 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedSynthCT-Brain: A Federated Learning Framework for Multi-Institutional Brain MRI-to-CT Synthesis
Dec 09, 2024
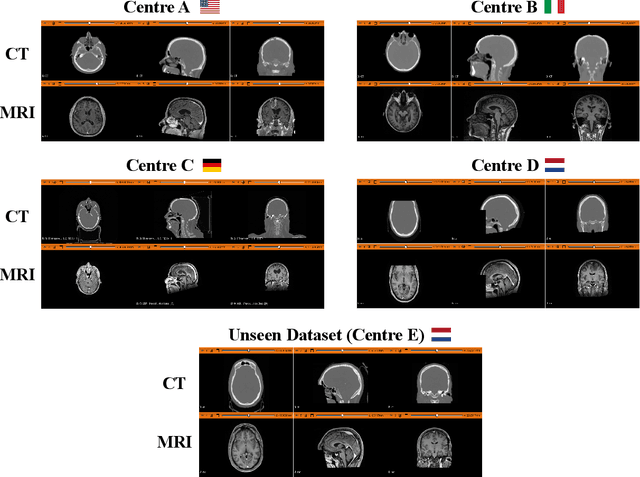
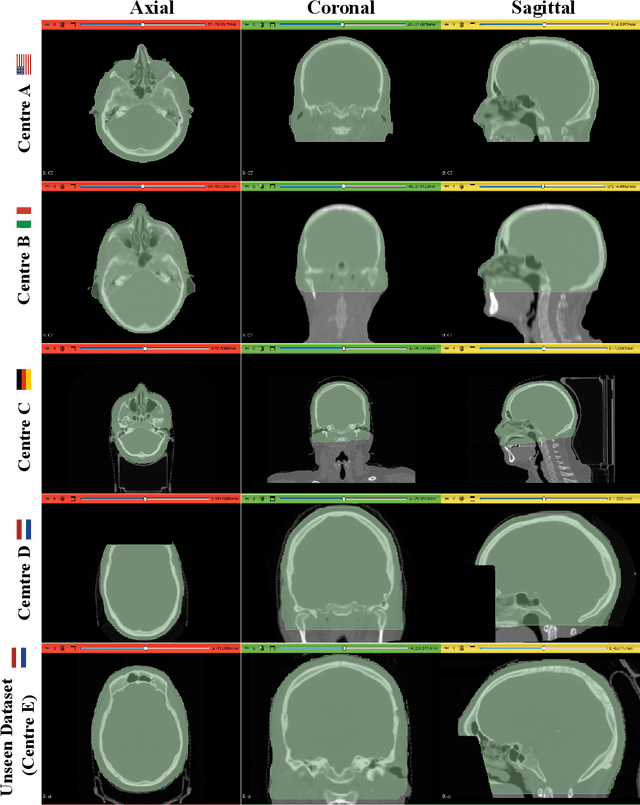

The generation of Synthetic Computed Tomography (sCT) images has become a pivotal methodology in modern clinical practice, particularly in the context of Radiotherapy (RT) treatment planning. The use of sCT enables the calculation of doses, pushing towards Magnetic Resonance Imaging (MRI) guided radiotherapy treatments. Moreover, with the introduction of MRI-Positron Emission Tomography (PET) hybrid scanners, the derivation of sCT from MRI can improve the attenuation correction of PET images. Deep learning methods for MRI-to-sCT have shown promising results, but their reliance on single-centre training dataset limits generalisation capabilities to diverse clinical settings. Moreover, creating centralised multicentre datasets may pose privacy concerns. To solve the issues, this study introduces FedSynthCT-Brain, a framework based on the Federated Learning (FL) paradigm for MRI-to-sCT in brain imaging. We reproduced a federation across four European and American centres using a U-Net-based model. The approach was implemented using data from centres belonging the federation and it was tested on an unseen dataset from a centre outside the federation. In the case of the unseen centre, the federated model achieved a median Mean Absolute Error (MAE) of 102.0 HU across 23 patients, with an interquartile range of 96.7-110.5 HU. The median (interquartile range) for the Structural Similarity Index (SSIM) and the Peak Signal to Noise Ratio (PNSR) were 0.89 (0.86-0.89) and 26.58 (25.52-27.42), respectively. The analysis of the results showed acceptable performances of the federated approach, thus highlighting the potential of FL to enhance MRI-to-sCT to improve generalisability and advancing safe and equitable clinical applications while fostering collaboration and preserving data privacy.
A store-and-forward cloud-based telemonitoring system for automatic assessing dysarthria evolution in neurological diseases from video-recording analysis
Sep 16, 2023Background and objectives: Patients suffering from neurological diseases may develop dysarthria, a motor speech disorder affecting the execution of speech. Close and quantitative monitoring of dysarthria evolution is crucial for enabling clinicians to promptly implement patient management strategies and maximizing effectiveness and efficiency of communication functions in term of restoring, compensating or adjusting. In the clinical assessment of orofacial structures and functions, at rest condition or during speech and non-speech movements, a qualitative evaluation is usually performed, throughout visual observation. Methods: To overcome limitations posed by qualitative assessments, this work presents a store-and-forward self-service telemonitoring system that integrates, within its cloud architecture, a convolutional neural network (CNN) for analyzing video recordings acquired by individuals with dysarthria. This architecture, called facial landmark Mask RCNN, aims at locating facial landmarks as a prior for assessing the orofacial functions related to speech and examining dysarthria evolution in neurological diseases. Results: When tested on the Toronto NeuroFace dataset, a publicly available annotated dataset of video recordings from patients with amyotrophic lateral sclerosis (ALS) and stroke, the proposed CNN achieved a normalized mean error equal to 1.79 on localizing the facial landmarks. We also tested our system in a real-life scenario on 11 bulbar-onset ALS subjects, obtaining promising outcomes in terms of facial landmark position estimation. Discussion and conclusions: This preliminary study represents a relevant step towards the use of remote tools to support clinicians in monitoring the evolution of dysarthria.
Deep learning-based approaches for human motion decoding in smart walkers for rehabilitation
Jan 13, 2023



