 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHEad and neCK TumOR (HECKTOR) 2025: Benchmark of Segmentation, Diagnosis, and Prognosis in Multimodal PET/CT
Jun 18, 2026Head and neck cancers (HNC) represent a significant global health burden, with accurate tumor delineation being essential for effective radiotherapy planning. The complexity of the oropharyngeal anatomy, combined with the heterogeneous appearance of tumors on imaging, makes manual segmentation time-intensive and subject to inter-observer variability. Beyond segmentation, predicting long-term clinical outcomes, such as recurrence-free survival (RFS), and determining human papillomavirus (HPV) status from noninvasive imaging, remain challenging yet clinically valuable goals. The HECKTOR 2025 challenge addresses these needs by establishing a comprehensive benchmark for automated HNC analysis using multimodal PET/CT imaging and electronic health records. Building on previous editions (2020-2022), this challenge features an expanded multi-institutional dataset comprising over 1,100 patients from 10 centers worldwide. Participants were tasked with three complementary objectives: (1) segmenting primary gross tumor volumes (GTVp) and metastatic lymph nodes (GTVn), (2) predicting recurrence-free survival, and (3) classifying HPV status. The challenge attracted 35 registered teams, with 15 final submissions evaluated on a held-out test set. Top-performing algorithms achieved a mean Dice similarity coefficient of 0.75 for segmentation, a concordance index of 0.66 for survival prediction, and a balanced accuracy of 0.56 for HPV classification. This paper presents a comprehensive analysis of the submitted methodologies, evaluates their performance across different lesion characteristics, and discusses their implications for clinical translation in automated oncology workflows and decision support systems.
Towards Brain MRI Foundation Models for the Clinic: Findings from the FOMO25 Challenge
Apr 13, 2026Clinical deployment of automated brain MRI analysis faces a fundamental challenge: clinical data is heterogeneous and noisy, and high-quality labels are prohibitively costly to obtain. Self-supervised learning (SSL) can address this by leveraging the vast amounts of unlabeled data produced in clinical workflows to train robust \textit{foundation models} that adapt out-of-domain with minimal supervision. However, the development of foundation models for brain MRI has been limited by small pretraining datasets and in-domain benchmarking focused on high-quality, research-grade data. To address this gap, we organized the FOMO25 challenge as a satellite event at MICCAI 2025. FOMO25 provided participants with a large pretraining dataset, FOMO60K, and evaluated models on data sourced directly from clinical workflows in few-shot and out-of-domain settings. Tasks covered infarct classification, meningioma segmentation, and brain age regression, and considered both models trained on FOMO60K (method track) and any data (open track). Nineteen foundation models from sixteen teams were evaluated using a standardized containerized pipeline. Results show that (a) self-supervised pretraining improves generalization on clinical data under domain shift, with the strongest models trained \textit{out-of-domain} surpassing supervised baselines trained \textit{in-domain}. (b) No single pretraining objective benefits all tasks: MAE favors segmentation, hybrid reconstruction-contrastive objectives favor classification, and (c) strong performance was achieved by small pretrained models, and improvements from scaling model size and training duration did not yield reliable benefits.
