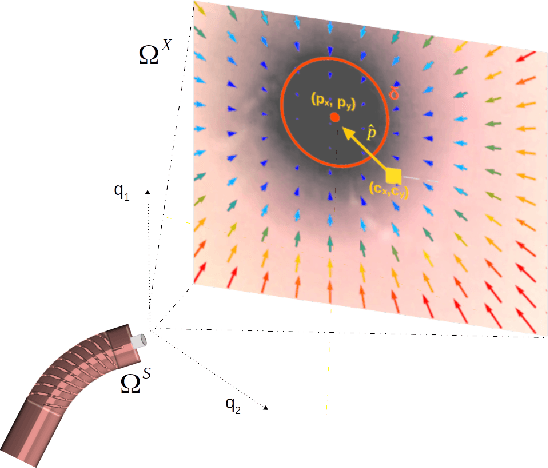
Navigation inside luminal organs is an arduous task that requires non-intuitive coordination between the movement of the operator's hand and the information obtained from the endoscopic video. The development of tools to automate certain tasks could alleviate the physical and mental load of doctors during interventions, allowing them to focus on diagnosis and decision-making tasks. In this paper, we present a synergic solution for intraluminal navigation consisting of a 3D printed endoscopic soft robot that can move safely inside luminal structures. Visual servoing, based on Convolutional Neural Networks (CNNs) is used to achieve the autonomous navigation task. The CNN is trained with phantoms and in-vivo data to segment the lumen, and a model-less approach is presented to control the movement in constrained environments. The proposed robot is validated in anatomical phantoms in different path configurations. We analyze the movement of the robot using different metrics such as task completion time, smoothness, error in the steady-state, and mean and maximum error. We show that our method is suitable to navigate safely in hollow environments and conditions which are different than the ones the network was originally trained on.
FetReg2021: A Challenge on Placental Vessel Segmentation and Registration in Fetoscopy
Jun 30, 2022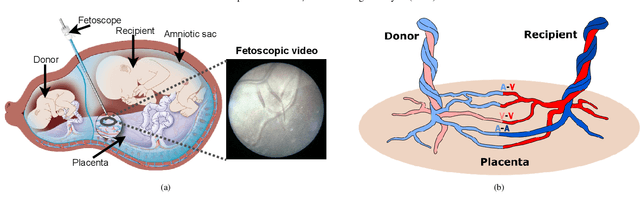
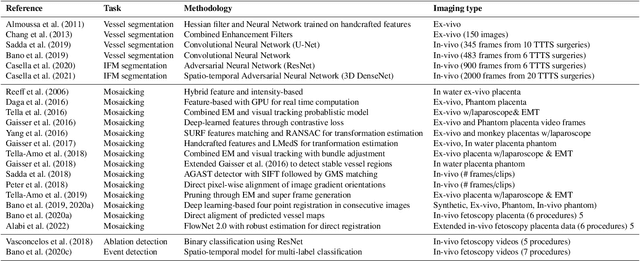
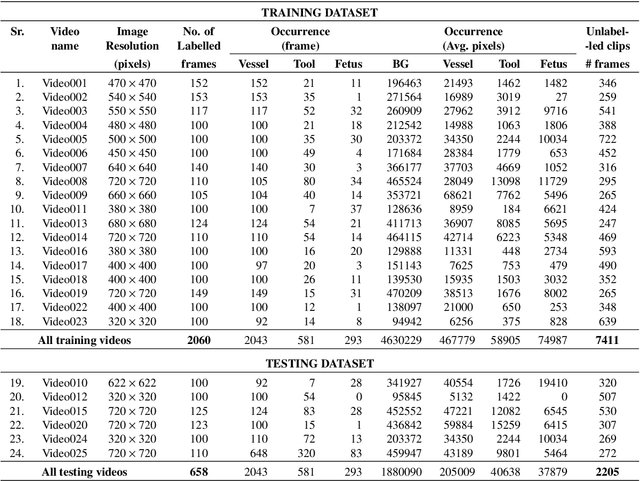
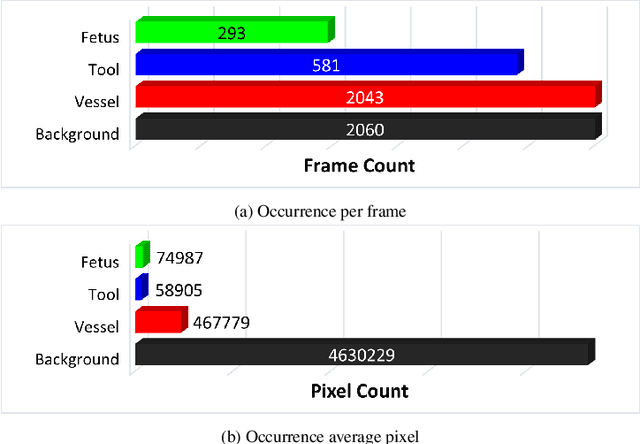
Fetoscopy laser photocoagulation is a widely adopted procedure for treating Twin-to-Twin Transfusion Syndrome (TTTS). The procedure involves photocoagulation pathological anastomoses to regulate blood exchange among twins. The procedure is particularly challenging due to the limited field of view, poor manoeuvrability of the fetoscope, poor visibility, and variability in illumination. These challenges may lead to increased surgery time and incomplete ablation. Computer-assisted intervention (CAI) can provide surgeons with decision support and context awareness by identifying key structures in the scene and expanding the fetoscopic field of view through video mosaicking. Research in this domain has been hampered by the lack of high-quality data to design, develop and test CAI algorithms. Through the Fetoscopic Placental Vessel Segmentation and Registration (FetReg2021) challenge, which was organized as part of the MICCAI2021 Endoscopic Vision challenge, we released the first largescale multicentre TTTS dataset for the development of generalized and robust semantic segmentation and video mosaicking algorithms. For this challenge, we released a dataset of 2060 images, pixel-annotated for vessels, tool, fetus and background classes, from 18 in-vivo TTTS fetoscopy procedures and 18 short video clips. Seven teams participated in this challenge and their model performance was assessed on an unseen test dataset of 658 pixel-annotated images from 6 fetoscopic procedures and 6 short clips. The challenge provided an opportunity for creating generalized solutions for fetoscopic scene understanding and mosaicking. In this paper, we present the findings of the FetReg2021 challenge alongside reporting a detailed literature review for CAI in TTTS fetoscopy. Through this challenge, its analysis and the release of multi-centre fetoscopic data, we provide a benchmark for future research in this field.