Gait disabilities are among the most frequent worldwide. Their treatment relies on rehabilitation therapies, in which smart walkers are being introduced to empower the user's recovery and autonomy, while reducing the clinicians effort. For that, these should be able to decode human motion and needs, as early as possible. Current walkers decode motion intention using information of wearable or embedded sensors, namely inertial units, force and hall sensors, and lasers, whose main limitations imply an expensive solution or hinder the perception of human movement. Smart walkers commonly lack a seamless human-robot interaction, which intuitively understands human motions. A contactless approach is proposed in this work, addressing human motion decoding as an early action recognition/detection problematic, using RGB-D cameras. We studied different deep learning-based algorithms, organised in three different approaches, to process lower body RGB-D video sequences, recorded from an embedded camera of a smart walker, and classify them into 4 classes (stop, walk, turn right/left). A custom dataset involving 15 healthy participants walking with the device was acquired and prepared, resulting in 28800 balanced RGB-D frames, to train and evaluate the deep networks. The best results were attained by a convolutional neural network with a channel attention mechanism, reaching accuracy values of 99.61% and above 93%, for offline early detection/recognition and trial simulations, respectively. Following the hypothesis that human lower body features encode prominent information, fostering a more robust prediction towards real-time applications, the algorithm focus was also evaluated using Dice metric, leading to values slightly higher than 30%. Promising results were attained for early action detection as a human motion decoding strategy, with enhancements in the focus of the proposed architectures.
Real-Time Human Pose Estimation on a Smart Walker using Convolutional Neural Networks
Jun 28, 2021



Rehabilitation is important to improve quality of life for mobility-impaired patients. Smart walkers are a commonly used solution that should embed automatic and objective tools for data-driven human-in-the-loop control and monitoring. However, present solutions focus on extracting few specific metrics from dedicated sensors with no unified full-body approach. We investigate a general, real-time, full-body pose estimation framework based on two RGB+D camera streams with non-overlapping views mounted on a smart walker equipment used in rehabilitation. Human keypoint estimation is performed using a two-stage neural network framework. The 2D-Stage implements a detection module that locates body keypoints in the 2D image frames. The 3D-Stage implements a regression module that lifts and relates the detected keypoints in both cameras to the 3D space relative to the walker. Model predictions are low-pass filtered to improve temporal consistency. A custom acquisition method was used to obtain a dataset, with 14 healthy subjects, used for training and evaluating the proposed framework offline, which was then deployed on the real walker equipment. An overall keypoint detection error of 3.73 pixels for the 2D-Stage and 44.05mm for the 3D-Stage were reported, with an inference time of 26.6ms when deployed on the constrained hardware of the walker. We present a novel approach to patient monitoring and data-driven human-in-the-loop control in the context of smart walkers. It is able to extract a complete and compact body representation in real-time and from inexpensive sensors, serving as a common base for downstream metrics extraction solutions, and Human-Robot interaction applications. Despite promising results, more data should be collected on users with impairments, to assess its performance as a rehabilitation tool in real-world scenarios.
Preterm infants' pose estimation with spatio-temporal features
May 08, 2020