Calibration and Uncertainty for multiRater Volume Assessment in multiorgan Segmentation (CURVAS) challenge results
May 13, 2025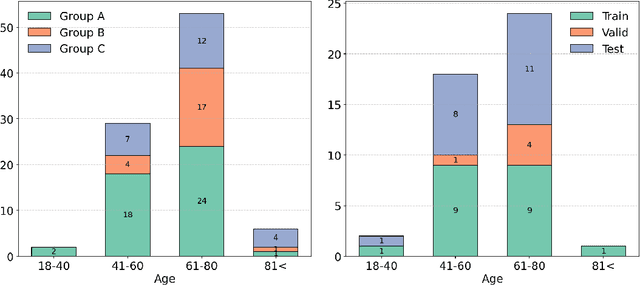
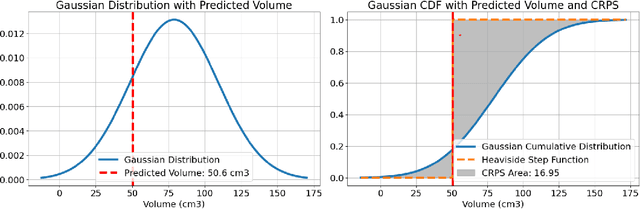

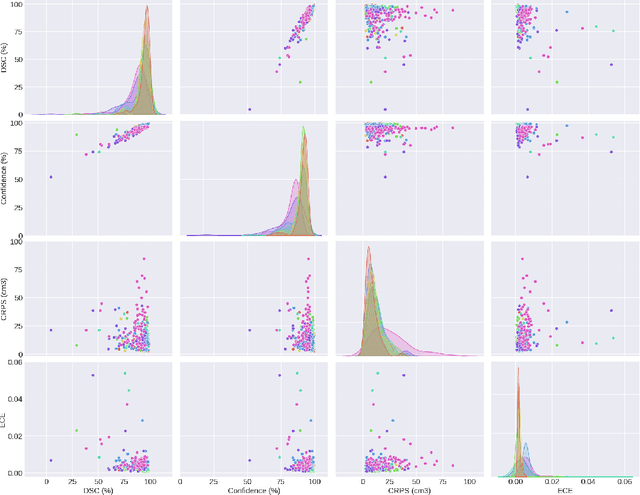
Deep learning (DL) has become the dominant approach for medical image segmentation, yet ensuring the reliability and clinical applicability of these models requires addressing key challenges such as annotation variability, calibration, and uncertainty estimation. This is why we created the Calibration and Uncertainty for multiRater Volume Assessment in multiorgan Segmentation (CURVAS), which highlights the critical role of multiple annotators in establishing a more comprehensive ground truth, emphasizing that segmentation is inherently subjective and that leveraging inter-annotator variability is essential for robust model evaluation. Seven teams participated in the challenge, submitting a variety of DL models evaluated using metrics such as Dice Similarity Coefficient (DSC), Expected Calibration Error (ECE), and Continuous Ranked Probability Score (CRPS). By incorporating consensus and dissensus ground truth, we assess how DL models handle uncertainty and whether their confidence estimates align with true segmentation performance. Our findings reinforce the importance of well-calibrated models, as better calibration is strongly correlated with the quality of the results. Furthermore, we demonstrate that segmentation models trained on diverse datasets and enriched with pre-trained knowledge exhibit greater robustness, particularly in cases deviating from standard anatomical structures. Notably, the best-performing models achieved high DSC and well-calibrated uncertainty estimates. This work underscores the need for multi-annotator ground truth, thorough calibration assessments, and uncertainty-aware evaluations to develop trustworthy and clinically reliable DL-based medical image segmentation models.
Advances in Automated Fetal Brain MRI Segmentation and Biometry: Insights from the FeTA 2024 Challenge
May 05, 2025



Accurate fetal brain tissue segmentation and biometric analysis are essential for studying brain development in utero. The FeTA Challenge 2024 advanced automated fetal brain MRI analysis by introducing biometry prediction as a new task alongside tissue segmentation. For the first time, our diverse multi-centric test set included data from a new low-field (0.55T) MRI dataset. Evaluation metrics were also expanded to include the topology-specific Euler characteristic difference (ED). Sixteen teams submitted segmentation methods, most of which performed consistently across both high- and low-field scans. However, longitudinal trends indicate that segmentation accuracy may be reaching a plateau, with results now approaching inter-rater variability. The ED metric uncovered topological differences that were missed by conventional metrics, while the low-field dataset achieved the highest segmentation scores, highlighting the potential of affordable imaging systems when paired with high-quality reconstruction. Seven teams participated in the biometry task, but most methods failed to outperform a simple baseline that predicted measurements based solely on gestational age, underscoring the challenge of extracting reliable biometric estimates from image data alone. Domain shift analysis identified image quality as the most significant factor affecting model generalization, with super-resolution pipelines also playing a substantial role. Other factors, such as gestational age, pathology, and acquisition site, had smaller, though still measurable, effects. Overall, FeTA 2024 offers a comprehensive benchmark for multi-class segmentation and biometry estimation in fetal brain MRI, underscoring the need for data-centric approaches, improved topological evaluation, and greater dataset diversity to enable clinically robust and generalizable AI tools.
