 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoRefine: Confidence-Guided Self-Refinement for Adaptive Test-Time Compute
Feb 09, 2026Large Language Models (LLMs) often rely on test-time scaling via parallel decoding (for example, 512 samples) to boost reasoning accuracy, but this incurs substantial compute. We introduce CoRefine, a confidence-guided self-refinement method that achieves competitive accuracy using a fraction of the tokens via a lightweight 211k-parameter Conv1D controller atop a frozen LLM. The controller consumes full-trace confidence to decide whether to halt, re-examine, or try a different approach, enabling targeted self-correction with an average of 2.7 refinement steps per problem and roughly 190-fold token reduction relative to 512-sample baselines. Across diverse reasoning benchmarks and three open-source models, the controller achieves 92.6 percent precision when it confidently halts, indicating that confidence dynamics reliably signal correctness without ground-truth verification. We extend this to CoRefine-Tree, a hybrid sequential-parallel variant that adaptively balances exploration and exploitation, with easy serving integration and verifier compatibility. By treating confidence as a control signal rather than a correctness guarantee, CoRefine provides a modular primitive for scalable reasoning and agentic settings with imperfect verifiers.
Segment Anyword: Mask Prompt Inversion for Open-Set Grounded Segmentation
May 23, 2025Open-set image segmentation poses a significant challenge because existing methods often demand extensive training or fine-tuning and generally struggle to segment unified objects consistently across diverse text reference expressions. Motivated by this, we propose Segment Anyword, a novel training-free visual concept prompt learning approach for open-set language grounded segmentation that relies on token-level cross-attention maps from a frozen diffusion model to produce segmentation surrogates or mask prompts, which are then refined into targeted object masks. Initial prompts typically lack coherence and consistency as the complexity of the image-text increases, resulting in suboptimal mask fragments. To tackle this issue, we further introduce a novel linguistic-guided visual prompt regularization that binds and clusters visual prompts based on sentence dependency and syntactic structural information, enabling the extraction of robust, noise-tolerant mask prompts, and significant improvements in segmentation accuracy. The proposed approach is effective, generalizes across different open-set segmentation tasks, and achieves state-of-the-art results of 52.5 (+6.8 relative) mIoU on Pascal Context 59, 67.73 (+25.73 relative) cIoU on gRefCOCO, and 67.4 (+1.1 relative to fine-tuned methods) mIoU on GranDf, which is the most complex open-set grounded segmentation task in the field.
DeCoRe: Decoding by Contrasting Retrieval Heads to Mitigate Hallucinations
Oct 24, 2024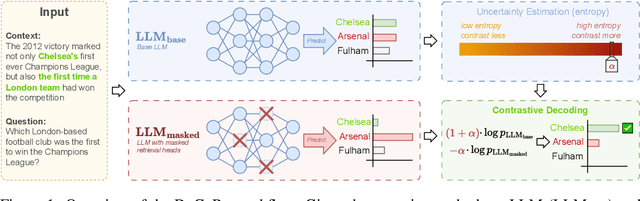
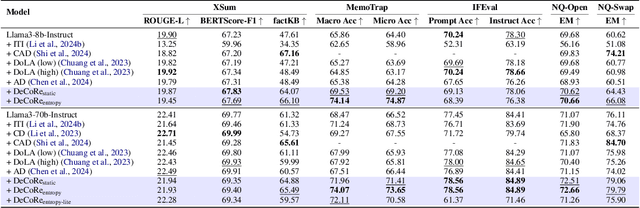
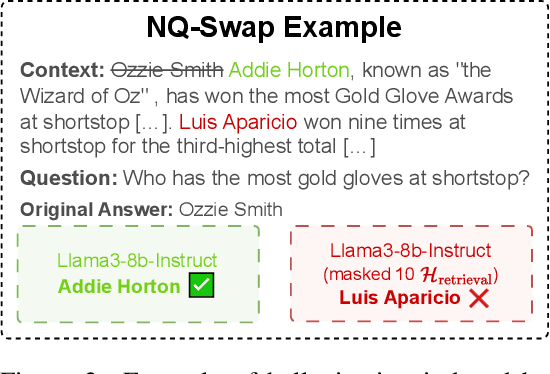

Large Language Models (LLMs) often hallucinate, producing unfaithful or factually incorrect outputs by misrepresenting the provided context or incorrectly recalling internal knowledge. Recent studies have identified specific attention heads within the Transformer architecture, known as retrieval heads, responsible for extracting relevant contextual information. We hypothesise that masking these retrieval heads can induce hallucinations and that contrasting the outputs of the base LLM and the masked LLM can reduce hallucinations. To this end, we propose Decoding by Contrasting Retrieval Heads (DeCoRe), a novel training-free decoding strategy that amplifies information found in the context and model parameters. DeCoRe mitigates potentially hallucinated responses by dynamically contrasting the outputs of the base LLM and the masked LLM, using conditional entropy as a guide. Our extensive experiments confirm that DeCoRe significantly improves performance on tasks requiring high contextual faithfulness, such as summarisation (XSum by 18.6%), instruction following (MemoTrap by 10.9%), and open-book question answering (NQ-Open by 2.4% and NQ-Swap by 5.5%).
Tackling Structural Hallucination in Image Translation with Local Diffusion
Apr 13, 2024



