 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDELICATE: Diachronic Entity LInking using Classes And Temporal Evidence
Nov 13, 2025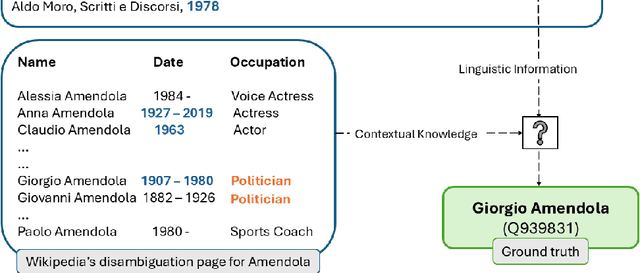

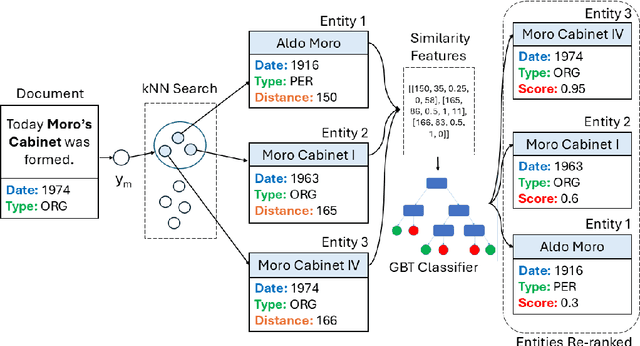
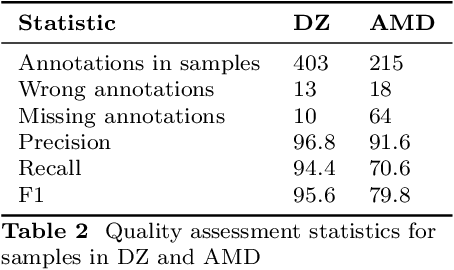
In spite of the remarkable advancements in the field of Natural Language Processing, the task of Entity Linking (EL) remains challenging in the field of humanities due to complex document typologies, lack of domain-specific datasets and models, and long-tail entities, i.e., entities under-represented in Knowledge Bases (KBs). The goal of this paper is to address these issues with two main contributions. The first contribution is DELICATE, a novel neuro-symbolic method for EL on historical Italian which combines a BERT-based encoder with contextual information from Wikidata to select appropriate KB entities using temporal plausibility and entity type consistency. The second contribution is ENEIDE, a multi-domain EL corpus in historical Italian semi-automatically extracted from two annotated editions spanning from the 19th to the 20th century and including literary and political texts. Results show how DELICATE outperforms other EL models in historical Italian even if compared with larger architectures with billions of parameters. Moreover, further analyses reveal how DELICATE confidence scores and features sensitivity provide results which are more explainable and interpretable than purely neural methods.
Empathic Prompting: Non-Verbal Context Integration for Multimodal LLM Conversations
Oct 23, 2025We present Empathic Prompting, a novel framework for multimodal human-AI interaction that enriches Large Language Model (LLM) conversations with implicit non-verbal context. The system integrates a commercial facial expression recognition service to capture users' emotional cues and embeds them as contextual signals during prompting. Unlike traditional multimodal interfaces, empathic prompting requires no explicit user control; instead, it unobtrusively augments textual input with affective information for conversational and smoothness alignment. The architecture is modular and scalable, allowing integration of additional non-verbal modules. We describe the system design, implemented through a locally deployed DeepSeek instance, and report a preliminary service and usability evaluation (N=5). Results show consistent integration of non-verbal input into coherent LLM outputs, with participants highlighting conversational fluidity. Beyond this proof of concept, empathic prompting points to applications in chatbot-mediated communication, particularly in domains like healthcare or education, where users' emotional signals are critical yet often opaque in verbal exchanges.