Foundation Model for Whole-Heart Segmentation: Leveraging Student-Teacher Learning in Multi-Modal Medical Imaging
Mar 24, 2025



Whole-heart segmentation from CT and MRI scans is crucial for cardiovascular disease analysis, yet existing methods struggle with modality-specific biases and the need for extensive labeled datasets. To address these challenges, we propose a foundation model for whole-heart segmentation using a self-supervised learning (SSL) framework based on a student-teacher architecture. Our model is pretrained on a large, unlabeled dataset of CT and MRI scans, leveraging the xLSTM backbone to capture long-range spatial dependencies and complex anatomical structures in 3D medical images. By incorporating multi-modal pretraining, our approach ensures strong generalization across both CT and MRI modalities, mitigating modality-specific variations and improving segmentation accuracy in diverse clinical settings. The use of large-scale unlabeled data significantly reduces the dependency on manual annotations, enabling robust performance even with limited labeled data. We further introduce an xLSTM-UNet-based architecture for downstream whole-heart segmentation tasks, demonstrating its effectiveness on few-label CT and MRI datasets. Our results validate the robustness and adaptability of the proposed model, highlighting its potential for advancing automated whole-heart segmentation in medical imaging.
Multi-Class Segmentation of Aortic Branches and Zones in Computed Tomography Angiography: The AortaSeg24 Challenge
Feb 07, 2025



Multi-class segmentation of the aorta in computed tomography angiography (CTA) scans is essential for diagnosing and planning complex endovascular treatments for patients with aortic dissections. However, existing methods reduce aortic segmentation to a binary problem, limiting their ability to measure diameters across different branches and zones. Furthermore, no open-source dataset is currently available to support the development of multi-class aortic segmentation methods. To address this gap, we organized the AortaSeg24 MICCAI Challenge, introducing the first dataset of 100 CTA volumes annotated for 23 clinically relevant aortic branches and zones. This dataset was designed to facilitate both model development and validation. The challenge attracted 121 teams worldwide, with participants leveraging state-of-the-art frameworks such as nnU-Net and exploring novel techniques, including cascaded models, data augmentation strategies, and custom loss functions. We evaluated the submitted algorithms using the Dice Similarity Coefficient (DSC) and Normalized Surface Distance (NSD), highlighting the approaches adopted by the top five performing teams. This paper presents the challenge design, dataset details, evaluation metrics, and an in-depth analysis of the top-performing algorithms. The annotated dataset, evaluation code, and implementations of the leading methods are publicly available to support further research. All resources can be accessed at https://aortaseg24.grand-challenge.org.
Tumor Detection, Segmentation and Classification Challenge on Automated 3D Breast Ultrasound: The TDSC-ABUS Challenge
Jan 26, 2025



Breast cancer is one of the most common causes of death among women worldwide. Early detection helps in reducing the number of deaths. Automated 3D Breast Ultrasound (ABUS) is a newer approach for breast screening, which has many advantages over handheld mammography such as safety, speed, and higher detection rate of breast cancer. Tumor detection, segmentation, and classification are key components in the analysis of medical images, especially challenging in the context of 3D ABUS due to the significant variability in tumor size and shape, unclear tumor boundaries, and a low signal-to-noise ratio. The lack of publicly accessible, well-labeled ABUS datasets further hinders the advancement of systems for breast tumor analysis. Addressing this gap, we have organized the inaugural Tumor Detection, Segmentation, and Classification Challenge on Automated 3D Breast Ultrasound 2023 (TDSC-ABUS2023). This initiative aims to spearhead research in this field and create a definitive benchmark for tasks associated with 3D ABUS image analysis. In this paper, we summarize the top-performing algorithms from the challenge and provide critical analysis for ABUS image examination. We offer the TDSC-ABUS challenge as an open-access platform at https://tdsc-abus2023.grand-challenge.org/ to benchmark and inspire future developments in algorithmic research.
SMILE-UHURA Challenge -- Small Vessel Segmentation at Mesoscopic Scale from Ultra-High Resolution 7T Magnetic Resonance Angiograms
Nov 14, 2024The human brain receives nutrients and oxygen through an intricate network of blood vessels. Pathology affecting small vessels, at the mesoscopic scale, represents a critical vulnerability within the cerebral blood supply and can lead to severe conditions, such as Cerebral Small Vessel Diseases. The advent of 7 Tesla MRI systems has enabled the acquisition of higher spatial resolution images, making it possible to visualise such vessels in the brain. However, the lack of publicly available annotated datasets has impeded the development of robust, machine learning-driven segmentation algorithms. To address this, the SMILE-UHURA challenge was organised. This challenge, held in conjunction with the ISBI 2023, in Cartagena de Indias, Colombia, aimed to provide a platform for researchers working on related topics. The SMILE-UHURA challenge addresses the gap in publicly available annotated datasets by providing an annotated dataset of Time-of-Flight angiography acquired with 7T MRI. This dataset was created through a combination of automated pre-segmentation and extensive manual refinement. In this manuscript, sixteen submitted methods and two baseline methods are compared both quantitatively and qualitatively on two different datasets: held-out test MRAs from the same dataset as the training data (with labels kept secret) and a separate 7T ToF MRA dataset where both input volumes and labels are kept secret. The results demonstrate that most of the submitted deep learning methods, trained on the provided training dataset, achieved reliable segmentation performance. Dice scores reached up to 0.838 $\pm$ 0.066 and 0.716 $\pm$ 0.125 on the respective datasets, with an average performance of up to 0.804 $\pm$ 0.15.
