 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDARES: Depth Anything in Robotic Endoscopic Surgery with Self-supervised Vector-LoRA of the Foundation Model
Aug 30, 2024



Robotic-assisted surgery (RAS) relies on accurate depth estimation for 3D reconstruction and visualization. While foundation models like Depth Anything Models (DAM) show promise, directly applying them to surgery often yields suboptimal results. Fully fine-tuning on limited surgical data can cause overfitting and catastrophic forgetting, compromising model robustness and generalization. Although Low-Rank Adaptation (LoRA) addresses some adaptation issues, its uniform parameter distribution neglects the inherent feature hierarchy, where earlier layers, learning more general features, require more parameters than later ones. To tackle this issue, we introduce Depth Anything in Robotic Endoscopic Surgery (DARES), a novel approach that employs a new adaptation technique, Vector Low-Rank Adaptation (Vector-LoRA) on the DAM V2 to perform self-supervised monocular depth estimation in RAS scenes. To enhance learning efficiency, we introduce Vector-LoRA by integrating more parameters in earlier layers and gradually decreasing parameters in later layers. We also design a reprojection loss based on the multi-scale SSIM error to enhance depth perception by better tailoring the foundation model to the specific requirements of the surgical environment. The proposed method is validated on the SCARED dataset and demonstrates superior performance over recent state-of-the-art self-supervised monocular depth estimation techniques, achieving an improvement of 13.3% in the absolute relative error metric. The code and pre-trained weights are available at https://github.com/mobarakol/DARES.
Development and evaluation of intraoperative ultrasound segmentation with negative image frames and multiple observer labels
Jul 28, 2021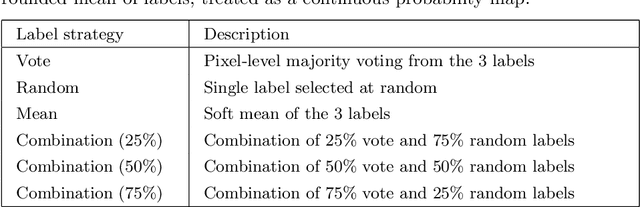
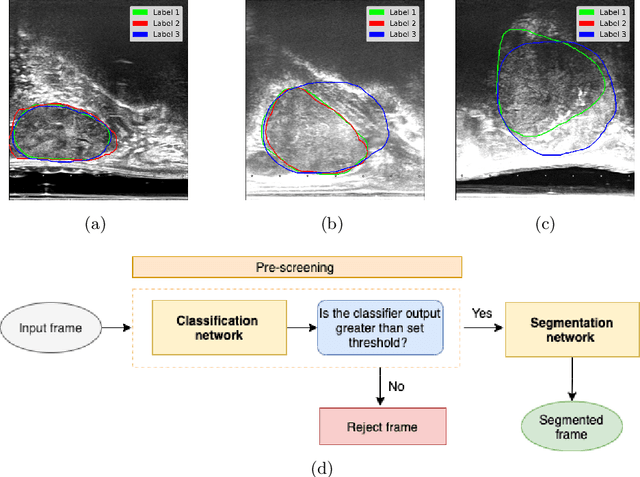
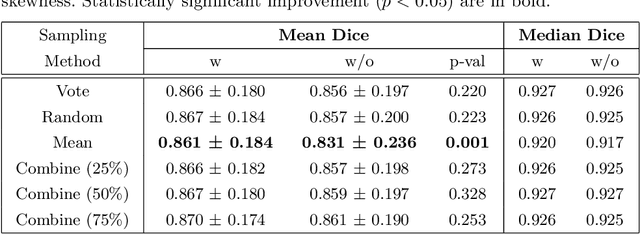
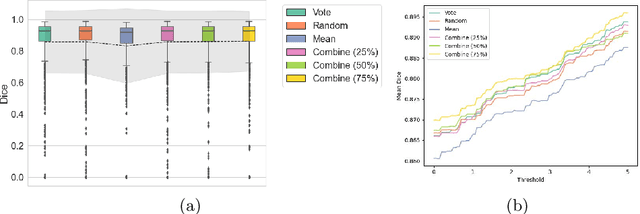
When developing deep neural networks for segmenting intraoperative ultrasound images, several practical issues are encountered frequently, such as the presence of ultrasound frames that do not contain regions of interest and the high variance in ground-truth labels. In this study, we evaluate the utility of a pre-screening classification network prior to the segmentation network. Experimental results demonstrate that such a classifier, minimising frame classification errors, was able to directly impact the number of false positive and false negative frames. Importantly, the segmentation accuracy on the classifier-selected frames, that would be segmented, remains comparable to or better than those from standalone segmentation networks. Interestingly, the efficacy of the pre-screening classifier was affected by the sampling methods for training labels from multiple observers, a seemingly independent problem. We show experimentally that a previously proposed approach, combining random sampling and consensus labels, may need to be adapted to perform well in our application. Furthermore, this work aims to share practical experience in developing a machine learning application that assists highly variable interventional imaging for prostate cancer patients, to present robust and reproducible open-source implementations, and to report a set of comprehensive results and analysis comparing these practical, yet important, options in a real-world clinical application.