Deep Learning Models for Robust Facial Liveness Detection
Aug 12, 2025In the rapidly evolving landscape of digital security, biometric authentication systems, particularly facial recognition, have emerged as integral components of various security protocols. However, the reliability of these systems is compromised by sophisticated spoofing attacks, where imposters gain unauthorized access by falsifying biometric traits. Current literature reveals a concerning gap: existing liveness detection methodologies - designed to counteract these breaches - fall short against advanced spoofing tactics employing deepfakes and other artificial intelligence-driven manipulations. This study introduces a robust solution through novel deep learning models addressing the deficiencies in contemporary anti-spoofing techniques. By innovatively integrating texture analysis and reflective properties associated with genuine human traits, our models distinguish authentic presence from replicas with remarkable precision. Extensive evaluations were conducted across five diverse datasets, encompassing a wide range of attack vectors and environmental conditions. Results demonstrate substantial advancement over existing systems, with our best model (AttackNet V2.2) achieving 99.9% average accuracy when trained on combined data. Moreover, our research unveils critical insights into the behavioral patterns of impostor attacks, contributing to a more nuanced understanding of their evolving nature. The implications are profound: our models do not merely fortify the authentication processes but also instill confidence in biometric systems across various sectors reliant on secure access.
Named Entity Recognition in Historical Italian: The Case of Giacomo Leopardi's Zibaldone
May 26, 2025The increased digitization of world's textual heritage poses significant challenges for both computer science and literary studies. Overall, there is an urgent need of computational techniques able to adapt to the challenges of historical texts, such as orthographic and spelling variations, fragmentary structure and digitization errors. The rise of large language models (LLMs) has revolutionized natural language processing, suggesting promising applications for Named Entity Recognition (NER) on historical documents. In spite of this, no thorough evaluation has been proposed for Italian texts. This research tries to fill the gap by proposing a new challenging dataset for entity extraction based on a corpus of 19th century scholarly notes, i.e. Giacomo Leopardi's Zibaldone (1898), containing 2,899 references to people, locations and literary works. This dataset was used to carry out reproducible experiments with both domain-specific BERT-based models and state-of-the-art LLMs such as LLaMa3.1. Results show that instruction-tuned models encounter multiple difficulties handling historical humanistic texts, while fine-tuned NER models offer more robust performance even with challenging entity types such as bibliographic references.
Enhancing Cell Counting through MLOps: A Structured Approach for Automated Cell Analysis
Apr 28, 2025Machine Learning (ML) models offer significant potential for advancing cell counting applications in neuroscience, medical research, pharmaceutical development, and environmental monitoring. However, implementing these models effectively requires robust operational frameworks. This paper introduces Cell Counting Machine Learning Operations (CC-MLOps), a comprehensive framework that streamlines the integration of ML in cell counting workflows. CC-MLOps encompasses data access and preprocessing, model training, monitoring, explainability features, and sustainability considerations. Through a practical use case, we demonstrate how MLOps principles can enhance model reliability, reduce human error, and enable scalable Cell Counting solutions. This work provides actionable guidance for researchers and laboratory professionals seeking to implement machine learning (ML)- powered cell counting systems.
AttackNet: Enhancing Biometric Security via Tailored Convolutional Neural Network Architectures for Liveness Detection
Feb 06, 2024Biometric security is the cornerstone of modern identity verification and authentication systems, where the integrity and reliability of biometric samples is of paramount importance. This paper introduces AttackNet, a bespoke Convolutional Neural Network architecture, meticulously designed to combat spoofing threats in biometric systems. Rooted in deep learning methodologies, this model offers a layered defense mechanism, seamlessly transitioning from low-level feature extraction to high-level pattern discernment. Three distinctive architectural phases form the crux of the model, each underpinned by judiciously chosen activation functions, normalization techniques, and dropout layers to ensure robustness and resilience against adversarial attacks. Benchmarking our model across diverse datasets affirms its prowess, showcasing superior performance metrics in comparison to contemporary models. Furthermore, a detailed comparative analysis accentuates the model's efficacy, drawing parallels with prevailing state-of-the-art methodologies. Through iterative refinement and an informed architectural strategy, AttackNet underscores the potential of deep learning in safeguarding the future of biometric security.