PitVis-2023 Challenge: Workflow Recognition in videos of Endoscopic Pituitary Surgery
Sep 02, 2024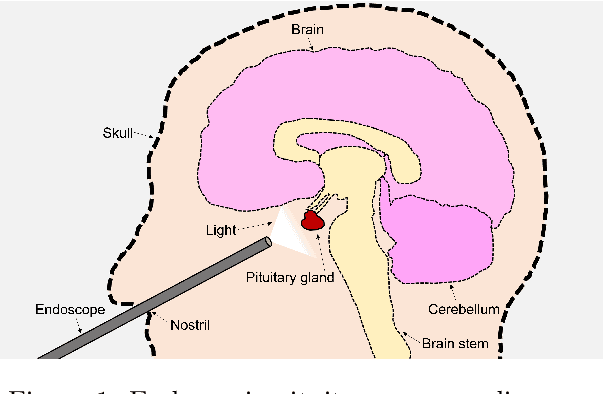

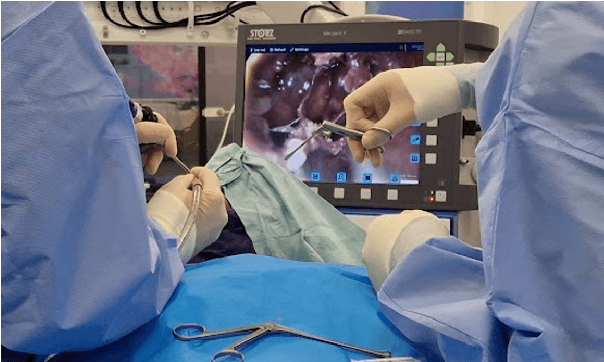
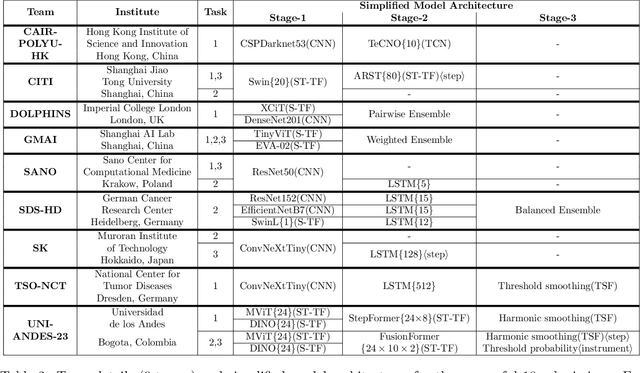
The field of computer vision applied to videos of minimally invasive surgery is ever-growing. Workflow recognition pertains to the automated recognition of various aspects of a surgery: including which surgical steps are performed; and which surgical instruments are used. This information can later be used to assist clinicians when learning the surgery; during live surgery; and when writing operation notes. The Pituitary Vision (PitVis) 2023 Challenge tasks the community to step and instrument recognition in videos of endoscopic pituitary surgery. This is a unique task when compared to other minimally invasive surgeries due to the smaller working space, which limits and distorts vision; and higher frequency of instrument and step switching, which requires more precise model predictions. Participants were provided with 25-videos, with results presented at the MICCAI-2023 conference as part of the Endoscopic Vision 2023 Challenge in Vancouver, Canada, on 08-Oct-2023. There were 18-submissions from 9-teams across 6-countries, using a variety of deep learning models. A commonality between the top performing models was incorporating spatio-temporal and multi-task methods, with greater than 50% and 10% macro-F1-score improvement over purely spacial single-task models in step and instrument recognition respectively. The PitVis-2023 Challenge therefore demonstrates state-of-the-art computer vision models in minimally invasive surgery are transferable to a new dataset, with surgery specific techniques used to enhance performance, progressing the field further. Benchmark results are provided in the paper, and the dataset is publicly available at: https://doi.org/10.5522/04/26531686.