A Review on Deep-Learning Algorithms for Fetal Ultrasound-Image Analysis
Jan 28, 2022


Deep-learning (DL) algorithms are becoming the standard for processing ultrasound (US) fetal images. Despite a large number of survey papers already present in this field, most of them are focusing on a broader area of medical-image analysis or not covering all fetal US DL applications. This paper surveys the most recent work in the field, with a total of 145 research papers published after 2017. Each paper is analyzed and commented on from both the methodology and application perspective. We categorized the papers in (i) fetal standard-plane detection, (ii) anatomical-structure analysis, and (iii) biometry parameter estimation. For each category, main limitations and open issues are presented. Summary tables are included to facilitate the comparison among the different approaches. Publicly-available datasets and performance metrics commonly used to assess algorithm performance are summarized, too. This paper ends with a critical summary of the current state of the art on DL algorithms for fetal US image analysis and a discussion on current challenges that have to be tackled by researchers working in the field to translate the research methodology into the actual clinical practice.
Real-Time Human Pose Estimation on a Smart Walker using Convolutional Neural Networks
Jun 28, 2021



Rehabilitation is important to improve quality of life for mobility-impaired patients. Smart walkers are a commonly used solution that should embed automatic and objective tools for data-driven human-in-the-loop control and monitoring. However, present solutions focus on extracting few specific metrics from dedicated sensors with no unified full-body approach. We investigate a general, real-time, full-body pose estimation framework based on two RGB+D camera streams with non-overlapping views mounted on a smart walker equipment used in rehabilitation. Human keypoint estimation is performed using a two-stage neural network framework. The 2D-Stage implements a detection module that locates body keypoints in the 2D image frames. The 3D-Stage implements a regression module that lifts and relates the detected keypoints in both cameras to the 3D space relative to the walker. Model predictions are low-pass filtered to improve temporal consistency. A custom acquisition method was used to obtain a dataset, with 14 healthy subjects, used for training and evaluating the proposed framework offline, which was then deployed on the real walker equipment. An overall keypoint detection error of 3.73 pixels for the 2D-Stage and 44.05mm for the 3D-Stage were reported, with an inference time of 26.6ms when deployed on the constrained hardware of the walker. We present a novel approach to patient monitoring and data-driven human-in-the-loop control in the context of smart walkers. It is able to extract a complete and compact body representation in real-time and from inexpensive sensors, serving as a common base for downstream metrics extraction solutions, and Human-Robot interaction applications. Despite promising results, more data should be collected on users with impairments, to assess its performance as a rehabilitation tool in real-world scenarios.