Embedding Non-Distortive Cancelable Face Template Generation
Feb 04, 2024Biometric authentication systems are crucial for security, but developing them involves various complexities, including privacy, security, and achieving high accuracy without directly storing pure biometric data in storage. We introduce an innovative image distortion technique that makes facial images unrecognizable to the eye but still identifiable by any custom embedding neural network model. Using the proposed approach, we test the reliability of biometric recognition networks by determining the maximum image distortion that does not change the predicted identity. Through experiments on MNIST and LFW datasets, we assess its effectiveness and compare it based on the traditional comparison metrics.
Cross-Database Liveness Detection: Insights from Comparative Biometric Analysis
Jan 29, 2024In an era where biometric security serves as a keystone of modern identity verification systems, ensuring the authenticity of these biometric samples is paramount. Liveness detection, the capability to differentiate between genuine and spoofed biometric samples, stands at the forefront of this challenge. This research presents a comprehensive evaluation of liveness detection models, with a particular focus on their performance in cross-database scenarios, a test paradigm notorious for its complexity and real-world relevance. Our study commenced by meticulously assessing models on individual datasets, revealing the nuances in their performance metrics. Delving into metrics such as the Half Total Error Rate, False Acceptance Rate, and False Rejection Rate, we unearthed invaluable insights into the models' strengths and weaknesses. Crucially, our exploration of cross-database testing provided a unique perspective, highlighting the chasm between training on one dataset and deploying on another. Comparative analysis with extant methodologies, ranging from convolutional networks to more intricate strategies, enriched our understanding of the current landscape. The variance in performance, even among state-of-the-art models, underscored the inherent challenges in this domain. In essence, this paper serves as both a repository of findings and a clarion call for more nuanced, data-diverse, and adaptable approaches in biometric liveness detection. In the dynamic dance between authenticity and deception, our work offers a blueprint for navigating the evolving rhythms of biometric security.
* Presented at SCIA 2023, Lviv, Ukraine, Nov. 2023
Unrecognizable Yet Identifiable: Image Distortion with Preserved Embeddings
Jan 26, 2024In the realm of security applications, biometric authentication systems play a crucial role, yet one often encounters challenges concerning privacy and security while developing one. One of the most fundamental challenges lies in avoiding storing biometrics directly in the storage but still achieving decently high accuracy. Addressing this issue, we contribute to both artificial intelligence and engineering fields. We introduce an innovative image distortion technique that effectively renders facial images unrecognizable to the eye while maintaining their identifiability by neural network models. From the theoretical perspective, we explore how reliable state-of-the-art biometrics recognition neural networks are by checking the maximal degree of image distortion, which leaves the predicted identity unchanged. On the other hand, applying this technique demonstrates a practical solution to the engineering challenge of balancing security, precision, and performance in biometric authentication systems. Through experimenting on the widely used datasets, we assess the effectiveness of our method in preserving AI feature representation and distorting relative to conventional metrics. We also compare our method with previously used approaches.
A Federated Learning Framework for Stenosis Detection
Oct 30, 2023This study explores the use of Federated Learning (FL) for stenosis detection in coronary angiography images (CA). Two heterogeneous datasets from two institutions were considered: Dataset 1 includes 1219 images from 200 patients, which we acquired at the Ospedale Riuniti of Ancona (Italy); Dataset 2 includes 7492 sequential images from 90 patients from a previous study available in the literature. Stenosis detection was performed by using a Faster R-CNN model. In our FL framework, only the weights of the model backbone were shared among the two client institutions, using Federated Averaging (FedAvg) for weight aggregation. We assessed the performance of stenosis detection using Precision (P rec), Recall (Rec), and F1 score (F1). Our results showed that the FL framework does not substantially affects clients 2 performance, which already achieved good performance with local training; for client 1, instead, FL framework increases the performance with respect to local model of +3.76%, +17.21% and +10.80%, respectively, reaching P rec = 73.56, Rec = 67.01 and F1 = 70.13. With such results, we showed that FL may enable multicentric studies relevant to automatic stenosis detection in CA by addressing data heterogeneity from various institutions, while preserving patient privacy.