 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMPFlow: Multi-modal Posterior-Guided Flow Matching for Zero-Shot MRI Reconstruction
Mar 04, 2026Zero-shot MRI reconstruction relies on generative priors, but single-modality unconditional priors produce hallucinations under severe ill-posedness. In many clinical workflows, complementary MRI acquisitions (e.g. high-quality structural scans) are routinely available, yet existing reconstruction methods lack mechanisms to leverage this additional information. We propose MPFlow, a zero-shot multi-modal reconstruction framework built on rectified flow that incorporates auxiliary MRI modalities at inference time without retraining the generative prior to improve anatomical fidelity. Cross-modal guidance is enabled by our proposed self-supervised pretraining strategy, Patch-level Multi-modal MR Image Pretraining (PAMRI), which learns shared representations across modalities. Sampling is jointly guided by data consistency and cross-modal feature alignment using pre-trained PAMRI, systematically suppressing intrinsic and extrinsic hallucinations. Extensive experiments on HCP and BraTS show that MPFlow matches diffusion baselines on image quality using only 20% of sampling steps while reducing tumor hallucinations by more than 15% (segmentation dice score). This demonstrates that cross-modal guidance enables more reliable and efficient zero-shot MRI reconstruction.
Tackling Hallucination from Conditional Models for Medical Image Reconstruction with DynamicDPS
Mar 03, 2025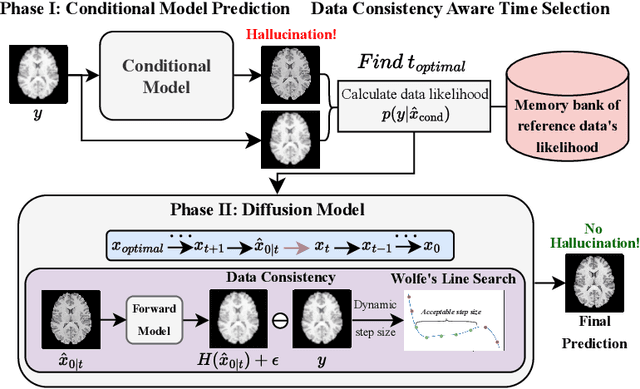
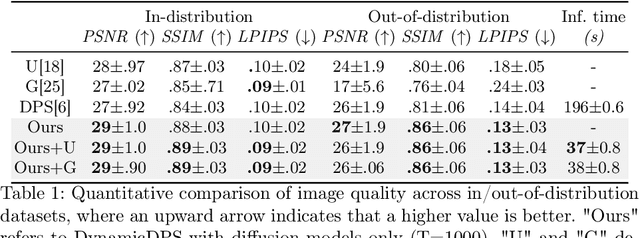
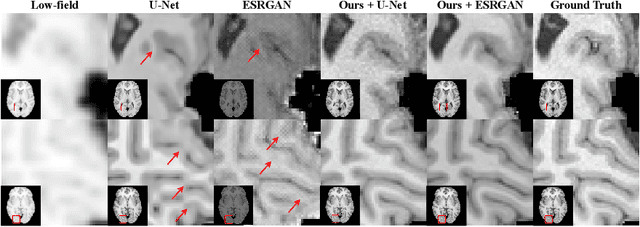
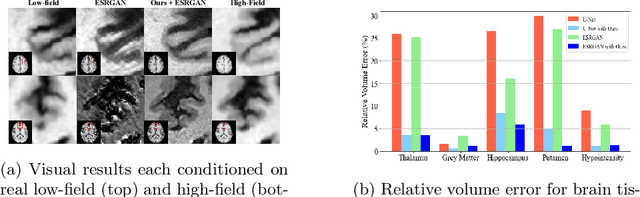
Hallucinations are spurious structures not present in the ground truth, posing a critical challenge in medical image reconstruction, especially for data-driven conditional models. We hypothesize that combining an unconditional diffusion model with data consistency, trained on a diverse dataset, can reduce these hallucinations. Based on this, we propose DynamicDPS, a diffusion-based framework that integrates conditional and unconditional diffusion models to enhance low-quality medical images while systematically reducing hallucinations. Our approach first generates an initial reconstruction using a conditional model, then refines it with an adaptive diffusion-based inverse problem solver. DynamicDPS skips early stage in the reverse process by selecting an optimal starting time point per sample and applies Wolfe's line search for adaptive step sizes, improving both efficiency and image fidelity. Using diffusion priors and data consistency, our method effectively reduces hallucinations from any conditional model output. We validate its effectiveness in Image Quality Transfer for low-field MRI enhancement. Extensive evaluations on synthetic and real MR scans, including a downstream task for tissue volume estimation, show that DynamicDPS reduces hallucinations, improving relative volume estimation by over 15% for critical tissues while using only 5% of the sampling steps required by baseline diffusion models. As a model-agnostic and fine-tuning-free approach, DynamicDPS offers a robust solution for hallucination reduction in medical imaging. The code will be made publicly available upon publication.
DARES: Depth Anything in Robotic Endoscopic Surgery with Self-supervised Vector-LoRA of the Foundation Model
Aug 30, 2024