How can we learn from challenges? A statistical approach to driving future algorithm development
Jun 17, 2021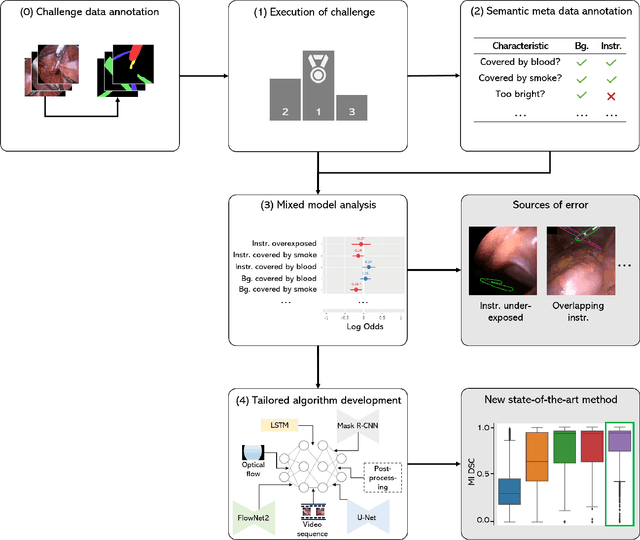


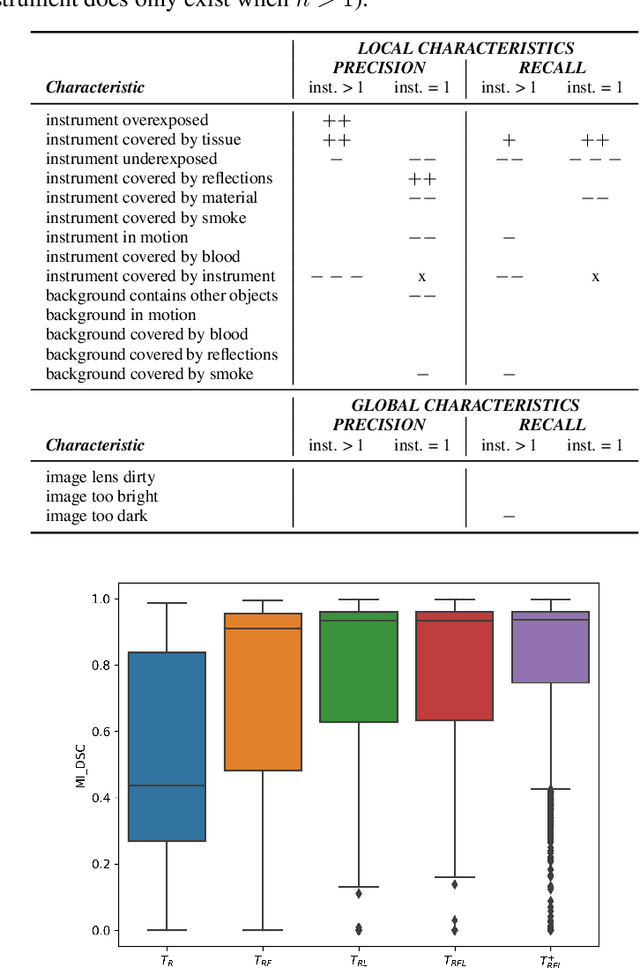
Challenges have become the state-of-the-art approach to benchmark image analysis algorithms in a comparative manner. While the validation on identical data sets was a great step forward, results analysis is often restricted to pure ranking tables, leaving relevant questions unanswered. Specifically, little effort has been put into the systematic investigation on what characterizes images in which state-of-the-art algorithms fail. To address this gap in the literature, we (1) present a statistical framework for learning from challenges and (2) instantiate it for the specific task of instrument instance segmentation in laparoscopic videos. Our framework relies on the semantic meta data annotation of images, which serves as foundation for a General Linear Mixed Models (GLMM) analysis. Based on 51,542 meta data annotations performed on 2,728 images, we applied our approach to the results of the Robust Medical Instrument Segmentation Challenge (ROBUST-MIS) challenge 2019 and revealed underexposure, motion and occlusion of instruments as well as the presence of smoke or other objects in the background as major sources of algorithm failure. Our subsequent method development, tailored to the specific remaining issues, yielded a deep learning model with state-of-the-art overall performance and specific strengths in the processing of images in which previous methods tended to fail. Due to the objectivity and generic applicability of our approach, it could become a valuable tool for validation in the field of medical image analysis and beyond. and segmentation of small, crossing, moving and transparent instrument(s) (parts).