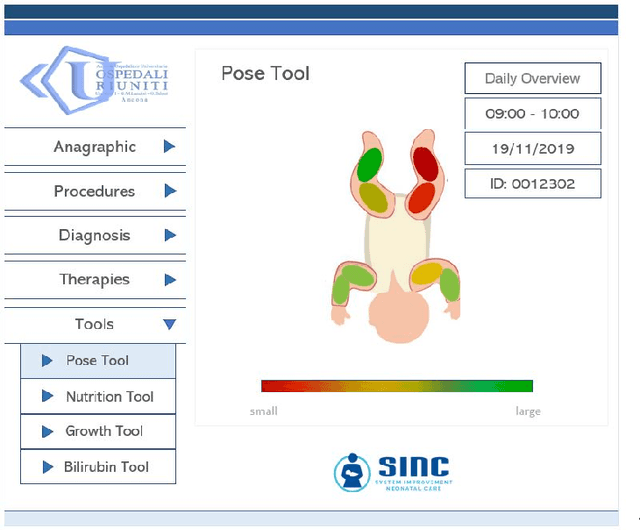

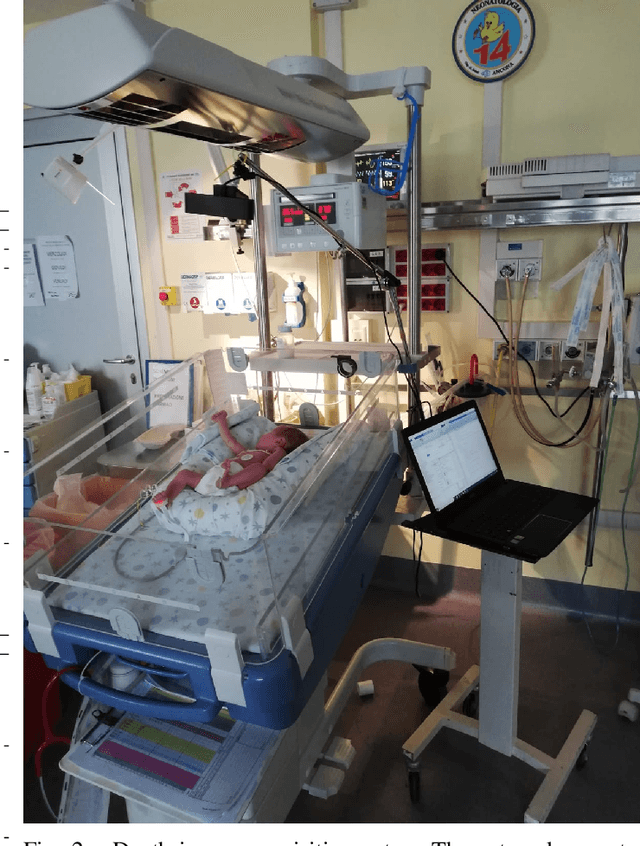
Objective: Preterm infants' limb monitoring in neonatal intensive care units (NICUs) is of primary importance for assessing infants' health status and motor/cognitive development. Herein, we propose a new approach to preterm infants' limb pose estimation that features spatio-temporal information to detect and track limb joints from depth videos with high reliability. Methods: Limb-pose estimation is performed using a deep-learning framework consisting of a detection and a regression convolutional neural network (CNN) for rough and precise joint localization, respectively. The CNNs are implemented to encode connectivity in the temporal direction through 3D convolution. Assessment of the proposed framework is performed through a comprehensive study with sixteen depth videos acquired in the actual clinical practice from sixteen preterm infants (the babyPose dataset). Results: When applied to pose estimation, the median root mean squared distance, computed among all limbs, between the estimated and the ground-truth pose was 9.06 pixels, overcoming approaches based on spatial features only (11.27pixels). Conclusion: Results showed that the spatio-temporal features had a significant influence on the pose-estimation performance, especially in challenging cases (e.g., homogeneous image intensity). Significance: This paper significantly enhances the state of art in automatic assessment of preterm infants' health status by introducing the use of spatio-temporal features for limb detection and tracking, and by being the first study to use depth videos acquired in the actual clinical practice for limb-pose estimation. The babyPose dataset has been released as the first annotated dataset for infants' pose estimation.
Preterm infants' limb-pose estimation from depth images using convolutional neural networks
Jul 26, 2019


Preterm infants' limb-pose estimation is a crucial but challenging task, which may improve patients' care and facilitate clinicians in infant's movements monitoring. Work in the literature either provides approaches to whole-body segmentation and tracking, which, however, has poor clinical value, or retrieve a posteriori limb pose from limb segmentation, increasing computational costs and introducing inaccuracy sources. In this paper, we address the problem of limb-pose estimation under a different point of view. We proposed a 2D fully-convolutional neural network for roughly detecting limb joints and joint connections, followed by a regression convolutional neural network for accurate joint and joint-connection position estimation. Joints from the same limb are then connected with a maximum bipartite matching approach. Our analysis does not require any prior modeling of infants' body structure, neither any manual interventions. For developing and testing the proposed approach, we built a dataset of four videos (video length = 90 s) recorded with a depth sensor in a neonatal intensive care unit (NICU) during the actual clinical practice, achieving median root mean square distance [pixels] of 10.790 (right arm), 10.542 (left arm), 8.294 (right leg), 11.270 (left leg) with respect to the ground-truth limb pose. The idea of estimating limb pose directly from depth images may represent a future paradigm for addressing the problem of preterm-infants' movement monitoring and offer all possible support to clinicians in NICUs.