Recent developments in diffusion models have advanced conditioned image generation, yet they struggle with reconstructing out-of-distribution (OOD) images, such as unseen tumors in medical images, causing ``image hallucination'' and risking misdiagnosis. We hypothesize such hallucinations result from local OOD regions in the conditional images. We verify that partitioning the OOD region and conducting separate image generations alleviates hallucinations in several applications. From this, we propose a training-free diffusion framework that reduces hallucination with multiple Local Diffusion processes. Our approach involves OOD estimation followed by two modules: a ``branching'' module generates locally both within and outside OOD regions, and a ``fusion'' module integrates these predictions into one. Our evaluation shows our method mitigates hallucination over baseline models quantitatively and qualitatively, reducing misdiagnosis by 40% and 25% in the real-world medical and natural image datasets, respectively. It also demonstrates compatibility with various pre-trained diffusion models.
An Image is Worth Multiple Words: Learning Object Level Concepts using Multi-Concept Prompt Learning
Oct 18, 2023Textural Inversion, a prompt learning method, learns a singular embedding for a new "word" to represent image style and appearance, allowing it to be integrated into natural language sentences to generate novel synthesised images. However, identifying and integrating multiple object-level concepts within one scene poses significant challenges even when embeddings for individual concepts are attainable. This is further confirmed by our empirical tests. To address this challenge, we introduce a framework for Multi-Concept Prompt Learning (MCPL), where multiple new "words" are simultaneously learned from a single sentence-image pair. To enhance the accuracy of word-concept correlation, we propose three regularisation techniques: Attention Masking (AttnMask) to concentrate learning on relevant areas; Prompts Contrastive Loss (PromptCL) to separate the embeddings of different concepts; and Bind adjective (Bind adj.) to associate new "words" with known words. We evaluate via image generation, editing, and attention visualisation with diverse images. Extensive quantitative comparisons demonstrate that our method can learn more semantically disentangled concepts with enhanced word-concept correlation. Additionally, we introduce a novel dataset and evaluation protocol tailored for this new task of learning object-level concepts.
Unlocking the Heart Using Adaptive Locked Agnostic Networks
Sep 21, 2023

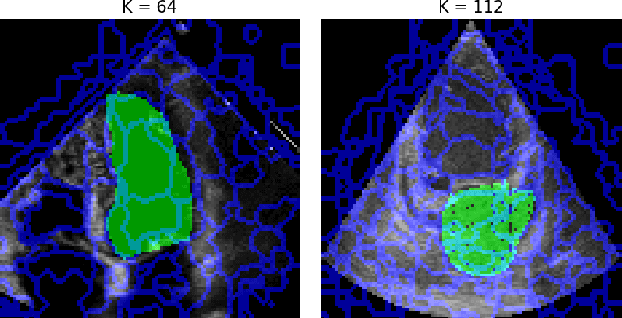

Supervised training of deep learning models for medical imaging applications requires a significant amount of labeled data. This is posing a challenge as the images are required to be annotated by medical professionals. To address this limitation, we introduce the Adaptive Locked Agnostic Network (ALAN), a concept involving self-supervised visual feature extraction using a large backbone model to produce anatomically robust semantic self-segmentation. In the ALAN methodology, this self-supervised training occurs only once on a large and diverse dataset. Due to the intuitive interpretability of the segmentation, downstream models tailored for specific tasks can be easily designed using white-box models with few parameters. This, in turn, opens up the possibility of communicating the inner workings of a model with domain experts and introducing prior knowledge into it. It also means that the downstream models become less data-hungry compared to fully supervised approaches. These characteristics make ALAN particularly well-suited for resource-scarce scenarios, such as costly clinical trials and rare diseases. In this paper, we apply the ALAN approach to three publicly available echocardiography datasets: EchoNet-Dynamic, CAMUS, and TMED-2. Our findings demonstrate that the self-supervised backbone model robustly identifies anatomical subregions of the heart in an apical four-chamber view. Building upon this, we design two downstream models, one for segmenting a target anatomical region, and a second for echocardiogram view classification.
Classification of datasets with imputed missing values: does imputation quality matter?
Jun 16, 2022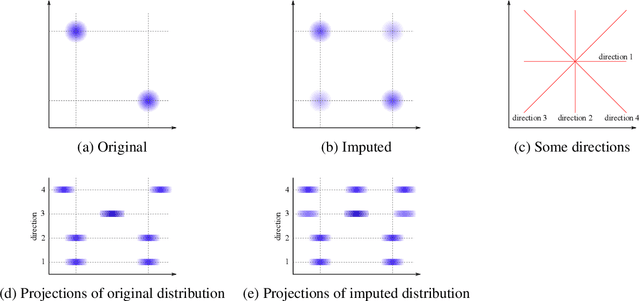


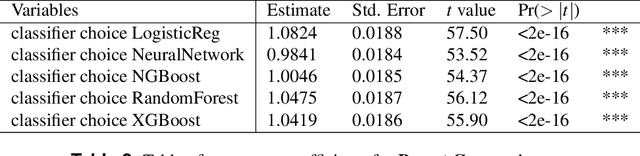
Classifying samples in incomplete datasets is a common aim for machine learning practitioners, but is non-trivial. Missing data is found in most real-world datasets and these missing values are typically imputed using established methods, followed by classification of the now complete, imputed, samples. The focus of the machine learning researcher is then to optimise the downstream classification performance. In this study, we highlight that it is imperative to consider the quality of the imputation. We demonstrate how the commonly used measures for assessing quality are flawed and propose a new class of discrepancy scores which focus on how well the method recreates the overall distribution of the data. To conclude, we highlight the compromised interpretability of classifier models trained using poorly imputed data.