Robotic-assisted surgery (RAS) relies on accurate depth estimation for 3D reconstruction and visualization. While foundation models like Depth Anything Models (DAM) show promise, directly applying them to surgery often yields suboptimal results. Fully fine-tuning on limited surgical data can cause overfitting and catastrophic forgetting, compromising model robustness and generalization. Although Low-Rank Adaptation (LoRA) addresses some adaptation issues, its uniform parameter distribution neglects the inherent feature hierarchy, where earlier layers, learning more general features, require more parameters than later ones. To tackle this issue, we introduce Depth Anything in Robotic Endoscopic Surgery (DARES), a novel approach that employs a new adaptation technique, Vector Low-Rank Adaptation (Vector-LoRA) on the DAM V2 to perform self-supervised monocular depth estimation in RAS scenes. To enhance learning efficiency, we introduce Vector-LoRA by integrating more parameters in earlier layers and gradually decreasing parameters in later layers. We also design a reprojection loss based on the multi-scale SSIM error to enhance depth perception by better tailoring the foundation model to the specific requirements of the surgical environment. The proposed method is validated on the SCARED dataset and demonstrates superior performance over recent state-of-the-art self-supervised monocular depth estimation techniques, achieving an improvement of 13.3% in the absolute relative error metric. The code and pre-trained weights are available at https://github.com/mobarakol/DARES.
Tackling Structural Hallucination in Image Translation with Local Diffusion
Apr 13, 2024



Recent developments in diffusion models have advanced conditioned image generation, yet they struggle with reconstructing out-of-distribution (OOD) images, such as unseen tumors in medical images, causing ``image hallucination'' and risking misdiagnosis. We hypothesize such hallucinations result from local OOD regions in the conditional images. We verify that partitioning the OOD region and conducting separate image generations alleviates hallucinations in several applications. From this, we propose a training-free diffusion framework that reduces hallucination with multiple Local Diffusion processes. Our approach involves OOD estimation followed by two modules: a ``branching'' module generates locally both within and outside OOD regions, and a ``fusion'' module integrates these predictions into one. Our evaluation shows our method mitigates hallucination over baseline models quantitatively and qualitatively, reducing misdiagnosis by 40% and 25% in the real-world medical and natural image datasets, respectively. It also demonstrates compatibility with various pre-trained diffusion models.
A 3D Conditional Diffusion Model for Image Quality Transfer -- An Application to Low-Field MRI
Nov 11, 2023



Low-field (LF) MRI scanners (<1T) are still prevalent in settings with limited resources or unreliable power supply. However, they often yield images with lower spatial resolution and contrast than high-field (HF) scanners. This quality disparity can result in inaccurate clinician interpretations. Image Quality Transfer (IQT) has been developed to enhance the quality of images by learning a mapping function between low and high-quality images. Existing IQT models often fail to restore high-frequency features, leading to blurry output. In this paper, we propose a 3D conditional diffusion model to improve 3D volumetric data, specifically LF MR images. Additionally, we incorporate a cross-batch mechanism into the self-attention and padding of our network, ensuring broader contextual awareness even under small 3D patches. Experiments on the publicly available Human Connectome Project (HCP) dataset for IQT and brain parcellation demonstrate that our model outperforms existing methods both quantitatively and qualitatively. The code is publicly available at \url{https://github.com/edshkim98/DiffusionIQT}.