Region Guided Attention Network for Retinal Vessel Segmentation
Jul 22, 2024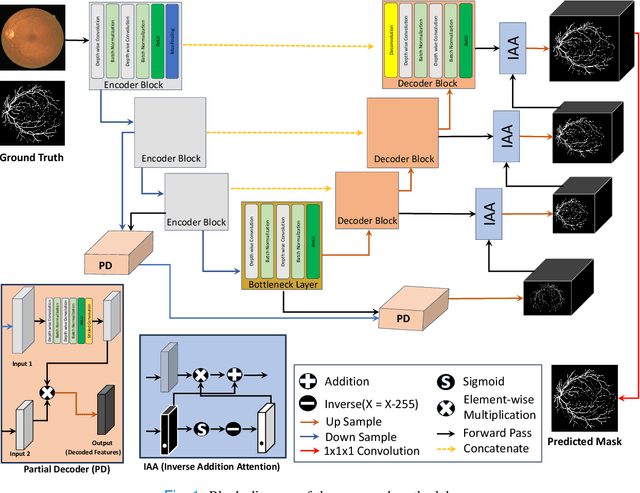
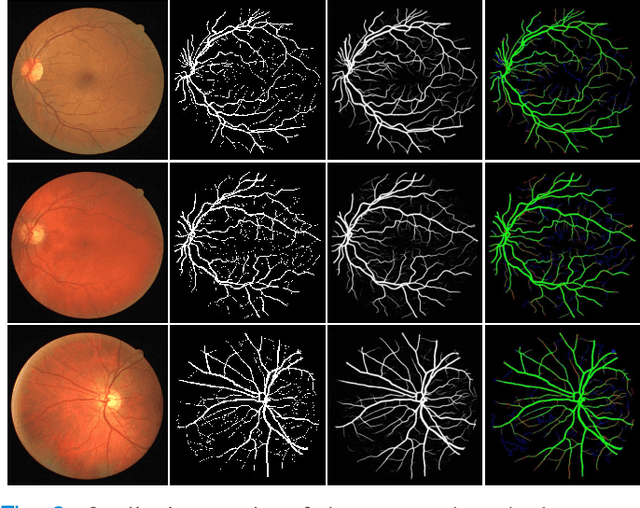
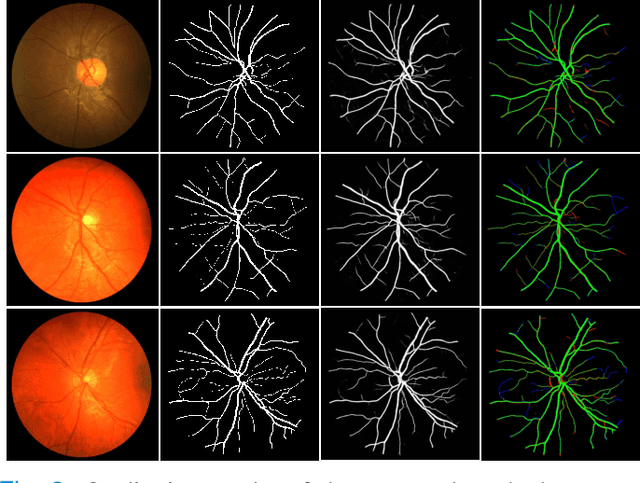
Retinal imaging has emerged as a promising method of addressing this challenge, taking advantage of the unique structure of the retina. The retina is an embryonic extension of the central nervous system, providing a direct in vivo window into neurological health. Recent studies have shown that specific structural changes in retinal vessels can not only serve as early indicators of various diseases but also help to understand disease progression. In this work, we present a lightweight retinal vessel segmentation network based on the encoder-decoder mechanism with region-guided attention. We introduce inverse addition attention blocks with region guided attention to focus on the foreground regions and improve the segmentation of regions of interest. To further boost the model's performance on retinal vessel segmentation, we employ a weighted dice loss. This choice is particularly effective in addressing the class imbalance issues frequently encountered in retinal vessel segmentation tasks. Dice loss penalises false positives and false negatives equally, encouraging the model to generate more accurate segmentation with improved object boundary delineation and reduced fragmentation. Extensive experiments on a benchmark dataset show better performance (0.8285, 0.8098, 0.9677, and 0.8166 recall, precision, accuracy and F1 score respectively) compared to state-of-the-art methods.